一种用于消防通道占用检测的系统的制作方法
1.本发明涉及一种基于人工智能图像识别技术的消防通道占用检测系统。
背景技术:
2.近年来,安全问题日益突出,人们越来越关注居住环境和工作环境的安全问题。消防通道是设于公共区域的一种应急通道。当有火灾发生时,消防人员,消防车辆和消防设备要从消防通道进入,但如果消防通道被车辆或其他难以移动物品占用就可能造成延误火灾的救援,造成更大的经济损失和人员伤亡。目前大多数单位只是在消防通道前设立警示牌,一般靠人们自觉遵守。但大部分情况下大家都抱有侥幸心理将机动车停在消防通道而看守人员往往不能及时发现,此类现象很容易造成安全事故,给国家人民造成了巨大损失。
3.目前消防通道被占用自动识别主要有2种方法:
4.(1)基于布设传感器的方法:该方法通过红外、超声波、地磁等探测消防通道内障碍物,探测到障碍物时发出告警。但很多消防通道可能短时间有数辆车或人依次通过的场景,在该情况下,这些传感器会实时探测到障碍物,形成频繁误报或误判,无法使用。
5.(2)基于监控图片与基准图片差异值比对的方法:将消防通道未占用的图片作为基准图片,与实时监控拍摄的图片进行比对,如果差异面积百分比持续大于一个阈值,则认为发生占用。该技术方案无法准确识别占用消防通道的物体,会造成一系列误报:如当人流或车流大时,差异面积可能持续大于一个阈值,会形成误报;如有多个人员或动物在消防通道逗留一段时间等实际不会实质占用消防通道的场景可能形成误报。
6.基于以上原因,需要一种更高精度、更智能化的消防通道占用自动识别检测系统。
技术实现要素:
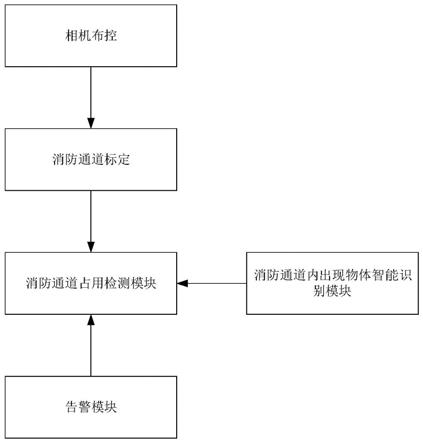
7.发明目的:针对现有自动化消防通道占用识别方法无法识别占用消防通道是人是物而造成误报、人流或车流较大的消防通道易将经过的车流或人流作为消防通道占用误报等不足,提出一种精准识别消防通道占用物体,占用通道的位置的智能化消防通道检测系统,本发明具体提出一种用于消防通道占用检测的系统,用于车辆或者其它杂物占用消防通道的检测。所述系统包括相机布控、消防通道标定模块、消防通道内出现物体智能识别模块、消防通道占用检测模块、告警模块;
8.所述相机布控,指架设相机对消防通道进行监控;
9.所述消防通道标定模块用于读取摄像头的相机视野,并以框图的形式标定消防通道的范围;
10.所述消防通道内出现物体智能识别模块,用于检测占用消防通道的目标;
11.所述消防通道占用检测模块,针对每一分钟读取的一帧相机拍摄的照片,利用消防通道内出现物体智能识别模块对照片中的物体进行识别与判别;
12.所述告警模块,用于对管理人员进行告警。
13.所述相机包括监控摄像头,还包括数据传输模块与语音告警模块;数据传输模块
每一分钟读取拍摄的一帧照片,通过4g或5g无线信号将数据传送至管理后台系统,语音告警模块能够根据管理后台系统发出的指令进行警告广播,要求占用消防通道的车辆等目标离开消防通道。
14.相机布控安装时要求相机视野覆盖整个消防通道。
15.所述消防通道内出现物体智能识别模块包括训练样本知识库和智能识别模型;
16.对经常出现(比如一天内出现3次以上)在消防通道内的人或物体包括大型汽车、中小型汽车、电瓶车、摩托车、人员、猫、狗、箱子、三轮车建立训练样本知识库,包括样本图片,存储位置、名称、样本图片尺寸,识别对象位置、尺寸,分类,图像通道数;
17.对yolov3深度神经网络模型进行改进,引入混合域注意力机制,利用yolov3深度神经网络模型对训练样本知识库进行训练,得到智能识别模型,通过智能识别模型检测占用消防通道的目标、位置与物体范围框图。
18.所述融合混合域注意力机制的改进的yolov3深度神经网络模型的具体结构包括:
19.骨干网络采用darknet53,用于提取图像细节特征;
20.提取3个不同层的特征图(结合后面的网络结构图来说,分别提取的是主干网络中的3处特征图,其特征图大小分别为13*13,26*26,52*52,分别适应不同大小的目标检测),大小分别为13*13,26*26,52*52,通过特征图映射原图从而进行目标的检测与分类(这是yolov3模型的一个属性,通过从主干网络提取的特征图上的点映射回原图,得到候选框位置,然后通过loss约束,不断训练优化模型);
