文档问答对拆分方法、装置、电子设备及存储介质与流程
本发明涉及人工智能技术领域,尤其涉及一种文档问答对拆分方法、装置、电子设备及计算机可读存储介质。
背景技术:
问答机器人是解决用户关于业务疑问的重要途径,在各种领域的各种业务中广泛使用。问答机器人有一个问答对知识库,所述问答对知识库由问答对组成,问答对即一对问题-答案。问答机器人的工作流程是:用户在问答模块中输入提问的自然表述,机器人在问答对知识库中搜索,匹配出与用户的自然表述最相近的问题,从而获取该问题的答案,并将所述答案返回给用户。因此,问答机器人能否回答用户的问题很大程度上取决于问答对知识库的丰富度和准确度。通常,所述问答对知识库中的问答对采用对各种类型的文档进行拆分得到。
现有技术中,通过下述方式进行问答对拆分:1、人工阅读一篇业务文档,在每个段落中找到重点知识,该重点知识即答案,再根据答案拟出问题,此方法效率较低。2、先根据词频找到文档的关键词,把关键词作为答案,再根据关键词生成问题,此方法的弊端是关键词容易找错,从而生成不准确的问答对。3、套用问题模板如“xx活动时间”、“xx产品介绍”,则生成的问题比较生硬,亦会有语句不通顺、逻辑不正确的可能。
技术实现要素:
本发明提供一种文档问答对拆分方法、装置及计算机可读存储介质,其主要目的在于解决问答对拆分效率较低及准确性较低的问题。
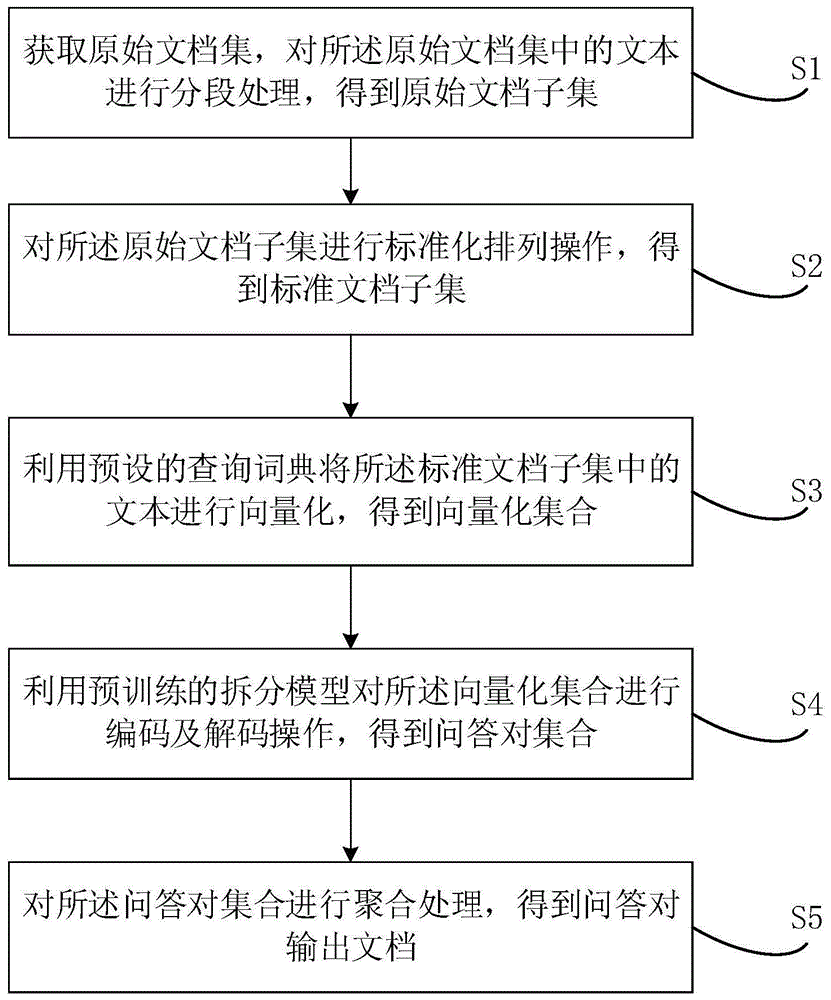
为实现上述目的,本发明提供的一种文档问答对拆分方法,包括:
获取原始文档集,对所述原始文档集中的文本进行分段处理,得到原始文档子集;
对所述原始文档子集进行标准化排列操作,得到标准文档子集;
利用预设的查询词典将所述标准文档子集中的文本进行向量化,得到向量化集合;
利用预训练的拆分模型对所述向量化集合进行编码及解码操作,得到问答对集合;
对所述问答对集合进行聚合处理,得到问答对输出文档。
可选地,所述对所述原始文档集中的文本进行分段处理,得到原始文档子集,包括:
根据预设的标题长度对所述原始文档集中的标题文本进行切分,得到标准标题;
根据预设的篇章长度对所述原始文档集中的正文文本进行划分,得到标准篇章;
将所述标准标题及所述标准篇章进行组合并转化为预设格式,得到所述原始文档子集。
可选地,所述对所述原始文档子集进行标准化排列操作,得到标准文档子集,包括:
提取每个所述原始文档子集中的标准标题及标准篇章;
利用预设的间隔符对所述标准标题及所述标准篇章进行标准化排列,得到标准文档子集。
可选地,所述根据利用预设的查询词典将所述标准文档子集中的文本进行向量化,得到向量化集合,包括:
对所述标准文档子集中的文本进行分字处理,得到字符集合,及对所述查询词典进行简化处理,得到简化查询词典;
利用所述简化查询词典将所述字符集合中的每一个字符进行向量化,得到所述向量化集合。
可选地,所述利用预训练的拆分模型对所述向量化集合进行编码及解码操作,得到问答对集合,包括:
利用所述拆分模型中的注意机制对所述向量化集合进行编码,得到增强向量;
根据预设的答案解码方法对所述增强向量进行粗筛、细筛,得到标准答案;
将所述标准答案拼接到所述增强向量中,根据预设的问题解码方法对拼接后的增强向量进行解码,得到标准问题;
汇总所述标准答案及所述标准问题,得到所述问答对集合。
可选地,所述利用预训练的拆分模型对所述向量化集合进行编码及解码操作之前,还包括:
利用预设的外部训练样本训练预构建的第一语言模型;
将所述第一语言模型的参数作为预构建的第二语言模型的初始化参数,并利用预设的内部训练样本训练所述第二语言模型,得到所述拆分模型。
可选地,所述对所述问答对集合进行聚合处理,得到问答对输出文档,包括:
抽取所述问答对集合中的标准问题和标准答案;
将所述标准问题及所述标准答案结构化成数据结构格式,保存至预设的文档中,得到所述问答对输出文档。
为了解决上述问题,本发明还提供一种文档问答对拆分装置,所述装置包括:
文本分段模块,用于获取原始文档集,对所述原始文档集中的文本进行分段处理,得到原始文档子集;
文本标准化模块,用于对所述原始文档子集进行标准化排列操作,得到标准文档子集;
文本向量化模块,用于利用预设的查询词典将所述标准文档子集中的文本进行向量化,得到向量化集合;
问答对拆分模块,用于利用预训练的拆分模型对所述向量化集合进行编码及解码操作,得到问答对集合;
文档输出模块,用于对所述问答对集合进行聚合处理,得到问答对输出文档。
为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
存储器,存储至少一个指令;及
处理器,执行所述存储器中存储的指令以实现上述所述的文档问答对拆分方法。
为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现上述所述的文档问答对拆分方法。
本发明通过对所述原始文档集中的文本进行分段处理,得到预设格式的所述原始文档子集,易于解析的同时可以降低数据传输的带宽压力。并且通过所述标准化排列操作,可以使所述标准文档子集中的文本数据标准化排列,使得所述文本数据向量化、编码及解码更加方便。同时预训练的拆分模型结合了外部训练样本及内部训练样本,使得所述拆分模型能够准确的将文档中的知识点拆分为问答对。因此,本发明提出的文档问答对拆分方法、装置、电子设备及计算机可读存储介质,可以解决问答对拆分效率较低及准确性较低的问题。
附图说明
图1为本发明一实施例提供的文档问答对拆分方法的流程示意图;
图2为图1中其中一个步骤的详细实施流程示意图;
图3为图1中另一个步骤的详细实施流程示意图;
图4为图1中另一个步骤的详细实施流程示意图;
图5为图1中另一个步骤的详细实施流程示意图;
图6为图1中另一个步骤的详细实施流程示意图;
图7为一种基金定投文档问答对拆分的效果示意图;
图8为本发明一实施例提供的文档问答对拆分装置的功能模块图;
图9为本发明一实施例提供的实现所述文档问答对拆分方法的电子设备的结构示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本申请实施例提供一种文档问答对拆分方法。所述文档问答对拆分方法的执行主体包括但不限于服务端、终端等能够被配置为执行本申请实施例提供的该方法的电子设备中的至少一种。换言之,所述文档问答对拆分方法可以由安装在终端设备或服务端设备的软件或硬件来执行,所述软件可以是区块链平台。所述服务端包括但不限于:单台服务器、服务器集群、云端服务器或云端服务器集群等。
参照图1所示,为本发明一实施例提供的文档问答对拆分方法的流程示意图。在本实施例中,所述文档问答对拆分方法包括:
s1、获取原始文档集,对所述原始文档集中的文本进行分段处理,得到原始文档子集。
在本发明的至少一个实施例中,所述原始文档集可以为各种领域的业务文档。本发明实施例中,所述原始文档集为金融领域的业务文档。详细地,所述金融领域的业务文档可以包括:基金定投文档、贷款业务文档及保险定投文档等。所述分段处理是指对于原始文档中的标题、正文等部分,根据预设的标题长度及篇章长度进行切分。
较佳地,参考图2所示,所述对所述原始文档集中的文本进行分段处理,得到原始文档子集,包括:
s10、根据预设的标题长度对所述原始文档集中的标题文本进行切分,得到标准标题;
s11、根据预设的篇章长度对所述原始文档集中的正文文本进行划分,得到标准篇章;
s12、将所述标准标题及所述标准篇章进行组合并转化为预设格式,得到所述原始文档子集。
可选地,本发明实施例中,所述预设格式可以为json格式,所述json格式是一种轻量级的数据交换格式,易于阅读和理解,也易于计算机解析和生成。
详细地,所述根据预设的标题长度对所述原始文档集中的标题文本进行切分,包括:
若所述标题文本小于或等于所述标题长度,则不对所述标题文本作处理;
