一种基于判别性低秩分解与稀疏表示的人脸识别方法与流程
本发明属于图像处理技术领域,具体涉及一种基于判别性低秩分解与稀疏表示的人脸识别方法。
背景技术:
j.wright最先在机器学习领域中将稀疏理论应用于人脸识别,产生了稀疏表示的人脸识别算法(src),该算法在理想环境下有着较好的识别结果,但是在受光照、遮挡干扰等情况识别结果有待优化;在训练样本不足的情况下,构成的字典矩阵无法满足稀疏表示的需求时,src的识别率会降低。e.candes等人提出了一种矩阵低秩恢复算法(lrr),该算法通过分解构造的字典矩阵得到一个低秩组件和一个非低秩组件,低秩组件描述与人脸相关的信息,非低秩组件描述的是与稀疏误差相关的信息,使得字典的求解有了新的突破。杜海顺等人根据lrr理论提出了一种基于低秩恢复稀疏表示分类器(lrr-src),该算法在训练样本数量不足的情况下可以有效的识别人脸,但在识别率上有待提高。
技术实现要素:
本发明为了解决现有人脸识别算法在人脸被遮挡、被光照干扰等情况表现不足的问题,本发明提出一种基于判别性低秩分解与稀疏表示的人脸识别方法,首先对训练样本进行判别性低秩分解,获取与人脸信息相关的低秩组件,减少受光照、遮挡等影响产生的稀疏误差,然后再重构残差函数优化误差,进而优化识别结果,对光照、遮挡等影响具有良好的鲁棒性。
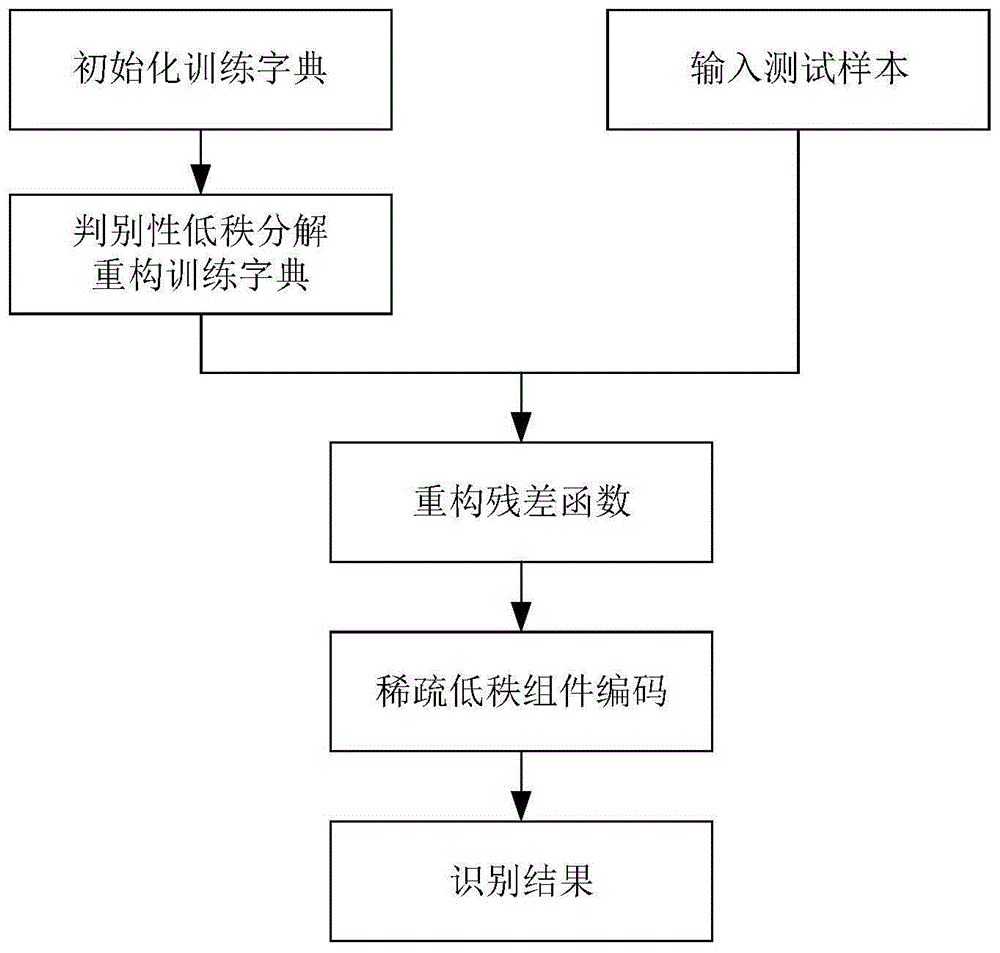
本发明的技术方案为:一种基于判别性低秩分解与稀疏表示的人脸识别方法,具体按照以下步骤进行:
步骤(1):输入训练人脸图像,获得字典矩阵d;
步骤(2):对字典矩阵d进行判别性低秩分解,把字典矩阵d分解为与人脸信息相关的低秩组件l和与稀疏误差相关的非低秩组件n;
步骤(3):对测试样本进行稀疏低秩组件编码,并重构残差函数优化重构误差;
步骤(4):计算测试样本所对应每类训练样本的稀疏残差,根据稀疏残差最小完成分类,进而实现人脸识别。
本发明的有益效果:
(1)本发明改进判别性低秩分解,通过添加两项结构不相关判别性项,去除类间相关性,有效的获取与人脸信息相关的低秩分量,减少由光照、遮挡等产的的稀疏误差对分类的影响。
(2)本发明重构残差函数,由于遮挡部分通常比正常部分有着更大的重构误差,通过得到的加权矩阵动态平衡重构误差,进一步的降低遮挡产生的不良影响,进而提高在遮挡环境下本发明的鲁棒性。
附图说明
