一种基于遗传-骨干粒子群混合算法的柔性作业车间调度方法与流程
[0001]
本发明涉及一种柔性作业车间调度技术,尤其是一种新型混合算法的柔性车间作业调度方法,具体说是一种融合了和遗传算法和骨干粒子群算法的混合算法的柔性车间调度方法。
背景技术:
[0002]
随着先进信息和智能技术广泛应用于工业领域,特别是生产制造领域,极大的提升了制造效率和产品质量。先进启发式算法在车间调度问题中的应用,是其中一个重要的方面。通过启发式算法,能够在可以接受的时间成本内,获得相对较优的调度方案,极大提升计划调度的准确性和合理性,在不改造设备的前提下,进一步提高设备利用效率,发挥更大的产能,同时降低成本。
[0003]
现阶段,已有较多的启发式算法,如遗传算法、粒子群算法、蚁群算法等应用在柔性作业车间调度问题。毕竟柔性车间调度问题是强np-hard问题,要获得更优的调度解,必须采用性能更优的算法。单一算法的改进受限于算法自身的基本理论和基础框架,通过自然规律开发新的优化算法,又相对比较困难。因此,通过不同算法的混合,优劣势互补,获得性能更优的混合算法就成了主要的改进方向。遗传算法和粒子群算法由于具备较为明显的优劣势互补性,因此经常作为混合算法的基础。但是,目前流行的遗传算法和粒子群算法的混合策略是将染色体作为一个粒子,采用交叉、变异等方式对粒子群进行更新。该策略存在的主要问题是没有发挥粒子群算法共享全局最优和个体历史最优信息加速算法收敛的优势,难以提高混合算法的收敛速度,更高效的获取更优质的调度方案。所以,有必要提出更合理的混合策略,充分发挥算法优势,获得性能更强的混合算法,以提高求解精度和效率,获得更优质的调度方案。
技术实现要素:
[0004]
本发明为一种解决柔性车间调度问题的新型遗传-骨干粒子群混合算法。该方法通过创新性的将骨干粒子群算法作为遗传算法的变异算子,利用粒子群算法特点加速收敛;并适应该混合策略,提出了改进的染色体表达、初始化、解码、交叉等策略,提高了求解精度和收敛速度,能够获得更优质的作业车间调度方案。
[0005]
本发明的技术方案和步骤如下:
[0006]
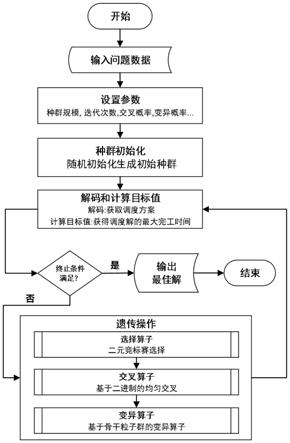
步骤1:输入调度问题基础数据,包括工件数量n,设备数量m,每个工件的工序数p,每个工序可用加工设备编号,以及每台加工设备相应的加工时间。
[0007]
步骤2:设置算法参数,包括种群规模,迭代次数,交叉概率和变异概率等。
[0008]
步骤3:初始化种群,初始种群的质量和多样性,对算法的求解精度和收敛速度有着较大的影响。为保证种群多样性,尽量分散于解空间,面向基于实数的染色体表达提出了一种随机初始化方法。该方法采用等式(1)随机生成每一个初始个体染色体的每一位实数
的值。
[0009]
x
ij
=μ+βi=1,...,n;j=1,...,p;μ∈[1,m];β∈(0,1);
ꢀꢀ
(1)
[0010]
其中,i和j分别代表工件号和工件的工序号;x
ij
为染色体上第i个工件的第j个工序对应的实数值;μ为整数值,从x
ij
对应的o
ij
的可选设备号中随机抽取;β为(0,1)范围内的随机小数。
[0011]
步骤4:解码染色体,获得调度解,计算每个调度解的目标函数值,目标函数值为调度解的最大完工时间。
[0012]
步骤5:判断是否满足退出条件,即:达到设置的最大迭代次数,如果满足退出条件,则输出最佳调度解,即:最大完工时间最小的解;否则继续执行步骤6.
