一种针对弱光图像增强的结构-纹理感知方法
一种针对弱光图像增强的结构
‑
纹理感知方法
技术领域
1.本发明涉及图像增强技术领域,具体是一种应用于弱光照场景下拍摄图像的图像增强网络方法(stanet)。
背景技术:
2.数码摄影的基本目标是获得具有良好的对比、丰富的细节以及生动的色彩的自然场景图像。然而,弱光场景下拍摄的图像往往是曝光不足的,从而导致目标检测、语义分割和图像分类等高级视觉任务的性能下降。因此,针对弱光场景下拍摄图像的图像增强技术具有非常重要的研究意义。
3.目前,图像增强算法主要分为:传统图像增强算法和基于卷积神经网络的图像增强算法。
4.传统图像增强算法主要分为:直方图均衡化(he)、相机响应模型和retinex理论。目前最常见的是基于retinex的方法,比如ssr(single
‑
scale retinex)和msr(multi
‑
scale retinex)以及基于retinex理论的各种改进算法。这些算法利用光强对图像的影响机制以及人类视觉对亮度和颜色的感知模型,获得了较好的图像增强效果。然而,这些算法有两个主要限制。首先这些算法在图像增强过程中往往伴随着图像的失真,比如颜色失真。其次,这些算法在处理图像过程中不可避免地会引入噪声从而对图像质量造成损害。
5.基于卷积神经网络的图像增强算法利用神经网络强大的非线性建模能力,通过设置合适的网络结构提取需要的图像特征再利用设置的损失函数结合图像数据集来优化网络参数从而达到远超传统算法的图像增强性能。例如,完全卷积网络(fully convolutional network)、混合网络(hybrid network)和两级网络(two
‑
stage network)等。虽然基于卷积神经网络的算法在图像增强领域展示了优异的性能,然而大部分算法都是用同一种方式处理全局结构特征和局部纹理特征,而没有考虑到两者间的差异性,从而限制了算法性能的进一步提升。
技术实现要素:
6.针对上述现有方法的缺陷,本发明提出了一种利用结构关注子网和纹理关注子网分别处理结构图和纹理图的网络模型来解决网络不能有效利用全局结构和局部纹理差异性的问题。为了更好地搜集全局结构特征和局部纹理特征的联系,本发明还采用了具有通道关注机制和空间关注机制的融合子网来集成结构和纹理信息。
7.为了解决现有技术的不足,本发明提出了一种差异化处理结构和纹理特征并且充分利用结构和纹理的内在联系的图像增强网络方法,采用的技术方案是:
8.一种针对弱光图像增强的结构
‑
纹理感知方法,其特征在于,包括如下步骤:
9.步骤s1:准备训练数据集,从lol数据集和dped数据集中提取弱光/正常图像对作为训练集,其中弱光图像作为输入图像,与之对应的正常图像作为标签图像;
10.步骤s2:建立网络模型,利用轮廓图引导滤波器得到输入图像的结构图,再将输入
图像减去结构图得到纹理图,将得到的结构图和纹理图分别输入结构关注子网和纹理关注子网,得到对应的结构特征矩阵和纹理特征矩阵,二者进行级联操作得到既包含结构特征又包含纹理特征的级联矩阵,将级联矩阵输入空间关注模块和通道关注模块得到经过模块处理后的总的特征矩阵,最后对总的特征矩阵进行四层卷积操作再与输入的原始弱光图像进行残差操作得到增强后的图像;
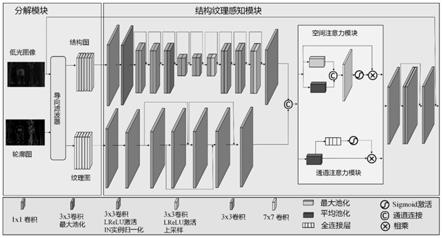
11.步骤s3:训练网络模型,将步骤s1中得到的数据集按照批量尺寸组合一起作为输入,设置网络模型的初始学习率,学习率衰减率,训练次数,设置权值初始化方式,设置网络模型的损失函数,利用混和损失函数采用adam优化器对网络参数进行优化;
12.步骤s4:图像增强,将弱光场景下拍摄的图像输入构建好的网络模型,加载预训练好的网络参数,进行图像增强处理,得到增强后的图像。
13.有益效果:
14.(1)本发明提出了一种用于图像增强的网络方法,它可以通过差异化处理图像的结构和纹理特征并且充分利用结构和纹理的内在联系来实现对弱光场景下拍摄图像的图像增强,经过图像增强的图像可以在目标检测、语义分割和图像分类等高级视觉任务中发挥更好的性能。
