基于负荷特性和用电行为模式的家庭负荷预测方法及系统与流程
[0001]
本发明属于电力负荷预测领域,涉及一种基于负荷特性和用电行为模式的家庭负荷预测方法及系统。
背景技术:
[0002]
电力负荷预测水平已经成为电力系统运行和管理现代化的一个关键标志,它关系到参与电力市场交易各方的经济利益,关系到不确定性不断增加的电力系统的安全经济运行。由于短期负荷变化相关因子多(假期、气候、电价、人口)、在时间序列上表现为显著的非平稳的随机过程、负荷变化规律复杂、负荷的随机性和不确定性较高等原因使得短期负荷预测成为较有挑战性的预测。短期电力负荷预测方法可以简单分为三类:第一类是基于传统数学统计模型的方法,如回归预测模型,指数平滑法,时间序列法等;第二类是基于机器学习的预测方法,如神经网络模型,支持向量机模型,决策树模型等;第三类是组合预测方法,利用优化算法获得预测模型参数或一些预处理技术如波谱分析中将负荷分解后再预测,或者通过分配权重将不同模型组合或使用一个模型的预测结果作为另一个模型的特征进行训练,然后得到新的预测结果。
[0003]
对于非平稳的家庭负荷数据,由于居民用电行为的多样性使得负荷的分布具有更高的不确定性和波动性,直接使用单一的预测模型很难挖掘出更深层次的时序特征。在短期电力负荷预测中,每种方法都有不可避免的缺陷。例如,非线性和季节性特征不能通过线性回归来捕捉,人工神经网络可能陷入局部最优等问题。因此结合具体场景的数据特征和问题推演机理将不同模型进行结构化堆叠,往往能取得更好的效果。
[0004]
现有的组合预测模型大多采用负荷分解后再预测的方法。经过负荷分解后得到的高频分量中通常有很大成分的噪声,难以预测。由于这部分分量也是原始负荷的重要组成部分,如果直接采取降噪或滤波处理,显然会降低预测的精度。同时,目前对于短期电力负荷的预测模型缺乏对电力场景下的数据特征的分析和处理,使模型缺乏异质性。模型的输入数据通常只包括负荷数据、天气数据、温度数据等,缺乏针对电力系统运行特性和居民用电行为特性去提取负荷时间序列中更多的信息,无法准确实现家庭负荷的预测。
技术实现要素:
[0005]
本发明的目的在于提供一种基于负荷特性和用电行为模式的家庭负荷预测方法及系统,以克服现有技术的不足。
[0006]
为达到上述目的,本发明采用如下技术方案:
[0007]
一种基于负荷特性和用电行为模式的家庭负荷预测方法,包括以下步骤:
[0008]
步骤1)、构建组合预测模型,采集家庭原始用电负荷时间序列得到原始数据集,并对原始数据集进行预处理得到完整原始数据集;
[0009]
步骤2)、基于负荷特性和用电行为模式从完整原始数据集中获取用电数据特征;
[0010]
步骤3)、基于pca方法将负荷特征进行降维处理得到四维特征向量;
[0011]
步骤4)、将完整原始数据集通过差分变换和指数加权移动平均处理得到平稳序列,使用arima模型对平稳序列进行学习得到预测序列,采用降维处理后得到的四维特征向量结合预测序列对组合预测模型进行训练并验证,利用训练完成的组合预测模型实现家庭负荷预测。
[0012]
进一步的,采样频率为60次/小时。
[0013]
进一步的,对原始数据集进行预处理具体为:对原始数据集中的缺失值,采用该原始数据集中前一天同一时刻的数据填充该缺失值。
[0014]
进一步的,组合预测模型采用lstm-arima-xgboost组合预测模型。
[0015]
进一步的,从完整原始数据集中获取用电数据特征具体步骤为:1)、取前m天的完整原始数据集作为历史负荷特征;
[0016]
2)、从历史负荷时间序列中获取负荷聚合特征;
[0017]
3)、计算负荷时间序列周期为7的指数加权移动平均值v
n
,构成负荷时间序列的趋势特征数据;
[0018]
4)、计算电力负荷场景下的kdj值:
[0019][0020]
若无前一日k值与d值,则k值与d值均取50;
[0021][0022]
其中n是一个时间窗口,c为当天日小时负荷的平均值,h
n
是过去n日最大负荷的最大值,l
n
是过去n日最小负荷的最小值;
[0023]
5)、将星期属性、节假日属性和季节属性赋值于历史负荷时间序列。
[0024]
进一步的,负荷聚合特征包括日最大负荷、日最小负荷、日平均负荷、日负荷率、日最小负荷率、日峰谷差和日峰谷差率。
[0025]
进一步的,对负荷聚合特征数据、负荷趋势特征和负荷偏离特征进行0-1标准化处理;对星期类型、假期类型和季节类型构成的时间特性以及用户用电行为模式构成的行为特性进行one-hot编码。