[0013]
步骤6:执行选择算子,选择算子采用二元锦标赛选择方法。随机在种群中选择两个个体,比较两个个体的目标函数值,选择较优的个体作为下代个体。
[0014]
步骤7:对选择算子确定的父代,在满足交叉概率的条件下,执行交叉操作。面向基于实数的染色体表达方式,提出了基于二进制的均匀交叉方法,该方法流程如下:
[0015]
子步骤1:随机选择两个个体作为待交叉的父代个体;
[0016]
子步骤2:随机产生一个长度等于染色体长度的二进制串;
[0017]
子步骤3:确定二进制串值为1的位置索引,根据该位置索引,将父代1相应位置处的实数值复制至子代1相应位置处,将父代2相应位置处的实数值复制至子代2相应位置处;
[0018]
子步骤4:确定二进制串值为0的位置索引,根据该位置索引,将父代1相应位置处的实数值复制至子代2相应位置处,将父代2相应位置处的实数值复制至子代1相应位置处,完成交叉操作。
[0019]
步骤8;对满足变异概率的个体,采用骨干粒子群算法的核心策略,即:借助全局最优和个体历史最优对粒子位置的进行更新,进行变异操作。变异操作分为如下3个子步骤:
[0020]
子步骤1:更新本代的全局最优个体和个体历史最优个体;首先,确定本代的全局最优个体,将本代全局最优个体目标函数值和当前全局最优个体目标值进行对比,如果本代全局最优个体目标函数值优于当前全局最优个体,采用本代全局最优个体作为当前全局最优个体;然后比较每个个体的当前历史最优个体和本代个体的目标值,如果本代目标值优于当前历史最优个体,则采用本代个体作为历史最优个体;
[0021]
子步骤2:采用等式(2)计算变异个体的染色体值,获得变异的新个体;
[0022]
p
i
(k+1)=g
best
(k)+α
×
c(1,0)
×
|p
best
(k)-g
best
(k)|
ꢀꢀ
(2)
[0023]
p
i
表示粒子个体,g
best
表示全局最优个体,p
best
表示个体历史最优,c(1,0)为服从标准柯西分布的随机数,α是一个控制参数,控制粒子的聚集程度;为了实现在算法前期加速收敛,控制粒子尽量聚集,算法后期防止陷入局部最优,扩展搜索范围,控制粒子尽量分散,α采用自适应策略,在求解中根据迭代次数改变,计算公式如等式(3):
[0024]
α=α
min
+(α
max-α
min
)
×
k/gn
ꢀꢀ
(3)
[0025]
α
min
和α
max
为初始设置的α的最小和最大值,规定值变化范围;k为当前迭代次数;gn为初始设置的最大迭代次数;
[0026]
子步骤3:变异后的染色体,由于是在实数域内进行计算,更新后实数的整数部分的值可能超过相应工序的可选设备范围,产生不可行解;因此,需要对染色体整数部分值进行检查和修复,提出了一种修复机制:逐一检查染色体每一位的实数的整数部分值,如果超
过了设备可选范围,采用等式(4)中所示公式进行整数值的修复:
[0027][0028]
i(t)和i’(t)分别代表染色体第t位实数值的整数部分修复前和修复后的值,m
ij
代表染色体第t位对应的工序o
ij
的可选设备集的设备总数。
[0029]
步骤9:转步骤4。
[0030]
所述的基于实数的染色体表达具体如下:基于实数的染色体表示方式采用一组实数串同时表达柔性作业车间调度的两个子问题,即:设备选择和工序排序;实数串的长度等于调度任务所有工序的总数;实数串的每一位实数值,表达对应工序的设备选择和排序顺序,将实数拆分为整数部分和小数部分;其中,整数部分代表该工序选定的加工设备编号索引,小数部分代表该工序排序的优先权值,值越小,优先权越高,排序越靠前。
[0031]
所述的基于实数的染色体解码方法,即:通过基于实数的染色体串,获得每个工序的选定设备编号和工序安排的顺序,并以此获取对应的调度计划安排,具体步骤如下:
[0032]
步骤1:读取染色体串,将染色体串每一位实数值,拆分为整数值部分和小数值部分,分别获取整数串和小数串;
[0033]
步骤2:对于整数串,从左向右读取每一位整数值,以此代表从第一个工件的第一个工序开始,一直到最后一个工件的最后一个工序结束,每一个工序所选定的设备在可选设备集中的索引号,通过该索引号,即可获得本工序选定的加工设备;
[0034]
步骤3:对于小数部分,从左到右每一位小数值,分别代表从第一个工件的第一个工序开始,一直到最后一个工件的最后一个工序结束的每一个工序的排序优先权值;因此,将小数部分从小到大进行排列,为工序安排的优先级排列,即可获得工序安排的顺序。
[0035]
本发明的有益效果:
[0036]
