基于深度学习实例分割的票据图像文本检测方法与流程
本发明涉及图像处理技术领域,特别涉及一种基于深度学习实例分割的票据图像文本检测方法。
背景技术:
近几年,ai技术的发展突飞猛进,其应用领域也越来越广,如机器人、语音识别、图像识别、计算机视觉、自动驾驶等领域。在图像识别方面,基于深度学习的ocr识别以其识别精度高、识别速度快等优点被业界广泛采用。众所周知,ocr技术一般分为文本检测和文本识别两个技术分支,虽然近期也有推出基于神经网络的端到端ocr识别,但其在特定场景下的效果还不理想。因此,主流的ocr识别技术还是分为文本检测和文本识别两个方向。而在票据识别方面,受实际业务需求的影响,可能还要对识别结果进行字段匹配,比如将票据金额、票据号码等从识别结果中提取出来,并给出该字段在原图中对应的位置信息。一般的方法是在文字检测及识别流程完成之后,根据检测到的文本图像位置及文本识别内容进行后处理匹配,这种方法需要编写复杂的后处理逻辑,并且若票面结构复杂、各字段内容详尽的话,匹配的精度难以保证。
如果能在文本检测阶段直接对票据中的各个字段同时进行分类则能很大程度上对以上问题进行改善,结合当前相关技术的发展现状,我们可以采用目标检测(objectiondetection)的方法和实例分割(instancesegmentation)的方法,而考虑到票据图像中可能存在不规则文本区域,本发明中即采用基于实例分割的方法来解决上述问题。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供一种基于深度学习实例分割的票据图像文本检测方法,可以精确检测票据中的文本区域图像,并给出文本图像的类别信息,将检测结果送入识别模型结合该文本的分类信息,经过简单的后处理操作即可得到格式化之后的票据识别结果,极大的简化了票据识别的后处理流程,提高了开发效率。
为了达到上述的技术效果,本发明采取以下技术方案:
基于深度学习实例分割的票据图像文本检测方法,包括步骤:
a.收集训练数据进行人工标注数据及自动生成虚拟票据训练数据;为有效的训练神经网络,需要大量的标注数据,而人工标注数据将耗费大量时间,因此,为了保证标注数据的质量并尽量减少标注成本,本发明结合了上述两种训练数据生成方式;
b.网络模型结构及网络参数与训练参数设置;
c.模型训练;分为两阶段实现,第一阶段使用自动生成的虚拟票据训练数据对模型进行训练并保存训练模型权重,第二阶段采用在收集的真实训练数据上进行模型微调以提高模型在真实票据上的泛化性能;
d.模型部署及预测,用训练好的模型对各个类别的票据图片进行文本实例分割,得到各个字段的位置信息及类别信息。
进一步地,所述步骤a包括:
a1.标注数据准备;
a2.虚拟票据生成;
a3.训练数据划分及数据格式转换。
进一步地,所述步骤a1包括:收集不同类别的待标注票据图片,定义各个字段的类别名称,其中,若某个字段在票据图片中有多行,则将该字段的每行分别标注为不同的类别名称加以区别。
进一步地,所述步骤a1中使用的标注工具为via,实际中,也可选用其他标注工具。
进一步地,所述步骤a2包括:
a2.1.整理各个类别票据数据的语料信息;
a2.2.针对各个类别票据图片确定一张模板图片,将该模板图片中各字段的内容抹除,并记录各个字段在模板图片中的初始像素位置;
a2.3.编码实现从对应类别的票据语料库中随机抽取各个字段的文本信息画到模板图片对应位置上;
a2.4.对生成的票据图像做高斯模糊、加入随机噪声,同时将生成图像中各个字段的像素位置及类别信息写入标签文件。