若所述标题文本大于所述标题长度,则按照所述标题长度对所述标题文本直接截断,保留等于所述标题长度的前半部分。
进一步地,所述根据预设的篇章长度对所述原始文档集中的正文文本进行划分,包括:
若所述正文文本小于或等于所述篇章长度,则不对所述正文文本作处理;
若所述正文文本大于所述篇章长度,则按照预设的分句法对所述正文文本进行分句,直至分句后的总长度小于或等于所述篇章长度。
其中,所述预设的分句法是指先按照句子结束符号(如:“。”,“?”,“!”等)进行分句,若分句后的句子长度小于或等于所述篇章长度,则停止分句,否则再按照句子分隔符号(如:“,”,“;”等)进行分句,直至分句后的句子长度小于或等于所述篇章长度。本发明实施例中,所述预设的标题长度可以为32,所述预设的篇章长度可以为384。本发明实施通过对所述原始文档集中的文本进行分段处理,得到预设格式的所述原始文档子集,易于解析的同时可以降低数据传输的带宽压力。
s2、对所述原始文档子集进行标准化排列操作,得到标准文档子集。
较佳地,参考图3所示,所述对所述原始文档子集进行标准化排列操作,得到标准文档子集,包括:
s20、提取每个所述原始文档子集中的标准标题及标准篇章;
s21、利用预设的间隔符对所述标准标题及所述标准篇章进行标准化排列,得到标准文档子集。
可选地,本发明实施例中,所述间隔符可以为[cls]及[sep],其中,[cls]用来放在第一个句子的首位,[sep]用来分开所述标准标题及所述标准篇章,所述标准化排列后的格式为:[cls]标准标题[sep]标准篇章[sep]。
本发明实施例通过上述标准化排列操作,可以使标准文档子集中的文本数据标准化排列,使得所述文本数据向量化、编码及解码更加方便。
s3、利用预设的查询词典将所述标准文档子集中的文本进行向量化,得到向量化集合。
较佳地,所述预设的查询词典可以为vocab词典。本发明其中一个实施例中,在利用预设的查询词典将所述标准文档子集中的文本进行向量化之前,还包括:对所述标准文档子集中的文本进行分词。中文的分词实际上是分字,将每一个字都切开。
本发明其中一个实施例中,为了提高向量化速度,可以对所述vocab词典进行精简处理,即将所述vocab词典中长度大于1且包含标点符号的长字符串去掉,得到精简后的查询词典。
详细地,参阅图4所示,所述s3具体包括:
s30、对所述标准文档子集中的文本进行分字处理,得到字符集合,及对所述查询词典进行简化处理,得到简化查询词典;
s31、利用所述简化查询词典将所述字符集合中的每一个字符进行向量化,得到所述向量化集合。
本发明实施例中,所述向量化集合中包括三个向量:标记嵌入(tokenembeddings)、段落嵌入(segmentembeddings)及位置嵌入(positionembeddings)。其中,标记嵌入(tokenembeddings)为每个字符经过所述查询词典转换而成的一维向量,段落嵌入(segmentembeddings)表示每个字符属于标题、篇章的哪个部分,位置嵌入(positionembeddings)表示每个字符的位置信息。
本发明实施例,通过精简所述查询词典得到简化查询词典,利用所述简化查询词典进行向量化处理,可以降低对计算机计算资源的占用,提高向量化速度。
s4、利用预训练的拆分模型对所述向量化集合进行编码及解码操作,得到问答对集合。
本发明实施例中,所述拆分模型可以是一个bert(bidirectionalencoderrepresentationfromtransformers)预训练模型。
可选地,在利用预训练的拆分模型对所述向量化集合进行编码及解码操作之前,本发明还包括:
利用预设的外部训练样本训练预构建的第一语言模型;
将所述第一语言模型的参数作为预构建的第二语言模型的初始化参数,并利用预设的内部训练样本训练所述第二语言模型,得到所述拆分模型。