图1为本发明实施的流程框图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,本发明基于判别性低秩分解与稀疏表示的人脸识别方法,具体按照以下步骤进行:
步骤(1):输入训练人脸图像,获得字典矩阵d:
字典矩阵d有c类训练样本,每类由ni张训练人脸图像组成,则共有
d=[d1,d2,...,dc]∈rm*n(1)
m是特征向量的维数;
步骤(2):对字典矩阵d进行判别性低秩分解,把字典矩阵d分解为与人脸信息相关的低秩组件l和与稀疏误差相关的非低秩组件n,通过添加两项结构不相关判别项
其中,di表示第i类的训练样本,li表示第i类的低秩分量,ni表示第i类的非低秩分量。为了方便求解,ai、bi为辅助变量,χ表示非低秩分量ni的权重,φ1、φ2表示不相关判别项的权重,χ、φ1、φ2的值均大于0,其对应的拉格朗日扩展式为:
其中,xi、yi、zi是拉格朗日乘子,μ是惩罚因子,<·,·>表示矩阵的内积。
利用交替方向乘子法求解式(2)的最小值,在每次迭代中根据以下步骤更新参数:
1)更新第k+1次迭代参数
其中
2)更新第k+1次迭代参数
其中
3)更新第k+1次迭代参数
4)更新第k+1次迭代参数
5)更新拉格朗日乘子
6)更新惩罚系数
7)判断式(2)是否收敛,如果收敛则结束迭代,如果不收敛则继续迭代。
步骤(3):对测试人脸图像y进行稀疏低秩组件编码:
y=lα+nβ+z(18)
其中,α表示稀疏因子,β是控制非低秩组件n的折衷常数,z表示重构误差。
通过求解l1范数获得稀疏因子α:
其中λ表示为控制重构误差的常数,每一类的残差函数p(zi)表示为:
η和θ是残差函数中的可调参数,重构残差函数,在求导过程中优化重构误差:
通常受光照、遮挡等干扰严重的样本有着更大的误差,w(zi)表示误差的权重,由式(5)可得w(zi):
根据矩阵二范式定理可将
应用式(6)形成的加权矩阵可以动态平衡稀疏误差,进而优化识别结果,如式(20)所示:
步骤(4):计算测试样本所对应每类训练样本的稀疏残差:
其中,i表示单位矩阵,c表示字典矩阵d的标签矩阵,如果ci来自d的第k类,则ci(k,k)=1,其他位置数据都是0,类标签矩阵ci定义为:
根据稀疏残差最小完成分类:
identity(y)=argminri(y)(23)
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技术所创的等效方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!