21.加入混合域注意力机制,损失函数loss由4部分构成,分别是定位损失lbox、分类损失lcls和置信度损失lobj,目标遮挡损失lshe,其中定位损失和置信度损失、目标遮挡损失采用的是平方差损失,分类损失采用的是交叉熵损失,具体计算方式如下:
[0022][0023][0024][0025][0026]
loss=lbox+lshe+lcls+lobj
[0027]
其中,s2为网格大小,取值为13x13,26x26,52x52,b表示每个网格生成的候选框个数,x
i
,y
i
分别表示真实标注框左上角横坐标和纵坐标,w
i
,h
i
分别表示真实标注框的宽度和高度,分别为x
i
,y
i
的预测值,分别为w
i
,h
i
的预测值,x0和y0、w0与h0表示标定的待测消防通道区域信息(即提前标定的消防通道区域最小凸包四边形,其作用是构建lshe损失,使得模型检测到目标位置更加准确),loss表示整个网络的误差和;
[0028]
参数表示第i个网格第j个预测框是否在负责目标,如果是,则值为1,否则为0;
[0029]
参数如果在第i个网格第j个预测框处有目标,,值为0,否则为1;
[0030]
参数c
i
表示的是第i个网格处预测框的置信度,计算方式为当前预测框包含物体的概率和所述预测框与真实框交并比大小的乘积,而表示的是c
i
对应的预测值;
[0031]
参数p
i
表示的是第i个网格处的预测框目标类别,对应的为预测的类别信息;
[0032]
λ
coord
、λ
noobj
和λ
class
为损失系数,通过优化训练(即通过训练提升神经网络效果的过程,结合结果调整超参)融合混合域注意力机制的改进的yolov3深度神经网络模型,最终得到一个检测占用消防通道的目标的智能识别模型。
[0033]
所述消防通道占用检测模块针对每一分钟读取的一帧摄像头拍摄的照片,利用消防通道内出现物体智能识别模块对照片中的物体进行识别与判别,具体包括:对于人员、动物类则不进行后续识别,对车辆和其他可能造成消防通道堵塞的物体(比如箱子),判断其物体范围框图与标定消防通道范围框图的是否相交,如果相交将所述物体分类、物体中心位置、物体范围框图数据存储在待分类表中,取存储在待分类表中连续3张照片的数据,如果三张照片中有三个物体分类一致,物体中心位置与范围框图(这里的范围框图指的是模型检测到物体后得到的位置框图)大小的均值误差均不超过5%,则判定消防通道被占用。
[0034]
所述告警模块,用于对管理人员进行告警,包括:当发现消防通道被占用后,第一次以弹窗方式弹出相关照片及布控相机的位置信息给管理人员,并使用相机附带的语音告警模块以广播的方式通知占用车辆离开;如n(n一般为5)分钟后,相机监控区域仍有消防通道占用情况,以微信派单方式将占用照片,位置信息、占用时间信息发给消防通道附近管理人员以进行现场处理。
[0035]
有益效果:本发明方法可以准确有效的检测出消防通道占用情况,并能很好配合后台管理人员进行管理,同时可以结合新出现的消防通道占用情况补充训练数据集,从而增加模型检测的有效性和鲁棒性,相对于其他的检测方法,可以实现快速经济有效的检测,满足大部分场景检测需求。
附图说明
[0036]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0037]
图1为本发明架构示意图;
[0038]
图2为消防通道标定示意图
[0039]
图3a为本发明所述的融合混合域注意力机制的yolov3检测模型网络结构示意图;
[0040]
图3b为yolov3检测模型网络详细架构图。
[0041]
图4为本发明所述的检测约束关系示意图。
具体实施方式
[0042]
如图1所示,本实例提供一种用于消防通道占用检测的系统,包括:
[0043]
相机布控模块,针对监控的消防通道区域进行摄像机前期布控,保障待监测消防通道区域能完整呈现在相机的视野内。每一分钟可读取拍摄的一帧照片通过4g或5g无线信号将数据传送至管理后台系统。
[0044]
消防通道标定模块为一软件模块,可读取摄像头的相机视野,在其中以框图的形式人工标定消防通道的范围。如图2所示。
[0045]
消防通道内出现物体智能识别模块的训练样本知识库,样本初始数量在10000张左右,包括大型汽车、中小型汽车、电瓶车、摩托车、人员、猫、狗、箱子、三轮车的样本图片,对这些图片存储位置、名称、样本图片尺寸,识别对象位置、尺寸,分类进行标注。
