一种基于双层知识蒸馏说话人模型压缩系统和方法与流程
1.本发明属于基于双层知识蒸馏技术的模型压缩技术领域,尤其涉及一种基于双层知识蒸馏说话人模型压缩系统和方法。
背景技术:
2.近年来,随着计算资源和数据资源的日益丰富。基于深度神经网络的机器学习使得说话人识别系统的准确率显著提升。对于网络连接不可用或担心个人隐私泄漏的情况,人们希望能够在手机等嵌入式设备本地使用说话人识别技术,这种在嵌入式终端运行的说话人识别系统具有更高的安全水平。然而,现有的说话人识别技术依赖于深度神经网络,昂贵的计算量和大量的内存占用阻碍了它们在内存资源较低的嵌入式设备中部署。因此,越来越多的研究关注在不显著降低模型性能的情况下,对深层网络进行模型压缩和加速。
3.为了压缩这些网络,知识蒸馏是一种常用的方法,其中大型网络(教师)提供加权目标以指导小型网络(学生)的训练。尽管事实证明知识蒸馏是在各种任务(例如图像分类,语音识别和说话者验证)中进行模型压缩的实用方法,但是以前的研究人员仅研究了单层知识蒸馏对说话人表征性能的影响,并且当压缩比例越来越大,这些方法不足以弥补大小模型之间的性能差距,要获得一名性能优于教师网络的学生网络仍然是一个挑战。
技术实现要素:
4.本发明的目的是提供一种基于双层知识蒸馏说话人模型压缩系统和方法,以解决现有技术中学生网络不能实现较小的说话人类内差异和较大的说话人类间差异,且相同说话人和不同说话人验证系统的准确性较低的问题。
5.为了实现上述目的,本发明提供如下技术方案:
6.一种基于双层知识蒸馏说话人模型压缩方法,包括:
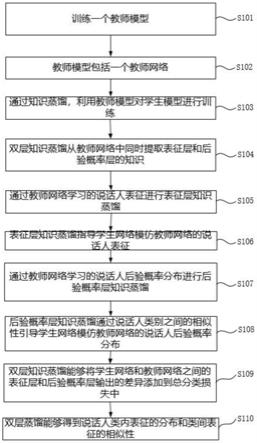
7.s101,训练一个教师模型,教师模型能够提取教师网络学习的说话人表征,教师模型能够预测教师网络学习的说话人后验概率分布。
8.s102,教师模型包括一个教师网络,教师网络包括表征层和后验概率层。
9.s103,通过知识蒸馏,利用教师模型对学生模型进行训练。学生模型包括一个学生网络,学生模型能够提取学生网络学习的说话人表征。
10.s104,双层知识蒸馏能够从教师网络中同时提取表征层和后验概率层的知识。
11.s105,通过教师网络学习的说话人表征进行表征层知识蒸馏。
12.s106,表征层知识蒸馏指导学生网络模仿教师网络的说话人表征。
13.s107,通过教师网络学习的说话人后验概率分布进行后验概率层知识蒸馏。
14.s108,后验概率层知识蒸馏通过说话人类别之间的相似性引导学生网络模仿教师网络的说话人后验概率分布。
15.s109,双层知识蒸馏能够将学生网络和教师网络之间的表征层和后验概率层输出的差异添加到总分类损失中。
16.s110,双层蒸馏能够得到说话人类内表征的分布和类间表征的相似性。通过说话人表征的层次化分布指导学生实现较小的说话人类内差异和较大的说话人类间差异,从而最终提高说话人建模的准确性。
17.在上述技术方案的基础上,本发明还可以做如下改进:
18.进一步地,表征层知识蒸馏能够得到教师网络对每个说话人表征的总体分布,从而直接指导学生网络说话人类内表征的收敛。
19.进一步地,从教师网络后验概率层的输出中提取知识,后验概率层知识蒸馏通过教师模型能够预测的后验分布指导学生模型的优化。后验概率层知识蒸馏能够学到说话人类别之间的相似性。
20.进一步地,从教师网络后验概率层的输出中提取知识。
21.进一步地,将教师网络后验概率层的输出作为标准,纳入学生网络损失函数的计算,引导学生模型参数的更新。
22.进一步地,后验概率层知识蒸馏通过教师模型预测的后验概率分布指导学生模型的优化。
23.进一步地,学生模型通过分类函数am
‑
loss引入参数m控制角度余量,学生模型在不同说话人类别的表征之间生成角度分类余量,学生模型能够使得正确分类的要求更为严格。
24.进一步地,总分类损失为表征层知识蒸馏的余弦距离损失、后验概率层知识蒸馏的kl散度损失和用于说话人分类的softmax损失。
25.一种基于双层知识蒸馏说话人模型压缩系统,包括:
26.训练一个教师模型,教师模型能够提取教师网络学习的说话人表征,教师模型能够预测教师网络学习的说话人后验概率分布。
27.教师模型包括一个教师网络,教师网络包括表征层和后验概率层。
28.通过知识蒸馏,利用教师模型对学生模型进行训练。学生模型包括一个学生网络,学生模型能够提取学生网络学习的说话人表征。
29.双层知识蒸馏能够从教师网络中同时提取表征层和后验概率层的知识。
30.通过教师网络学习的说话人表征进行表征层知识蒸馏。
31.表征层知识蒸馏指导学生网络模仿教师网络的说话人表征。
32.通过教师网络学习的说话人后验概率分布进行后验概率层知识蒸馏。
33.后验概率层知识蒸馏通过说话人类别之间的相似性引导学生网络模仿教师网络的说话人后验概率分布。
34.双层知识蒸馏能够将学生网络和教师网络之间的表征层和后验概率层输出的差异添加到总分类损失中。
35.双层蒸馏能够得到说话人类内表征的分布和类间表征的相似性。通过说话人表征的层次化分布指导学生实现较小的说话人类内差异和较大的说话人类间差异,从而最终提高说话人建模的准确性。
36.本发明具有如下优点:
37.本发明中的基于双层知识蒸馏说话人模型压缩系统,embedding层知识蒸馏指导学生网络模仿教师网络的段级说话人表示(说话人表征),它捕获了每个说话人特征的基本
分布。logit层知识蒸馏引导学生网络模仿教师网络的说话人后验概率分布,利用了说话人类别之间的相似性。此方法从教师网络那里迁移了说话人表征分布的层次结构。双层知识蒸馏可以帮助学生网络实现较小的说话人类内差异和较大的说话人类间差异,并进一步提高相同说话人和不同说话人验证系统的准确性。
附图说明
38.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
39.图1为本发明基于双层知识蒸馏说话人模型压缩方法的流程图。
40.图2为本发明的双层知识蒸馏方法流程图。
41.图3为本发明的双层知识蒸馏原理示意图。
42.图4为本发明的双层知识蒸馏原理示意图。
43.图5为本发明的双层知识蒸馏和原始单层知识蒸馏的对比数据示意图。
具体实施方式
44.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
45.如图1
‑
5所示,本发明实施例提供了一种基于双层知识蒸馏说话人模型压缩系统,包括:
46.知识蒸馏的基本数学模型。知识蒸馏旨在将知识从大型教师网络t 转移到小型学生网络s。训练学生网络来模仿教师网络的行为。这里ht和hs分别表示教师网络和学生网络的行为函数。这个行为函数将网络输入转换为一种信息表达,具体来说就是网络中任何层的输出。例如,hls表示学生网络中层l的输出。学生网络的层l以通过映射函数f(l),与教师网络中的层l’匹配,这意味着学生网络的层l可以从教师网络的层l’中学习信息。最后,通过最小化学生输出和教师输出的差异,学生可以很好的模仿教师网络的行为:
[0047][0048]
其中$x_{i}$表示第i个训练集样本。$\mathcal{l}_{l}$是指损失函数,它限制了学生的$l$层的输出与老师的$f(l)$层的输出之间的差异(例如,嵌入层或l
ogit
层)。$\lambda_{l}$表示超参数,它表示第l$层进行蒸馏的重要性。$n$是训练样本的数量。$l$是指学生的总层数。
[0049]
在学生网络和教师网络之间匹配适当的层以进行知识蒸馏并非易事。在大多数情况下,我们必须应对它们在宽度和深度上的差异。
[0050]
s101,训练一个教师模型。
[0051]
本步骤中,训练一个教师模型10,教师模型10能够提取教师网络学习的说话人表
yang,tianzhe wang,yanmin qian,and kai yu."knowledgedistillation for small foot
‑
print deep speaker embedding."in icassp2019