15.(2)本发明提出了一个混合损失函数,通过加入颜色损失函数来减轻图像增强过程中颜色失真的现象。本发明在lol数据集和dped数据上的实验结果表明,本发明的网络可以更好地保留颜色细节。
16.(3)本发明提出的网络在图像增强任务上达到的先进水平,在dped数据集的三类图像集上与当前主流的五种图像增强网络(srie、hdrnet、plsr、dslr
‑
q和lldhn)相比,指标值ssim在三类图像集中均位列第一,指标值psnr拿到了两类图像集的第二。
附图说明
17.图1是本发明针对弱光图像的图像增强系统示意图;
18.图2是本发明一种针对弱光图像增强的结构—纹理感知方法处理流程图;
19.图3本发明的方法与主流方法在lol数据集上的定性比较结果的示意图1;(a)为输入原图,(b)mf、(c)npe、(d)dong、(e)msr、(f)srie、(g)bimef、(h)lime、(i)crm,(j)retinex
‑
net、(k)kind方法的处理结果,(l)为本发明的处理结果;
20.图4本发明的方法与主流方法在lol数据集上的定性比较结果的示意图2:(a)为输入原图,(b)mf、(c)npe、(d)dong、(e)msr、(f)srie、(g)bimef、(h)lime、(i)crm,(j)retinex
‑
net、(k)kind方法的处理结果,(l)为本发明的处理结果;
21.图5是本发明的方法与主流方法在lol数据集上的定性比较结果的示意图3;(a)为输入原图,(b)mf、(c)npe、(d)dong、(e)msr、(f)srie、(g)bimef、(h)lime、(i)crm,(j)retinex
‑
net、(k)kind方法的处理结果,(l)为本发明的处理结果;
22.图6是本发明的方法与主流方法在dped数据集上的定性比较结果:(a)是输入图像,(b)是srie、(c)是dslr
‑
q的处理结果,(d)是本发明的处理结果,(e)是标签即正常光照下的图像;
23.图7是本发明的方法与主流方法在真实图像上的定性比较结果:(a)是输入图像,(b)是srie、(c)是dslr
‑
q、(d)是kind的处理结果,(e)是本发明的处理结果。
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
25.本发明提出了一种针对弱光图像增强的结构
‑
纹理感知方法,具体来说,网络通过差异化处理弱光图像的全局结构特征和局部纹理特征并利用二者的内在联系实现图像增强功能,网络模型的结构如图1所示:
26.根据本发明的实施例,该网络主要包括特征分解模块(decomposition module)和结构—纹理感知模块(structure
‑
texture aware module)。特征分解模块中,本发明利用输入图像的轮廓图(contour map)对输入图像做引导滤波得到输入图像的结构图(structure map),再将输入图像减去结构特征图得到相对应的纹理图(texture map)。结构
‑
纹理感知模块中,本发明首先利用结构特征子网(structure
‑
attention subnetwork)和纹理特征子(texture
‑
attention subnetwork)分别对特征分解模块得到的结构图和纹理图提取特征得到对应的结构特征矩阵和纹理特征矩阵,将得到的矩阵级联得到同时具有结构信息和纹理信息的总矩阵,将得到矩阵输入由空间关注模块(spatial attention)和通道关注模块(channel attention)组成的融合子网(fusion subnetwork)利用结构特征和纹理特征的内在联系融合特征,最后将融合后的矩阵经过四层卷积处理和输入图像相加得到与输入图像相对应的增强图像。
27.上述方法的流程图如图2所示,具体包含以下步骤:
28.s1、准备训练数据集;
29.本实例中使用图像增强领域的典型数据集lol(lol dataset)的500对600