本算法将骨干粒子群算法的粒子位置更新策略作为遗传算法变异算子,辅以基于实数的染色体表达方式,有效发挥的粒子群算法高效收敛的优势,实现了种群个体以全局最优和个体历史最优为参照的定向变异,提高了算法收敛速度和求解精度,能够更高效的获得更优质的调度方案,进一步释放产能,提高生产效率。
附图说明
[0037]
图1是本发明算法框架和总体流程图
[0038]
图2是本发明问题实例图
[0039]
图3是本发明中染色体基于实数的表达方式图
[0040]
图4是本发明中染色体解码方法图
[0041]
图5是本发明中染色体基于二进制的交叉方法图
[0042]
图6是本发明问题实例的调度解甘特图
具体实施方式
[0043]
下面结合附图和实例对本发明进行进一步说明。
[0044]
本发明是一种基于新型遗传-骨干粒子群混合算法的柔性作业车间调度方法,融合了骨干粒子群算法和遗传算法,实现对柔性作业车间调度问题的求解,算法流程如图1所示。现以图2所示的问题实例说明。
[0045]
步骤1:输入问题基本数据,包括工件数4,设备数6以及每个工件的每个工序在可选设备上的加工时间。
[0046]
步骤2:设置算法参数:种群规模100,交叉概率0.8,变异概率0.1,迭代次数200次。
[0047]
步骤3:生成初始化种群,即:生成100个初始个体的染色体;个体染色体采用基于实数的表达方式,染色体每一位元素采用等式(1)依次生成;
[0048]
x
ij
=μ+βi=1,...,n;j=1,...,p;μ∈[1,m];β∈(0,1);
ꢀꢀ
(1)
[0049]
如图3所示为某一个初始个体的染色体表达;基于实数的染色体串的每一位分别依次对应从第一个工件的第一个工序到最后一个工件的最后一个工序;表达可以分为整数部分表达和小数部分表达,整数部分表达代表对应工序的确定设备索引号,小数部分代表对应工序的排序优先权值;如第一位元素值x
11
,采用等式(1)生成,随机选取对应工序o
11
可选设备集中的第1个设备,μ=1;随机生成小数β=0.24;x
11
=1+0.24=1.24。
[0050]
步骤4:解码每一个初始个体染色体,获得调度方案,再计算目标函数值,即最大完工时间。如图4所示的某个体染色体解码,先将实数拆分为整数部分和小数部分;通过整数部分的索引号,能够确定选择的设备号,如o
21
整数部分为2,代表其可选设备集中的第二台设备,即:m3;再将小数部分由小至大进行排序,获得工序根据优先级大小的顺序排列,即操作序列,根据操作序列中工件号出现的顺序和出现的次数(工件号出现次数代表该工件的工序号,如图4中工件号2第一次出现,代表工序o
21
,以此类推),即可获得工序安排顺序。
[0051]
步骤5:判断迭代次数是否等于设置的迭代次数,如果满足,转步骤10;否则继续执行步骤6。
[0052]
步骤6:采用二元竞标赛选择下代个体,随机在种群中选择二个个体,并将较优的个体选中,如此循环,直至选择出100个个体。
[0053]
步骤7:对满足交叉概率的父代进行交叉操作,交叉操作采用基于二进制的均匀交叉方法。图5表示了某两个父代的交叉,首先产生一个和父代染色体长度相同的二进制串;然后将父代1和父代2对应二进制串值为1的位置,即2、3、4、7、8位分别复制至子代1和子代2的相应位;接着将父代1和父代2对应二进制串值为0的位置,即1、5、6、9位分别复制值子代2和子代1。
[0054]
步骤8:对满足变异概率的个体,按如下流程执行变异操作,否则保持原个体。
[0055]
1)更新第k代的全局最优个体g
best
(k)和个体历史最优p
best
(k);
[0056]
2)采用等式(2)对待变异个体的染色体进行位置更新运算,获得变异个体的染色体;
[0057]
p
i
(k+1)=g
best
(k)+α
×
c(1,0)
×
|p
best
(k)-g
best
(k)|
ꢀꢀ
(2)
[0058]
a为自适应参数,在更新位置运算前,采用公式(3)计算确定;
[0059]
α=α
min
+(α
max-α
min
)
×
k/gn
ꢀꢀ
(3)
[0060]
α
min
和α
max
为设置为0.1和1;k为当前迭代次数;gn为初始设置的最大迭代次数200;
[0061]
3)对变异个体染色体每一位的整数值进行检查,是否超过对应工序的可选设备集范围,如果超过了范围,必须采用等式(4)进行修复,以免产生不可行解。
[0062][0063]
如果某一位整数值为5,最大可选设备数为3,超过了设备选择范围,采用等式(4)修复:5mod 3=2。
[0064]
步骤9转步骤4。
[0065]
步骤10将当前代的最优个体作为问题解,绘制调度甘特图,表示调度方案,如图6所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1