[0026]
进一步的,从日负荷序列中计算历史负荷序列中第n项的指数加权移动平均值v
n
:v
n
=βv
n-1
+(1-β)θ
n
(8)
[0027]
其中,θ
n
为第n项的实际负荷值,系数β表示加权下降的快慢,值越小权重下降的越快,在本实例中,取β=0.95。
[0028]
进一步的,采用增广迪基-福勒检验以及jung-box白噪声检验来检验原始负荷时间序列的平稳性,将完整原始数据集通过差分变换和指数加权移动平均处理得到平稳序列f1,使用arima模型进行学习得到预测序列s
n+1
,将预测序列s
n+1
作为新的特征加入pca降维后的四维特征f2中形成组合特征f3,将组合特征f3分别作为xgboost_1层和xgboost_2层的输入特征,将xgboost_1层的输出结果加入组合特征f3中构成组合特征f4,将组合特征f4作
为第三层lstm的输入特征完成模型的训练。
[0029]
一种基于负荷特性和用电行为模式的家庭负荷预测系统,包括预处理模型、特征提取模块、降维处理模块和预测模块;
[0030]
预处理模型用于将采集到的家庭原始用电负荷时间序列整理得到原始数据集,并对原始数据集进行预处理得到完整原始数据集;
[0031]
特征提取模块用于从完整原始数据集中获取历史负荷特征和负荷聚合特征,降维处理模块用于将特征提取模块获取的负荷聚合特征进行降维处理得到四维特征向量;
[0032]
预测模块用于将完整原始数据集通过差分变换和指数加权移动平均处理得到平稳序列,然后对平稳序列进行学习得到预测序列,将降维处理后得到的四维特征向量结合预测序列对组合预测模型进行训练并验证,利用训练完成的组合预测模型实现家庭负荷预测。
[0033]
与现有技术相比,本发明具有以下有益的技术效果:
[0034]
本发明一种基于负荷特性和用电行为模式的家庭负荷预测方法,首先采集家庭原始用电负荷时间序列得到原始数据集,并对原始数据集进行预处理得到完整原始数据集,然后采用基于负荷特性和用电行为模式从完整原始数据集中获取用电数据特征,基于svd分解协方差矩阵的pca算法完成特征提取,实现数据降维,通过差分变换和exponentially-weighted moving average处理得到平稳序列,利用组合模型捕捉序列更复杂的非线性关系,优化数据输入结构使模型在预测时结合历史状态,通过多变量的模型提升拟合的精度,提高了现有电力负荷预测方法的精度。
[0035]
进一步的,对原始数据集中的缺失值,采用该原始数据集中前一天同一时刻的数据填充该缺失值,提高了原始数据集的准确度,减少数据的跳跃性波动。
[0036]
进一步的,首先从负荷的聚合特性、偏离特性、趋势特性、日期特性、用电行为特性构建了家庭负荷预测的特征工程,利用组合模型捕捉序列更复杂的非线性关系,优化数据输入结构使模型在预测时结合历史状态,负荷特性,节假日,季节气候,不同用电行为模式等,通过多变量的模型提升拟合的精度。
[0037]
进一步的,本发明从不同维度捕捉用户用电的行为习惯,能够准确的预测出家庭用电负荷中波动和不确定的成分。
[0038]
本发明一种基于负荷特性和用电行为模式的家庭负荷预测系统,通过不同模型的组合,大大提高了模型的泛化性能,预测能力进一步增强。
附图说明
[0039]
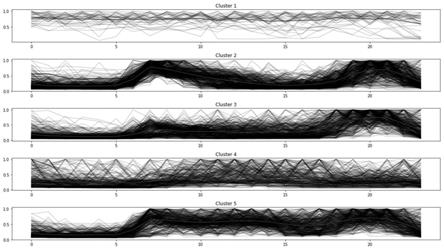
图1本发明实施例中应用k-means聚类将用户用电行为模式分组的负荷曲线图。
[0040]
图2为本发明实施例中基于负荷特性和用电行为模式的家庭负荷预测方法流程图。
[0041]
图3为本发明提供的arima-xgboost-lstm家庭负荷多层组合预测模型结构图。
[0042]
图4为组合预测模型中lstm的网络结构图。
[0043]
图5为本发明使用uci数据集测试的预测结果图。
具体实施方式
[0044]
下面结合附图对本发明做进一步详细描述:
[0045]
如图2所示,一种基于负荷特性和用电行为模式的家庭负荷预测方法,包括以下步骤:
[0046]
步骤1)、构建组合预测模型,采集家庭原始用电负荷时间序列得到原始数据集,并对原始数据集进行预处理得到完整原始数据集;
[0047]
采样频率为60次/小时;具体的,采用原始数据集来源于uci数据库中的个体家庭用电量数据集,该数据集以分钟为采样频率测量了一个家庭近4年的用电消耗,从2016年12月至2010年11月(47个月),共计2075259个采样值,其中有近1.25%的缺失值。