‑
2019ieee international conference on acoustics,speech and signalprocessing(icassp),pp.6021
‑
6025.ieee,2019.)的对比数据如图5,测试集为小爱同学。
[0075]
表征层知识蒸馏能够得到教师网络对每个说话人表征的总体分布,从而直接指导学生网络说话人类内表征的收敛。
[0076]
对于说话人i,受到余弦相似度的限制,学生模型20提取的说话人表征sspki向教师模型10提取的说话人表征tspki收敛,从而使得学生模型20 实现更小的类内差异。
[0077]
从教师网络后验概率层的输出中提取知识,后验概率层知识蒸馏通过教师模型10能够预测的后验分布指导学生模型20的优化。后验概率层知识蒸馏能够学到说话人类别之间的相似性。
[0078]
通过最小化教师网络和学生网络后验概率之间的kl散度:
[0079][0080][0081]
其中\(c\)是训练集中的说话者人数。\(\tilde{y}^i\)是教师网络预测的第$i$个样本的后验者。\({y}^i\)是学生网络预测的第$i$个样本的后验者。符号的其他定义类似于公式\ref{eq:cos}。
[0082]
后验概率是有价值的信息,可对不同类别之间的相关性进行编码。因而后验概率层知识蒸馏可以学到说话人类别之间的相似性。
[0083]
如图2
‑
3所示,可以看到后验概率层知识蒸馏增大了学生网络的类间差异。相似性高的说话人聚成一个子类。
[0084]
从教师网络后验概率层的输出中提取知识。
[0085]
将教师网络后验概率层的输出作为标准,纳入学生网络损失函数的计算,引导学生模型20参数的更新。
[0086]
后验概率层知识蒸馏通过教师模型10预测的后验概率分布指导学生模型20的优化。
[0087]
学生模型20通过分类函数am
‑
loss引入参数m控制角度余量,学生模型20在不同说话人类别的表征之间生成角度分类余量,学生模型20能够使得正确分类的要求更为严格。
[0088]
总分类损失为表征层知识蒸馏的余弦距离损失、后验概率层知识蒸馏的kl散度损失和用于说话人分类的softmax损失。其中α和β是用于平衡这些损失的超参数,之后将在实验中对超参数的取值进行优化。
[0089]
l
total
=l
a
‑
softmax
+αl
kld
+βl
cos
[0090]
一种基于双层知识蒸馏说话人模型压缩系统,包括:
[0091]
训练一个教师模型10,教师模型10能够提取教师网络学习的说话人表征,教师模型10能够预测教师网络学习的说话人后验概率分布。
[0092]
教师模型10包括一个教师网络,教师网络包括表征层和后验概率层。
[0093]
通过知识蒸馏,利用教师模型10对学生模型20进行训练。学生模型 20包括一个学
生网络,学生模型20能够提取学生网络学习的说话人表征。
[0094]
双层知识蒸馏能够从教师网络中同时提取表征层和后验概率层的知识。
[0095]
通过教师网络学习的说话人表征进行表征层知识蒸馏。
[0096]
表征层知识蒸馏指导学生网络模仿教师网络的说话人表征。
[0097]
通过教师网络学习的说话人后验概率分布进行后验概率层知识蒸馏。
[0098]
后验概率层知识蒸馏通过说话人类别之间的相似性引导学生网络模仿教师网络的说话人后验概率分布。
[0099]
双层知识蒸馏能够将学生网络和教师网络之间的表征层和后验概率层输出的差异添加到总分类损失中。
[0100]
双层蒸馏能够得到说话人类内表征的分布和类间表征的相似性。通过说话人表征的层次化分布指导学生实现较小的说话人类内差异和较大的说话人类间差异,从而最终提高说话人建模的准确性。
[0101]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制。尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1