×
400彩色图像(一张弱光场景的图像对应一张相同场景下的正常图像,其中正常图像作为网络训练的标签)。对于图像增强,来自lol数据集的总共450对彩色图像用于训练网络,剩下的50对彩色图像中选择35对彩色图像作为验证集用以调整网络模型中的超参数。对于输入的弱光图像,根据图像的光照强度灵活选择指数得到图像的轮廓图,弱光图像和相应的轮廓图作为网络的输入,对应的正常图像作为网络训练的标签(ground truth)。
30.s2、搭建网络模型;
31.本实例的网络主要分为特征分解模块和结构—纹理关注模块两个部分。特征分解模块的输入是弱光图像和对应的轮廓图,输出是利用导向滤波器得到弱光图像的全局结构特征图和局部纹理图,其中轮廓图利用指数局部均方差(emlv)求得。结构—纹理关注模块利用结构子网、纹理子网和融合网络先分别提取全局结构和局部纹理的特征矩阵再通过融合网络利用全局结构和局部纹理的内在联系得到增强的图像,具体的网络结构如图1所示:
32.(1)特征分解模块:本实例中,本发明先利用改进的局部均方差得到弱光图像的轮廓图,指数局部均方差公式如式1所示(其中ω表示r的每个像素点周围3
×
3的窗口,r表示r的梯度,γ表示指数参数),将弱光图像和得到的轮廓图输入导向滤波器(滤波器的k值设置为4)得到全局结构图,弱光图像减去结构图得到对应的纹理图,模块的处理过程可以用式2和式3表示(其中g表示导向滤波器,r表示弱光图像,c表示对应的轮廓图,s表示对应的结构图,t表示对应的纹理图)。
[0033][0034]
s=g(r,c)
ꢀꢀꢀꢀ
(2)
[0035]
t=r
‑
s
ꢀꢀꢀꢀ
(3)
[0036]
(2)结构
‑
纹理关注模块:本实例中,本发明先采用两个并行的结构关注子网和纹理关注子网分别从结构图和纹理图中提取结构信息和纹理信息,其中结构图将首先通过一个1
×
1的卷积来挑选通道特征在经过一个20层的卷积网络提取特征信息,每层卷积的通道数都为64,卷积核的大小及先后关系如图1所示,而纹理图将通过一个不含下采样操作的7层卷积网络提取纹理特征信息,每层的通道数都为64,卷积核的大小及先后关系如图1所示,最后将得到的结构特征和纹理特征输入融合网络。在融合网络中包含空间关注模块和通道关注模块两个部分,其中空间关注模块利用全局平均池化和最大池化来提取两张空间层面的表示图,对两张表示图进行一层7
×
7的卷积运算得到一张包含总的空间信息的特征图,通道关注模块则利用压缩操作和激励操作来提取空间特征和纹理特征的内在联系,最后通过一个级联卷积层将得到的空间标签和通道标签合并再利用一个残差网络得到增强后的图像,具体的网络结构如图1所示。结构
‑
纹理关注模块的处理流程可以简化为式4(其中e
n
表示结构关注子网,x
n
表示纹理关注子网,f表示融合网络,0表示增强后的图像)。
[0037]
o=f(e
n
(s),x
n
(t))
ꢀꢀꢀꢀ
(4)
[0038]
(3)损失函数:在本实例中,本发明使用混合损失函数,该函数结合了均方差损失、梯度损失、结构相似性损失和颜色损失。网络的混合损失量计算如下:
[0039]
l
total
=λ1l
mse
+λ2l
tv
+λ3l
ssim
+λ4l
color
ꢀꢀꢀꢀ
(5)
[0040]
其中l
mse
、l
tv
、l
ssim
和l
color
分别表示均方差损失、梯度损失、结构相似性损失和颜色损失;λ1、λ2、λ3和λ4分别是四类损失的权重。
[0041]
均方差损失用来衡量增强后的图像和标签图像(ground truth)之间的总体内容相似性,给定n个训练图像,均方差损失可以写成如下形式(其中h(r)表示增强后的图像,i表示与之相对应的标签图像):
[0042][0043]
梯度损失用来衡量增强后的图像和标签图像之间的梯度相似性,给定n个训练图像,梯度损失可以写成如下形式(其中表示梯度算子):
[0044][0045]
结构相似性损失用来衡量增强后的图像与标签图像视觉效果差异,给定n个训练图像,结构相似性损失可以写成如下形式(其中ssim表示图像结构相似性计算):
