一种动态调整量化featureclip值的方法与流程
一种动态调整量化feature clip值的方法
技术领域
1.本发明涉及图像处理技术领域,特别涉及一种动态调整量化feature clip值的方法。
背景技术:
2.传统技术中深度神经网络基于低bit训练过程中对feature进行clip值一律采用relu6进行量化,无法保证模型不同层的量化分布,从而导致模型在低bit量化位宽出现数据不能充分利用问题。量化就相当于将权重和损失函数空间离散化,因此,在模型训练中是可能弥补权重量化带来的误差的,传统的激活函数的没有任何可以训练的参数,因此,量化激活函数带来的误差无法在反向传播时被补偿掉。但是,使用clipping activation functio(relu6)的话,可以缓解上面提到的难题,因此relu6是有界的。然而由于模型与模型、层与层之间的区别,选择这个最好的clip value是很困难的。
3.现有技术中对float 32bit量化为低比特时,由于低bit模型位宽可用数据很少,同时过往的clip_value值过分注重一个值,使得模型的很难达到最优。
4.现有技术中的常用术语如下:
5.低比特量化:将权重和feature有32bit位宽定点化至(8bit、4bit、2bit)。
6.activation函数量化:实际中activation往往是占内存使用的大头,因此量化activation不仅可以大大减少memory footprint。更重要的是,结合weight的量化可以充分利用整数计算获得性能提升,如使用relu6对模型进行量化。
7.feature clip是对特征值的大小做裁剪,减去了过大的值,通常都是在因子进行了标准化之后进行的类似去极值处理。
8.bp算法(即反向传播算法)适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上。bp网络的输入输出关系实质上是一种映射关系:一个n输入m输出的bp神经网络所完成的功能是从n维欧氏空间向m维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。
技术实现要素:
9.为了解决上述问题,本方法的目的旨在给激活函数设定了一个可学习的值,相对于传统的relu6能够更加符合模型的层次分布,从而能够充分利用量化位宽。
10.(1)低bit量化位宽中为了使得模型位宽充分利用,从而对模型的clipvalue进行训练自适应;
11.(2)clip_value动态调整,每层设置不同的处理值,并且训练值。
12.具体地,本发明提供一种动态调整量化feature clip值的方法,所述方法是在每一层添加clip_value,动态调整量化的clip值:
13.假设第i层的量化计算如下所示:
[0014][0015][0016]
梯度反传值如下:
[0017][0018]
通过调整的大小,同时训练时对的变量添加l2的正则化,确保值训练时不至于过大,使得模型更易于收敛。
[0019]
所述的l2的正则化,即在对参数求取梯度反向传播,通过添加正则化参数,使得参数的更新在一个更小的范围内,网络的收敛更加稳定;
[0020][0021]
j为目标函数,即loss损失函数;
[0022]
h为网络的预测结果;
[0023]
y为真实标签结果;
[0024]
λ为正则化系数;
[0025]
θ为正则化参数,对参数进行求平方。
[0026]
所述调整的大小的方法包括:通过对网络的训练,即反向传播,学习模型参数,设置网络输出的损失函数loss;通过输入数据至网络,调节输出层的结果和真实值之间的偏差来进行逐层调节参数;该学习过程是一个不断迭代的过程,直到网络的loss达到最小值,求取最优的解。
[0027]
所述损失函数loss,包括l1 loss、l2 loss或者交叉熵损失函数。
[0028]
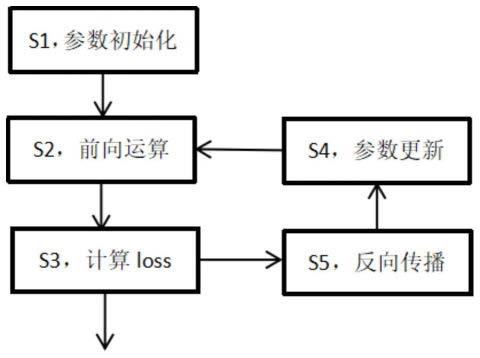
所述方法具体包括以下步骤:
[0029]
s1,参数初始化;
[0030]
s2,进行前向运算,采用步骤s4中的参数
[0031]
s3,计算loss,输出结果;
[0032]
s4,参数更新;
[0033]
s5,反向传播,进行步骤s4。
[0034]
所述s5的反向传播,通过对loss的目标函数进行求导,逐次迭代更新参数
[0035]
由此,本技术的优势在于:通过将clip value加入到模型量化的训练参数中,使得每一层自动化调适模型输出,使得模型量化更加符合模型层数分布,达到最佳的量化效果,确保模型能够使得量化位宽充分利用。
[0036]
这种方式使得每层共享独有值,这么做提升了模型的收敛速度及精度,另外,在初
始化的时候,尽量将值设为6,因为神经网络模型训练时,为了保证模型收敛,激活函数一般设置为relu6的形式,然后在训练中通过正则化训练,逐步压低模型的clip value,使得模型收敛及精度提高。
附图说明
[0037]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,并不构成对本发明的限定。
[0038]
图1是本方法中调整的大小的具体方法的流程示意图。
具体实施方式
[0039]
为了能够更清楚地理解本发明的技术内容及优点,现结合附图对本发明进行进一步的详细说明。
[0040]
本发明属于深度神经网络基于低bit(4bit,5bit)训练过程中对feature的量化采取不同clip进行量化的处理技巧;提出对relu6中的clip值进行训练,适应每层的feature值依据不同的分布。具体涉及一种动态调整量化feature clip值的方法,其技术方案是这样实现的:
[0041]
假设第i层的量化计算如下所示:
[0042][0043][0044]
梯度反传值如下:
[0045][0046]
通过调整的大小,同时训练时对的变量添加l2的正则化,确保值训练时不至于过大,使得模型更易于收敛;
[0047]
注:值的调节通过对网络的训练,即反向传播算法,学习模型参数,设置网络输出的损失函数loss,如l1 loss、l2 loss或者交叉熵损失函数;通过把输入数据至网络,调节输出层的结果和真实值之间的偏差来进行逐层调节参数,该学习过程是一个不断迭代的过程,直网络的loss达到最小值,求取最有的解。
[0048]
如图1所示,所述调整的大小的方法具体包括以下步骤:
[0049]
s1,参数初始化;
[0050]
s2,进行前向运算,采用步骤s4中的参数
[0051]
s3,计算loss,输出结果;
[0052]
s4,参数更新;
[0053]
s5,反向传播,进行步骤s4。
[0054]
所述s5的反向传播,通过对loss的目标函数进行求导,逐次迭代更新参数
[0055]
注:所述的l2的正则化,即在对参数求取梯度反向传播,通过添加正则化参数,使得参数的更新在一个更小的范围内,网络的收敛更加稳定;
[0056][0057]
j为目标函数,即loss损失函数;
[0058]
h为网络的预测结果;
[0059]
y为真实标签结果;
[0060]
λ为正则化系数;
[0061]
θ为正则化参数,对参数进行求平方。
[0062]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1