[0048]
对原始数据集进行预处理具体为:对原始数据集中的缺失值,采用该原始数据集中前一天同一时刻的数据填充该缺失值。
[0049]
数据重采样:对原始数据集按照小时的维度进行重采样,以天划分,获得每天每小时的小时负荷序列;即每隔一小时采集一次的频率进行重采样处理,得到小时负荷序列;对小时采样值按照日期维度进行重采样处理,得到日负荷序列。
[0050]
数据集划分:将预处理后的原始数据集划分为训练集,验证集和测试集;具体按照0.7/0.2/0.1的比例将预处理后的原始数据集划分为训练集,验证集和测试集。
[0051]
组合预测模型采用lstm-arima-xgboost组合预测模型。
[0052]
步骤2)、基于负荷特性和用电行为模式从完整原始数据集中获取用电数据特征;
[0053]
用电数据特征包括历史负荷特征、负荷聚合特征、负荷趋势特征、负荷偏离特征、星期类型特征、假期类型特征、季节类型特征和用电行为模式特征;
[0054]
具体的,1)、取前m天的完整原始数据集作为历史负荷特征,即历史负荷时间序列,m为正整数,且2≤m≤10。
[0055]
2)、从历史负荷时间序列中获取负荷聚合特征,负荷聚合特征包括日最大负荷、日最小负荷、日平均负荷、日负荷率、日最小负荷率、日峰谷差和日峰谷差率;具体的,将小时负荷序列以日的维度计算获取日最大负荷、日平均负荷、日负荷率、日最小负荷率、日峰谷差和日峰谷差率:
[0056]
日最大负荷为:
[0057]
日最小负荷为:
[0058]
日平均负荷为:
[0059]
日负荷率为:
[0060]
日最小负荷率为:
[0061]
日峰谷差为:
[0062]
日峰谷差率为:
[0063]
其中为第i日以小时为间隔的典型日记录中的负荷值。
[0064]
3)、计算负荷时间序列周期为7的指数加权移动平均值v
n
,构成负荷时间序列的趋势特征数据;具体的:从日负荷序列中计算历史负荷序列中第n项的指数加权移动平均值v
n
:v
n
=βv
n-1
+(1-β)θ
n
ꢀꢀ
(8)
[0065]
其中,θ
n
为第n项的实际负荷值,系数β表示加权下降的快慢,值越小权重下降的越快,在本实例中,取β=0.95。
[0066]
4)、计算电力负荷场景下的kdj(随机指标)值,以表征一段时间内负荷序列的偏离情况,即负荷偏离特征,并将该数据作为负荷序列的偏离特征;kdj(随机指标)值融合了动量观念,强弱指标和移动平均线的一些优点,能够比较迅速、快捷、直观地表征序列偏离正常值的程度。具体的:根据电力负荷场景下的各指标对kdj值计算进行调整和优化,以反映一段时间内负荷序列的偏离情况:
[0067]
首先计算未成熟随机值(raw stochastic value,rsv):
[0068][0069]
其中n(单位:天数)是一个时间窗口,c为当天日小时负荷的平均值,h
n
是过去n日最大负荷的最大值,l
n
是过去n日最小负荷的最小值;
[0070][0071][0072][0073]
利用rsv值进一步求出k值、d值和j值:
[0074][0075]
若无前一日k值与d值,则k值与d值均取50。
[0076]
5)、对历史负荷时间序列的星期属性、节假日属性和季节属性赋值,其中节假日取2016年12月至2010年11月的法定节假日,季节属性按季节划分标准划分;星期属性、节假日属性和季节属性分别构成负荷数据的星期类型特征、假期类型特征和季节类型特征。
[0077]
6)、利用k-means聚类方法根据用户日负荷曲线特性对用户进行分类,挖掘历史数据中蕴含的用电行为信息。为了保证负荷特性的可比性,更准确的提取用户用电行为模式特征,以每日最大负荷为基数对日负荷曲线进行归一化处理,消除数据的幅值大小差异;聚类结果如图1所示,由5个类别中心曲线形状,可以看出类型二(cluster2)和类型三(cluster3)为比较典型的日负荷曲线,即有明显的早晚两个高峰,类型二早高峰用电量略高于晚高峰的用电量,为正常工作日用电情况,类型三早高峰用电量略低于晚高峰的用电量,为周末和夏季高峰用电月份。类型一(cluster1)全天用电量都较高,主要包含重大节日。类型四(cluster4)全天用电量都较低,类型五(cluster5)白天用电量高于夜晚,但是白天的用电量无明显的早晚高峰,这可能与用户特殊的用电行为有关。我们据此定义五种用
电行为模式,分别用norm1,norm2,high,low,no-peak来标识。
[0078]