进一步地,所述步骤a3中具体是将人工标注数据和计算机生成的虚拟票据数据的标签分别转换成coco数据格式。
进一步地,所述网络模型结构与cascademaskrcnn的网络结构相同,具体采用hrnet作为基础的特征提取模块,采用hrfpn作为语义分割模块。
进一步地,所述步骤c包括:
c1.模型参数初始化,设定初始训练轮数epoch1及微调轮数epoch2,初始化当前轮数epoch为0;
c2.将自动生成虚拟票据训练数据作为第一阶段数据并划分为第一训练集、第一测试集并加载相应数据;
c3.判断当前epoch是否小于epoch1,若是则转步骤c4;否则进入步骤c7;
c4.从第一训练集中取batch-size张票据图片,对模型进行训练,并进行模型算法更新;
c5.判断第一训练集中所有图片是否均已完成训练,若是,则转步骤c6,否则返回步骤c4;
c6.用第一测试集验证模型的精度,并保存训练好的模型,更新epoch,返回步骤c3;
c7.将收集的真实训练数据作为第二阶段数据并划分为第二训练集、第二测试集并加载相应数据,用第一阶段训练得到的模型权重初始化网络模型结构;
c8.判断当前epoch是否小于epoch2,若是则转步骤c9,否则结束训练;
c9.从第二训练集中取batch-size张票据图片,对模型进行训练,并进行模型算法更新;
c10.判断第二训练集中所有图片是否均已完成训练,若是,则转步骤c11,否则返回步骤c9;
c11.用第二测试集验证模型的精度,并保存训练好的模型,更新epoch,返回步骤c8。
进一步地,在所述步骤c中,进行模型算法更新时具体是利用sgd优化器进行模型算法更新。
进一步地,所述步骤d中具体是将各个字段的序列图片结合类别信息送入下一阶段的文本识别模型从而得到各个字段的文本信息。
本发明与现有技术相比,具有以下的有益效果:
本发明的基于深度学习实例分割的票据图像文本检测方法,采用一种基于深度学习实例分割的票据图像文本检测与分类方法,通过深度学习技术手段来提升字段匹配的精度及鲁棒性,实现了将识别结果字段后处理匹配问题转化为图像分类问题的处理方式,具体为,若票据中没有多行字段,则可直接将检测结果结合类别信息识别后格式化输出,若有多行文本,只需进行简单的多行字段合并即可,解决了基于规则的字段匹配方法的局限性,同时,提高了匹配精度和开发效率,降低了开发成本。
附图说明
图1是本发明的一个实施例中的人工标注图片示意图。
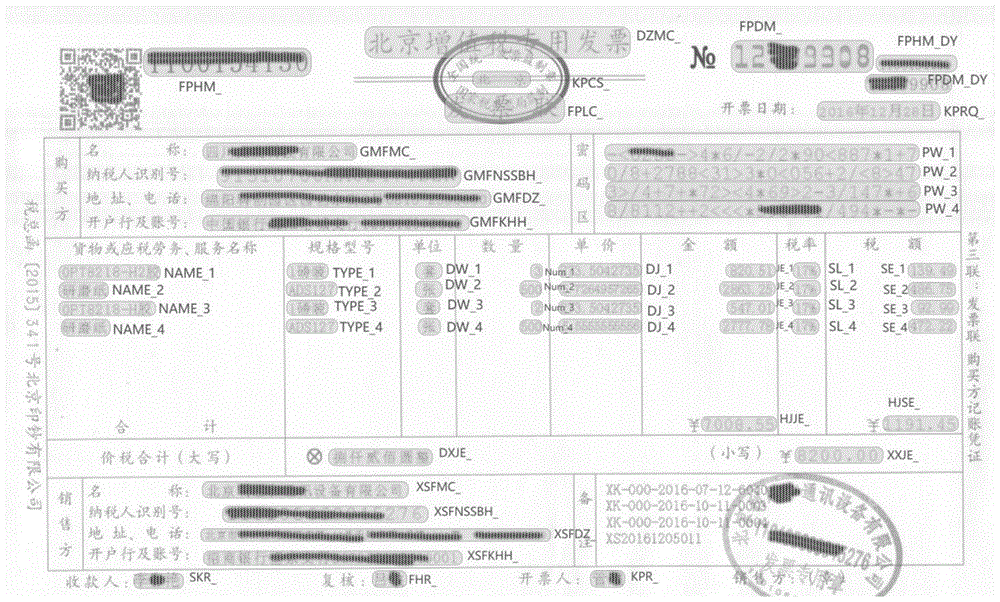
图2是本发明的一个实施例中利用发票语料库使用计算机生成的增值税发票图片示意图。
图3是本发明的一个实施例的文本检测接分类结果示意图。
图4是本发明的一个实施例的网络模型结构示意图。
图5是本发明的一个实施例的模型训练时的两阶段训练流程图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
针对传统发票识别后处理逻辑负载,代码冗余、开发效率低的问题;本实施例采用一种基于深度学习实例分割的发票图像文本检测与分类方法,将识别结果字段后处理匹配问题转化为图像分类问题,通过深度学习技术手段来提升字段匹配的精度及鲁棒性。
具体的,本实施例的基于深度学习实例分割的票据图像文本检测方法的技术方案如下:
step1:训练数据人工标注、伪标签生成。
为有效的训练神经网络,需要大量的标注数据,而人工标注数据将耗费大量时间。本实施例中,为保证标注数据的质量并尽量减少标注成本,具体结合两种训练数据生成方式:
1)人工标注数据;2)计算机自动生成伪标签训练数据。
具体如下:
step1.1.人工数据标注数据准备。
具体是收集不同类别的待标注发票图片,每类200张左右;定义各个字段的类别名称,需要注意的是,如果某个字段在发票图片中有多行,如增值税发票的密码区字段,则将该字段的每行分别标注为不同的类别名称加以区别,标注工具使用via。
本实施例中,以增值税发票为例,选用via数据标注工具。具体如下:下载via数据标注工具via2.0.2—>浏览器打开via.html—>点击左侧的attributes按钮编辑添加文本类别信息—>点击左侧add_files按钮将待标注图片load进浏览器—>选择polygonregionshape在待标注图像中进行数据标注。一般规则图像每个字段文本只需标注四个点即可,非规整图像可视具体情况标注,原则是将文本信息包含在标注区域内且标注区域面积尽量小。图1为本实施例中的标注结果示例。
step1.2.伪标签生成。
由于人工标注费时费力,成本较高,为了降低成本投入,目前很多深度学习任务都使用计算机来自动生成训练数据,例如在文本识别任务中,通常采用从语料库中抽取文本生成对应的序列图像的方式来扩充训练数据。
因此本实施例也采用类似的方式生成训练数据,具体如下:
step1.2.1.整理各个类别发票数据的语料信息;本实施例中仍以增值税发票为例,即准备增值税发票各字段的语料库信息。
step1.2.2.针对各个类别图片,找到一张比较正规的发票模板图片,将该模板图片中各字段的内容抹除,并记录各个字段在模板图片中的初始像素位置。
本实施例中具体为准备增值税发票背景模板图片。可选择较为规整的增值税发票(无旋转角度、无扭曲、拉伸,票面清晰无污点、票面文字整体无明显偏移),记录各个字段在原图中的起始像素位置供后面画图使用,将票面中各字段信息及印章抹除后即得到发票的模板图片。
step1.2.3.编码实现从对应类别的发票语料库中随机抽取各个字段的文本信息画到模板图片对应位置上,其中不同字段根据实际票面显示情况设置不同的字体、字体大小、字符间距、发票内容整体偏移量及模板的背景颜色。
本实施例中具体包括:
首先,随机初始化模板图像背景颜色;随机初始化票面打印文字沿水平和竖直方向的平移尺度,平移量在-30到30个像素之间;随机初始化票面打印文字整体的倾斜尺度,角度范围介于-1°到1°之间,随机初始化画图字体颜色;
然后,从语料库中随机读取各字段文本信息,将各个字段按照文本内容依次画到模板图像上。注意不同字段的字体大小和字符间距可能不同,需要事先统计。
最后,将印章图像填充到对应模板图像区域,生成二维码图像并填充的模板图像左上角对应的二维码区域。
step1.2.4.对生成的发票图像做高斯模糊、加入随机噪声以使生成的图像尽可能显得真实,同时将生成图像中各个字段的像素位置及类别信息写入标签文件,由于发票图像的文本基本都是规整文本信息,因此,这里只记录各个字段外接矩形的四个顶点坐标。
本实施例中具体为使用高斯模糊对生成的增值税发票图片进行预处理并加入随机噪声以使生成的图像尽可能显得真实,记录各个字段的文字及类别信息,将其写入标签文件。具体的,本实施例中生成的伪标签数据示例如图2所示。
step1.3训练数据划分及标签格式转换。将人工标注数据和计算机生成的伪标签数据的标签分别转换成coco数据格式。
step2网络结构及训练参数设置。
step2.1网络结构
本实施例中,如图4所示,训练采用类似于cascademaskrcnn的网络结构,采用hrnet作为基础的特征提取模块,后跟hrfpn作为语义分割模块,具体的,本发明中的实验构建于mmdetection目标检测工具集之上。