其中,所述外部训练样本可以从百度开源的webqa数据集和搜狗开源的sogouqa数据集获取,所述内部训练样本可以为各业务领域的业务文档,比如,真实场景下的银行业务文档。所述第一语言模型及所述第二语言模型均可以为bert预训练模型chinese_l-12_h-768_a-12。所述第一语言模型训练时,外部训练样本的数据格式为:[cls]篇章[sep]答案[ansend]问题[quesend],第二语言模型训练时,内部训练样本的数据格式为:[cls]标题[sep]篇章[sep]答案[ansend]问题[quesend]。本发明实施例中,可以设置标题长度为32,篇章长度为384,问题长度为32,答案长度为64。
较佳地,参阅图5所示,所述s4包括:
s40、利用所述拆分模型中的注意机制对所述向量化集合进行编码,得到增强向量;
s41、根据预设的答案解码方法对所述增强向量进行粗筛、细筛,得到标准答案;
s42、将所述标准答案拼接到所述增强向量中,根据预设的问题解码方法对拼接后的增强向量进行解码,得到标准问题;
s43、汇总所述标准答案及所述标准问题,得到所述问答对集合。
其中,所述注意(attention)机制中包括一种attentionmask,所述attentionmask是一个矩阵,逐字生成时,将已生成的上文字符部分置0,未生成的下文字符部分置-∞,让模型看不到下文字符,即保证生成时下文字符不泄露,可以增强模型编码能力。本发明实施例将得到的所述标准答案后加入“[ansend]”标识,所述“[ansend]”标识用来标识问答对中答案结束位,得到的所述标准问题后加入“[quesend]”标识,所述“[quesend]”标识用来标识问答对中问题结束位。所述拆分模型按照先解码答案,再解码问题的顺序,特殊标识“[ansend]”可确定什么时候答案解码完毕,答案解码完毕即问题解码开始,“[quesend]”标识可确定什么时候问题解码完毕,问题解码完毕即模型停止生成任务。本发明实施例中,所述预设的答案解码方法可以为top-k采样(top-ksampling)及核采样(nucleussampling)的方法,所述top-k采样(top-ksampling)用来做粗筛,所述核采样(nucleussampling)用来做细筛。所述预设的问题解码方法可以为束搜索(beamsearch)解码方法。
本发明实施例中,所述预训练的拆分模型结合了外部训练样本及内部训练样本,使得所述拆分模型能够准确的将文档中的知识点拆分为问答对。
s5、对所述问答对集合进行聚合处理,得到问答对输出文档。
本发明实施例中,所述聚合处理是指将得到的所述问答对进行格式转化,并保存至预设的文档,得到所述问答对输出文档,便于导入问答机器人的问答对知识库中。
较佳地,参阅图6所示,所述s5包括:
s50、抽取所述问答对集合中的标准问题和标准答案;
s51、将所述标准问题及所述标准答案结构化成数据结构格式,保存至预设的文档中,得到所述问答对输出文档。
可选地,所述数据结构格式可以为dataframe格式,所述dataframe格式是一个表格型的数据结构。所述预设的文档可以为excel文档,所述excel文档包括4列,分别为faqid(该问答对编号)、question(问题)、answer(答案)和origsentence(问答对来源于哪个段落的哪个分句)。比如,如图7所示的在金融领域中,基金定投文档按照步骤s1至s5的问答对拆分效果,按照所述基金定投文档中的业务介绍,拆分出的其中一条问答对为:问题:平安银行的定投类业务有哪些?答案:智能定投业务、溢财宝业务。并将所述问答对保存至预设的excel文档。
本发明通过对所述原始文档集中的文本进行分段处理,得到预设格式的所述原始文档子集,易于解析的同时可以降低数据传输的带宽压力,通过所述标准化排列操作,可以使所述标准文档子集中的文本数据标准化排列,使得所述文本数据向量化、编码及解码更加方便。同时预训练的拆分模型结合了外部训练样本及内部训练样本,使得所述拆分模型能够准确的将文档中的知识点拆分为问答对。因此本发明提出的实施例可以解决问答对拆分效率较低及准确性较低的问题。