[0046]
消防通道内出现物体智能识别模块的智能识别模型,如图3a所示,其中为convolutional与convs为常见卷积归一化块,filters表示卷积核的个数,size表示卷积核的大小,output表示操作后输出大小,/2表示2*2的最大池化,residual为残差卷积块,具体结构如右下所示,convolutional与residual组成的网络块前面系数表示该网络块的个数,sigmoid表示激活函数,maxpool表示最大值池化,avgpool表示平均池化,scale表示缩放函数,一般多采用对维度取根号,cbam表示混合域注意力机制,包括通道注意力机制和空间注意力机制,详细结构如图3b所示,对于标注好的样本数据,利用yolov3目标检测模型训练消防通道占用检测模型,保证网络模型输入为416*416的3通道图像,输出的结果为在图上预测框box,置信度cls,以及类别obj等信息。其中网络骨干采用的是darknet53,用于提取图像细节特征,提取3个不同层的特征图,大小分别为13*13,26*26,52*52,同时在darket53骨干网络中加入混合域注意力机制,提升模型对图像特征的提取效果,通过特征图映射到原图从而进行目标的检测与分类,通过构建定位损失、分类损失和置信度损失3个损失函数,前两者采用的是平方差损失,后者采用的是交叉熵损失,计算方式如下:
[0047][0048][0049][0050][0051]
loss=lbox+lshe+lcls+lobj
[0052]
其中,s代表网格大小,s2代表13x13,26x26,52x52,b表示每个网格生成的候选框个数,x
i
,y
i
分别表示真实标注框左上角横坐标和纵坐标,,w
i
,h
i
分别表示真实标注框的宽度和高度,分别为x
i
,y
i
的预测值,分别为w
i
,h
i
的预测值,x0和y0,w0与h0表示的为标定的待测消防通道区域信息,loss表示整个网络的误差和;
[0053]
参数表示第i个网格第j个预测框是否在负责目标,如果是则值为1,否则为0;
[0054]
参数如果在第i个网格第j个预测框处有目标,,值为0,否则为1;
[0055]
参数c
i
表示的是第i个网格处预测框的置信度,计算方式为当前预测框包含物体
的概率和该预测框与真实框交并比大小的乘积,而表示的是c
i
对应的预测值;
[0056]
参数p
i
表示的是第i个网格处的预测框目标类别,对应的为预测的类别信息;
[0057]
λ
coord
、λ
noobj
和λ
class
为损失系数,通过优化训练融合混合域注意力机制的yolov3神经网络模型,最终得到一个检测模型,能够准确检测出相机视野中的违占情况。
[0058]
通过损失函数来约束训练网络模型,最终得到一个比较理想的检测模型,能够准确检测出相机视野内出现的车辆、杂物等类别、位置信息与置信度。
[0059]
消防通道占用检测模块,针对每一分钟读取的一帧摄像头拍摄的照片,利用消防通道内出现物体智能识别模块型对该照片拍摄的物体进行识别与判别,对于人员、动物类则不进行后续识别,对车辆和其他可确实造成消防通道堵塞的物体,判断其范围框图与标定消防通道范围框图的是否相交。如相交将该物体分类、物体中心位置,物体范围框图数据存储在待分类表中,取存储在待分类表中连续3张照片的数据。如三张照片中有三个物体分类一致,位置与范围框图大小的均值误差均不超过5%,则认为消防通道被占用。如图4所示,连续3张照片中,每张照片中识别车辆的框图面积s1,s2,s3、框图中心位置(x1,y1),(x2,y2),(x3,y3)通过)通过计算,计算结果均不超过5%,则判定占用。
[0060]
告警模块,发现消防通道被占用后,第一次以弹窗方式弹出相关照片及布控相机的位置信息给管理人员,并使用相机附带的语音告警模块以广播的方式通知占用车辆离开。如5分钟后,该相机监控区域仍有消防通道占用情况,以微信派单方式将占用照片,位置信息、占用时间信息发给消防通道附近管理人员以进行现场处理。
[0061]
本发明提供了一种用于消防通道占用检测的系统,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1