step2.2网络参数设置
实验中需要对相应的网络参数做相应修改,主要修改点为:
1)修改rpnhead模块的anchor_ratio。
本实施例中具体做法为,计算label文件中各个文本框的长宽比,然后使用kmeans方法将所有标注文本框聚成6类,本实施例中最终得到的6组宽高比为[1.0,1.0/4.2,1.0/6.0,1.0/10.4,1.0/14.9,1.0/19.5]。
2)修改rpnhead模块的anchor_scales。本实施例中,候选取值为[8,16,32,64,128]。
3)修改box_head及mask_head模块分类类别数,具体是将其置为实际标注的文本框类别个数。
step2.3.训练参数设置
实验采用momentum为0.9的sgd优化器,单gpu学习率设置为0.0025,权重衰减系数weightdecay为0.0001。单gpu(16gb)batch-size为2,使用构造数据初始训练轮数epoch1=30,然后在真实数据上微调轮数为epoch2=10。训练阶段对图像做随机翻转,随机翻转比率为0.5。并将训练图像的像素分布转化均值为[123.675,116.28,103.53],方差为[58.395,57.12,57.375]的正态分布。
step3:模型训练
由于人工标注数据工作量大,成本较高,为了解决真实数据量不足的问题,本发明使用计算机自动生成了大量的训练数据。采用如下策略进行模型训练:第一阶段使用生成的训练数据对模型进行训练保存训练模型权重,第二阶段采用在真实数据上进行模型微调以提高模型在真实票据上的泛化性能。
如图5所示,具体训练过程如下:
step3.1:构建网络模型、设置模型参数。模型初始化参数按照step2.2-step2.3中设置;
step3.2:加载第一阶段训练数据及测试数据;
step3.3:判断当前epoch是否小于epoch1,若是则转步骤step3.4,否则转step3.7;
step3.4:从第一训练集中取batch-size张发票图片,对模型进行训练,并利用sgd进行模型算法更新;
step3.5:判断第一训练集中所有图片是否均已完成训练,若是,则转步骤step3.6,否则转步骤step3.4;
step3.6:用第一测试集验证模型的精度,并保存训练好的模型,更新epoch,转step3.3;
step3.7:加载第二阶段训练数据及测试数据;用第一阶段训练得到的模型权重初始化网络模型结构,其他训练参数同step2.3。
step3.8:判断当前epoch是否小于epoch2,若是则转步骤step3.9,否则结束训练;
step3.9:从第二训练集中取batch-size张发票图片,对模型进行训练,并利用sgd进行模型算法更新;
step3.10:判断第二训练集中所有图片是否均已完成训练,若是,则转步骤step3.11,否则转步骤step3.9;
step3.11:用第二测试集验证模型的精度,并保存训练好的模型转step3.8。
step4:模型部署及预测。
利用训练好的模型对各个类别的发票图片进行文本实例分割,得到各个字段的位置信息及类别信息。可将各个字段的序列图片结合类别信息直接送入下一阶段的文本识别模型,得到各个字段的文本信息,从而简化发票识别的后处理开发流程,并提高后处理字段匹配的准确率。
本实施例的识别结果如图3所示,通过实验表明,本发明的方法在保证检测位置准确率的同时可大大提高文本分类的准确率。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!