如图8所示,是本发明一实施例提供的文档问答对拆分装置的功能模块图。
本发明所述文档问答对拆分装置100可以安装于电子设备中。根据实现的功能,所述文档问答对拆分装置100可以包括文本分段模块101、文本标准化模块102、文本向量化模块103、问答对拆分模块104及文档输出模块105。本发明所述模块也可以称之为单元,是指一种能够被电子设备处理器所执行,并且能够完成固定功能的一系列计算机程序段,其存储在电子设备的存储器中。
在本实施例中,关于各模块/单元的功能如下:
所述文本分段模块101,用于获取原始文档集,对所述原始文档集中的文本进行分段处理,得到原始文档子集。
在本发明的至少一个实施例中,所述原始文档集可以为各种领域的业务文档。本发明实施例中,所述原始文档集为金融领域的业务文档。详细地,所述金融领域的业务文档可以包括:基金定投文档、贷款业务文档及保险定投文档等。所述分段处理是指对于原始文档中的标题、正文等部分,根据预设的标题长度及篇章长度进行切分。
较佳地,所述文本分段模块101通过下述操作得到所述得到原始文档子集:
根据预设的标题长度对所述原始文档集中的标题文本进行切分,得到标准标题;
根据预设的篇章长度对所述原始文档集中的正文文本进行划分,得到标准篇章;
将所述标准标题及所述标准篇章进行组合并转化为预设格式,得到所述原始文档子集。
可选地,本发明实施例中,所述预设格式可以为json格式,所述json格式是一种轻量级的数据交换格式,易于阅读和理解,也易于计算机解析和生成。
详细地,所述文本分段模块101通过下述操作对所述原始文档集中的标题文本进行切分:
若所述标题文本小于或等于所述标题长度,则不对所述标题文本作处理;
若所述标题文本大于所述标题长度,则按照所述标题长度对所述标题文本直接截断,保留等于所述标题长度的前半部分。
进一步地,所述文本分段模块101通过下述操作对所述原始文档集中的正文文本进行划分:
若所述正文文本小于或等于所述篇章长度,则不对所述正文文本作处理;
若所述正文文本大于所述篇章长度,则按照预设的分句法对所述正文文本进行分句,直至分句后的总长度小于或等于所述篇章长度。
其中,所述预设的分句法是指先按照句子结束符号(如:“。”,“?”,“!”等)进行分句,若分句后的句子长度小于或等于所述篇章长度,则停止分句,否则再按照句子分隔符号(如:“,”,“;”等)进行分句,直至分句后的句子长度小于或等于所述篇章长度。本发明实施例中,所述预设的标题长度可以为32,所述预设的篇章长度可以为384。本发明实施通过对所述原始文档集中的文本进行分段处理,得到预设格式的所述原始文档子集,易于解析的同时可以降低数据传输的带宽压力。
所述文本标准化模块102,用于对所述原始文档子集进行标准化排列操作,得到标准文档子集。
较佳地,所述文本标准化模块102通过下述操作得到所述标准文档子集:
提取每个所述原始文档子集中的标准标题及标准篇章;
利用预设的间隔符对所述标准标题及所述标准篇章进行标准化排列,得到标准文档子集。
可选地,本发明实施例中,所述间隔符可以为[cls]及[sep],其中,[cls]用来放在第一个句子的首位,[sep]用来分开所述标准标题及所述标准篇章,所述标准化排列后的格式为:[cls]标准标题[sep]标准篇章[sep]。
本发明实施例通过上述标准化排列操作,可以使标准文档子集中的文本数据标准化排列,使得所述文本数据向量化、编码及解码更加方便。
所述文本向量化模块103,用于利用预设的查询词典将所述标准文档子集中的文本进行向量化,得到向量化集合。
较佳地,所述预设的查询词典可以为vocab词典。本发明其中一个实施例中,在利用预设的查询词典将所述标准文档子集中的文本进行向量化之前,还包括:对所述标准文档子集中的文本进行分词。中文的分词实际上是分字,将每一个字都切开。