[0046]
[0047]
结构相似性计算公式可以写成如下形式(其中μ
h(r)
和μ
i
分别代表图像h(r)和i的均值,σ
h(r)2
和σ
i2
分别代表图像h(r)和i的方差,σ
h(r)i
代表图像h(r)和i之间的协方差,c1和c2为常数,分别设置为0.0001和0.0009):
[0048][0049]
颜色损失解决图像增强后的色彩失真问题,给定n个训练图像。颜色损失可以写成如下形式(其中max(.)表示从rgb三个通道中取最大值,min(.)表示从rgb三个通道中取最小值):
[0050][0051]
s3、训练网络模型;
[0052]
在gpu(tesla v100)上运行的tensor
‑
flow框架来实现本发明所提出的网络。s中得到的训练图像裁剪为100
×
100像素大小并经过数据增强处理,然后按照批量尺寸(batch size)为32组合一起作为输入,训练模型进行8000次迭代。关于所提出方法的超参数,根据经验将λ1、λ2、λ3和λ4分别设置为1,0.01,1和0.05。
[0053]
训练网络时,采用adam优化器:初始学习率设置为0.0005,学习率以每迭代4000轮乘以0.1的速度衰减。保存训练好的模型权重。
[0054]
s4、准备测试数据集;
[0055]
本实例中测试集的准备类比s1的方法,主要有两个测试集构成。一个在lol数据集中得到标准测试集15对图像来评估模型,另一个是在dped数据集中得到由黑莓、苹果和索尼三类设备拍摄的三类图像,分别为2.4k,2.5k,4.3k对图像作为测试集来评估模型。
[0056]
结果分析;
[0057]
(1)lol数据集上的结果。本发明的方法和目前主流方法在lol数据集上的定性比较结果显示在图3,图4和图5中,input指输入的原图,定量比较结果显示在表1中(每项比较指标的最好值用黑体显示,次好结果用下划线标注)。从定性比较来看,与主流方法对比,本发明提出的方法对弱光图像进行图像增强的同时保留了大量纹理细节和颜色细节,增强后的图像在图像亮度,纹理细节,颜色细腻度三个方面都大幅优于主流方法。从定量结果来看,与主流方法对比,本发明的方法在峰值信噪比(psnr)、结构相似性(ssim)、亮度排序误差(loe)和自然图像质量(niqe)4项比较指标中的3项取得了最优值,另一项取得了次优值,这些定量比较指标上的领先与定性比较结果上的领先相对应,体现了本方法的优越性。
[0058]
表1在lol数据集上与主流方法的定量结果比较
[0059][0060]
(2)dped数据集上的结果。本发明的方法和目前主流方法在dped数据集上的定性比较结果(包含标签图像)显示在图6中,定量比较结果显示在表2中(每项比较指标的最好值用黑体显示,次好结果用下划线标注)。从定性比较结果来看,本发明的方法得到的增强后的图像在纹理细节、颜色细腻度和全局总体结构三个方面都更接近标签图像(ground truth)。从定量比较结果来看,本发明的方法在dped数据集三类图像(iphone,blackberry,sony)的结构相似性指标项上均取得了最优值,在iphone类和sony类图像的峰值信噪比指标项上取得了次优值,这些定量比较结果的领先显示了本发明方法在图像增强任务上的优异性能。
[0061]
表2在dped数据集上与主流方法的定量比较
[0062][0063]
(3)真实图像上的结果。本发明的方法和目前主流方法在真实图像上的定性比较结果显示在图7中,定向比较结果显示我,本发明的方法图像亮度方面大幅领先其他方法,同时还保留了大量纹理细节和颜色细节,图片在提高亮度展示更多细节的同时保留了原有的纹理和颜色细节,使得最后的增强图像质量得以大幅提升。
[0064]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,且应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1