将步骤2)~4)得到的负荷聚合特征数据、负荷趋势特征和负荷偏离特征进行0-1标准化处理,以消除量纲对网络训练的影响,同时加快梯度下降的求解速度,提升模型的收敛速度,将步骤5)~6)得到的星期类型、假期类型和季节类型构成的时间特性,以及用户用电行为模式构成的行为特性进行one-hot编码,将类别特征的取值扩展到欧式空间,使得特征之间距离的计算更加合理和准确。
[0079]
步骤3)、基于pca方法将负荷聚合特征进行降维处理得到四维特征向量;具体为:沿着数据差异最大的方向构建新的坐标系,将原有的数据映射到新的坐标系上,数据差异最大的方向即方差最大的方向。
[0080]
步骤4)、将完整原始数据集通过差分变换和指数加权移动平均处理得到平稳序列,使用arima模型对平稳序列进行学习得到预测序列,采用降维处理后得到的四维特征向量结合预测序列对组合预测模型进行训练并验证,验证目的是确认训练后的组合模型能够精准预测家庭负荷,利用训练完成的组合预测模型实现家庭负荷预测。
[0081]
如图3、图4所示,首先采用增广迪基-福勒检验(augmented dickey-fuller test,adf),以及jung-box白噪声检验来检验原始负荷时间序列的平稳性,将完整原始数据集通过差分变换和指数加权移动(exponentially-weighted moving average)平均处理得到平稳序列f1,使用arima模型进行学习得到预测序列s
n+1
,将预测序列s
n+1
作为新的特征加入pca降维后的四维特征f2中形成组合特征f3,将组合特征f3分别作为xgboost_1层和xgboost_2层的输入特征,将xgboost_1层的输出结果加入组合特征f3中构成组合特征f4,将组合特征f4作为第三层lstm的输入特征进行模型训练;最终模型使用第一层arima的结果s
n+1
,第二层xgboost_2的结果g
n+1
和第三层lstm的预测结果l
n+1
进行加权融合作为组合预测结果f
n+1
。将预测日的前m天的负荷数据时间序列,按照步骤2)~3)处理得到高维特征,输入步骤4)训练好的组合模型,模型对各组特征进行预测,组合加权即得到最终的家庭电力负荷预测值。
[0082]
本发明针对家庭用电负荷预测的特征工程构建方法,通过数据清洗、样本数据所属类别标签化、特征构造、特征提取以及采样平衡化等步骤完成训练样本的构建。本发明构造了基于电力系统运行特性的日负荷聚合特征、ewma趋势特征、kdj偏离特征、用电行为模式特征等负荷变化特征。本发明构建的特征能够从不同维度捕捉用户用电的行为习惯,从而较好的预测出家庭用电负荷中波动和不确定的成分。
[0083]
一种基于负荷特性和用电行为模式的家庭负荷预测系统,包括预处理模型、特征提取模块、降维处理模块和预测模块;
[0084]
预处理模型用于将采集到的家庭原始用电负荷时间序列整理得到原始数据集,并对原始数据集进行预处理得到完整原始数据集;
[0085]
特征提取模块用于从完整原始数据集中获取历史负荷特征和负荷聚合特征,降维处理模块用于将特征提取模块获取的负荷聚合特征进行降维处理得到四维特征向量;
[0086]
预测模块用于将完整原始数据集通过差分变换和指数加权移动平均处理得到平稳序列,然后对平稳序列进行学习得到预测序列,将降维处理后得到的四维特征向量结合预测序列对组合预测模型进行训练并验证,利用训练完成的组合预测模型实现家庭负荷预测。
[0087]
模型融合是一种非常有效的技术,可以在大部分的机器学习任务中提高回归或者分类的准确性。可以直接使用不同模型的结果进行融合,也可以使用一个模型的预测结果作为另一个模型的特征进行训练,然后得到新的预测结果。本发明中,我们综合使用了这两种融合方法,设计了arima-xgboost-lstm多层组合预测模型。不同类型的模型学习训练的原理不同,所学到的知识也不一样。不同的模型可能在不同的方面学习能力不一样。树模型(xgboost)以及lstm单模型的学习能力都较强,arima在处理线性模型效果较好,lstm神经网络可以通过学习来拟合非线性问题,xgboost模型则可以挖掘多维变量中不同维度的属性,通过不同模型的组合,大大提高了模型的泛化性能,预测能力进一步增强。本发明以uci数据库中的个体家庭用户用电量数据集为例,结果如图5所示,通过实验验证其效果超越现有先进方法的预测精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1