本发明其中一个实施例中,为了提高向量化速度,可以对所述vocab词典进行精简处理,即将所述vocab词典中长度大于1且包含标点符号的长字符串去掉,得到精简后的查询词典
详细地,所述文本向量化模块103通过下述操作得到所述向量化集合:
对所述标准文档子集中的文本进行分字处理,得到字符集合,及对所述查询词典进行简化处理,得到简化查询词典;
利用所述简化查询词典将所述字符集合中的每一个字符进行向量化,得到所述向量化集合。
本发明实施例中,所述向量化集合中包括三个向量:标记嵌入(tokenembeddings)、段落嵌入(segmentembeddings)及位置嵌入(positionembeddings)。其中,标记嵌入(tokenembeddings)为每个字符经过所述查询词典转换而成的一维向量,段落嵌入(segmentembeddings)表示每个字符属于标题、篇章的哪个部分,位置嵌入(positionembeddings)表示每个字符的位置信息。
本发明实施例,通过精简所述查询词典得到简化查询词典,利用所述简化查询词典进行向量化处理,可以降低对计算机计算资源的占用,提高向量化速度。
所述问答对拆分模块104,用于利用预训练的拆分模型对所述向量化集合进行编码及解码操作,得到问答对集合。
本发明实施例中,所述拆分模型可以是一个bert(bidirectionalencoderrepresentationfromtransformers)预训练模型。
可选地,所述问答对拆分模块104在利用预训练的拆分模型对所述向量化集合进行编码及解码操作之前还包括:
利用预设的外部训练样本训练预构建的第一语言模型;
将所述第一语言模型的参数作为预构建的第二语言模型的初始化参数,并利用预设的内部训练样本训练所述第二语言模型,得到所述拆分模型。
其中,所述外部训练样本可以从百度开源的webqa数据集和搜狗开源的sogouqa数据集获取,所述内部训练样本可以为各业务领域的业务文档,比如,真实场景下的银行业务文档。所述第一语言模型及所述第二语言模型均可以为bert预训练模型chinese_l-12_h-768_a-12。所述第一语言模型训练时,外部训练样本的数据格式为:[cls]篇章[sep]答案[ansend]问题[quesend],第二语言模型训练时,内部训练样本的数据格式为:[cls]标题[sep]篇章[sep]答案[ansend]问题[quesend]。本发明实施例中,可以设置标题长度为32,篇章长度为384,问题长度为32,答案长度为64。
较佳地,所述问答对拆分模块104通过下述操作得到所述问答对集合:
利用所述拆分模型中的注意机制对所述向量化集合进行编码,得到增强向量;
根据预设的答案解码方法对所述增强向量进行粗筛、细筛,得到标准答案;
将所述标准答案拼接到所述增强向量中,根据预设的问题解码方法对拼接后的增强向量进行解码,得到标准问题;
汇总所述标准答案及所述标准问题,得到所述问答对集合。
其中,所述注意(attention)机制中包括一种attentionmask,所述attentionmask是一个矩阵,逐字生成时,将已生成的上文字符部分置0,未生成的下文字符部分置-∞,让模型看不到下文字符,即保证生成时下文字符不泄露,可以增强模型编码能力。本发明实施例将得到的所述标准答案后加入“[ansend]”标识,所述“[ansend]”标识用来标识问答对中答案结束位,得到的所述标准问题后加入“[quesend]”标识,所述“[quesend]”标识用来标识问答对中问题结束位。所述拆分模型按照先解码答案,再解码问题的顺序,特殊标识“[ansend]”可确定什么时候答案解码完毕,答案解码完毕即问题解码开始,“[quesend]”标识可确定什么时候问题解码完毕,问题解码完毕即模型停止生成任务。本发明实施例中,所述预设的答案解码方法可以为top-k采样(top-ksampling)及核采样(nucleussampling)的方法,所述top-k采样(top-ksampling)用来做粗筛,所述核采样(nucleussampling)用来做细筛。所述预设的问题解码方法可以为束搜索(beamsearch)解码方法。
本发明实施例中,所述预训练的拆分模型结合了外部训练样本及内部训练样本,使得所述拆分模型能够准确的将文档中的知识点拆分为问答对。
所述文档输出模块105,用于对所述问答对集合进行聚合处理,得到问答对输出文档。
本发明实施例中,所述聚合处理是指将得到的所述问答对进行格式转化,并保存至预设的文档,得到所述问答对输出文档,便于导入问答机器人的问答对知识库中。
较佳地,所述文档输出模块105通过下述操作得到所述问答对输出文档:
抽取所述问答对集合中的标准问题和标准答案;
将所述标准问题及所述标准答案结构化成数据结构格式,保存至预设的文档中,得到所述问答对输出文档。
可选地,所述数据结构格式可以为dataframe格式,所述dataframe格式是一个表格型的数据结构。所述预设的文档可以为excel文档,所述excel文档包括4列,分别为faqid(该问答对编号)、question(问题)、answer(答案)和origsentence(问答对来源于哪个段落的哪个分句)。比如,在金融领域中,基金定投文档按照模块101至105进行拆分,按照所述基金定投文档中的业务介绍,拆分出的其中一条问答对为:问题:平安银行的定投类业务有哪些?答案:智能定投业务、溢财宝业务。并将所述问答对保存至预设的excel文档。
如图9所示,是本发明一实施例提供的实现文档问答对拆分方法的电子设备的结构示意图。
所述电子设备1可以包括处理器10、存储器11和总线,还可以包括存储在所述存储器11中并可在所述处理器10上运行的计算机程序,如文档问答对拆分程序12。
其中,所述存储器11至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、移动硬盘、多媒体卡、卡型存储器(例如:sd或dx存储器等)、磁性存储器、磁盘、光盘等。所述存储器11在一些实施例中可以是电子设备1的内部存储单元,例如该电子设备1的移动硬盘。所述存储器11在另一些实施例中也可以是电子设备1的外部存储设备,例如电子设备1上配备的插接式移动硬盘、智能存储卡(smartmediacard,smc)、安全数字(securedigital,sd)卡、闪存卡(flashcard)等。进一步地,所述存储器11还可以既包括电子设备1的内部存储单元也包括外部存储设备。所述存储器11不仅可以用于存储安装于电子设备1的应用软件及各类数据,例如文档问答对拆分程序12的代码等,还可以用于暂时地存储已经输出或者将要输出的数据。
所述处理器10在一些实施例中可以由集成电路组成,例如可以由单个封装的集成电路所组成,也可以是由多个相同功能或不同功能封装的集成电路所组成,包括一个或者多个中央处理器(centralprocessingunit,cpu)、微处理器、数字处理芯片、图形处理器及各种控制芯片的组合等。所述处理器10是所述电子设备的控制核心(controlunit),利用各种接口和线路连接整个电子设备的各个部件,通过运行或执行存储在所述存储器11内的程序或者模块(例如文档问答对拆分程序等),以及调用存储在所述存储器11内的数据,以执行电子设备1的各种功能和处理数据。
所述总线可以是外设部件互连标准(peripheralcomponentinterconnect,简称pci)总线或扩展工业标准结构(extendedindustrystandardarchitecture,简称eisa)总线等。该总线可以分为地址总线、数据总线、控制总线等。所述总线被设置为实现所述存储器11以及至少一个处理器10等之间的连接通信。
图9仅示出了具有部件的电子设备,本领域技术人员可以理解的是,图9示出的结构并不构成对所述电子设备1的限定,可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。
例如,尽管未示出,所述电子设备1还可以包括给各个部件供电的电源(比如电池),可选地,电源可以通过电源管理装置与所述至少一个处理器10逻辑相连,从而通过电源管理装置实现充电管理、放电管理、以及功耗管理等功能。电源还可以包括一个或一个以上的直流或交流电源、再充电装置、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。所述电子设备1还可以包括多种传感器、蓝牙模块、wi-fi模块等,在此不再赘述。
进一步地,所述电子设备1还可以包括网络接口,可选地,所述网络接口可以包括有线接口和/或无线接口(如wi-fi接口、蓝牙接口等),通常用于在该电子设备1与其他电子设备之间建立通信连接。
可选地,该电子设备1还可以包括用户接口,用户接口可以是显示器(display)、输入单元(比如键盘(keyboard)),可选地,用户接口还可以是标准的有线接口、无线接口。可选地,在一些实施例中,显示器可以是led显示器、液晶显示器、触控式液晶显示器以及oled(organiclight-emittingdiode,有机发光二极管)触摸器等。其中,显示器也可以适当的称为显示屏或显示单元,用于显示在电子设备1中处理的信息以及用于显示可视化的用户界面。
应该了解,所述实施例仅为说明之用,在专利申请范围上并不受此结构的限制。
所述电子设备1中的所述存储器11存储的文档问答对拆分程序12是多个指令的组合,在所述处理器10中运行时,可以实现:
获取原始文档集,对所述原始文档集中的文本进行分段处理,得到原始文档子集;
对所述原始文档子集进行标准化排列操作,得到标准文档子集;
利用预设的查询词典将所述标准文档子集中的文本进行向量化,得到向量化集合;
利用预训练的拆分模型对所述向量化集合进行编码及解码操作,得到问答对集合;
对所述问答对集合进行聚合处理,得到问答对输出文档。
具体地,所述处理器10对上述指令的具体实现方法可参考图1至图7对应实施例中相关步骤的描述,在此不赘述。
进一步地,所述电子设备1集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个非易失性计算机可读取存储介质中。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-onlymemory)。
在本发明所提供的几个实施例中,应该理解到,所揭露的设备,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能模块的形式实现。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。
因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本发明内。不应将权利要求中的任何附关联图标记视为限制所涉及的权利要求。
本发明所指区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层等。
此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。系统权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第二等词语用来表示名称,而并不表示任何特定的顺序。
最后应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或等同替换,而不脱离本发明技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!