一种基于帧连续四维扫描的人脸形状表情模型构建方法与流程
本发明涉及人脸形状表情模型构建技术领域,具体为一种基于帧连续四维扫描的人脸形状表情模型构建方法。
背景技术:
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术,用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别;
现在三维人脸形状的构建虽然可以经过大量的人力修正之后,达到很高的精度,人眼无法识别的逼真度,但耗费成本巨大,只能在特定的高端电影制作才能负担这种财力人力密集的操作,也很难推广复用,普通的商业短视频使用或动画使用都无法负担这个成本,而普通的轻度的三维扫描大都基于普通三维模型,这些模型从基础方法上就缺乏表现自然人脸形状和表情的能力,用这种方法构建的模型没法生成有表情差异的照片,更不用说视频或动画了,所以我们使用严格帧连续四维扫描来用更低的成本达到更有表现力的人脸形状与表情的模型。
技术实现要素:
本发明提供一种基于帧连续四维扫描的人脸形状表情模型构建方法,可以有效解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于帧连续四维扫描的人脸形状表情模型构建方法,包括如下步骤:
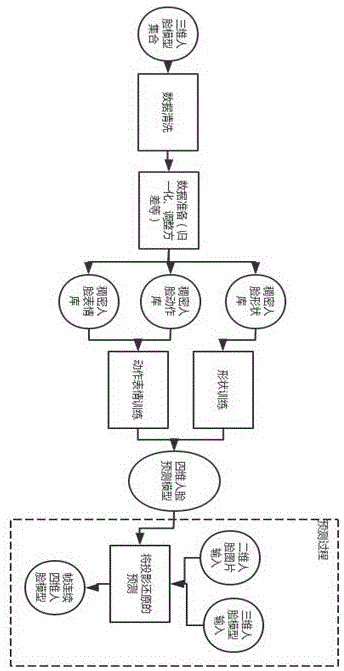
s1、基于大批传统的不同人的三维半身像形状模型数据集合,转换三维信息保存格式,清洗不合理数据,注册为形状待训练数据集合,作为整个训练过程的基础形状库;
s2、基于大批原始的三维形状模型的五官以及其他blendshapes变形情况,灌入三维表情、动作待训练数据库,将变形情况完全数据归一化,作为训练过程的基础表情动作数据库;
s3、确保s1步和s2步的成年男女头部模型,使用各自独立的基础库;
s4、将模型参数化;
s5、持续s4步中参数据化的过程,直到延展至整个数据空间,以此得到了三组基础参数化后的人脸的三维形状、动作、表情数据库;
s6、要输出帧连续的四维形状、动作和表情;
s7、训练模型的使用到sklearn的回归分析,以及基于基础梯度下降法的信赖域狗腿(dogleg)方法,用基础机器学习的过程,得出帧连续四维人脸数据模型;
s8、得到帧连续四维人脸数据模型后,能够通过输入二维的图片预测出高置信度的帧连续四维模型,也能通过某个时刻的三维模型,预测出高置信度的帧连续四维模型。
根据上述技术方案,所述s4中具体步骤如下:
a.调整最初的一组模型,将模型参数归一化到一定的标准差范围内,好做拟合,每个3d人脸模型被表达为基于标准顶点(vertex)的线性骨骼蒙皮linearblendskinning(lbs)和纠正式变形器blendshapes,包括v(>5000)个顶点,以及四个关节部位(脖子、下巴、两处眼球);
b.动作的参数化过程并不使用所有数据,在旋转动作的操作中,截取一组脖子和下巴持续的的n个动作集合,激活其中的k(k<n)个动作;
c.表情的参数化过程类似于形状归一化过程,将不同模型的表情参数化,并综合对比参数情况,归一化到可比较的状态,降低标准差到一个合适小的范围之内。
根据上述技术方案,所述s7中对于关节的位置,从三维模型的mesh到关节的位置,我们训练得到一个稀疏矩阵p1,通过这个习得得稀疏回归矩阵p1,之后这个可以与mesh顶点数据计算得到关节位置。
根据上述技术方案,所述s8中整个过程是通过二维输入投影或三维输入投影在四维空间中得到高置信度还原,其中二维的计算需要先对图片做人脸拾取,并确认关键点,然后先转换到三维模型。这个预测的过程都会用到关节位置预测矩阵p1,动作变形器组合回归矩阵p2等变换得到不同姿势位置的脸型。
根据上述技术方案,所述s6中输入的训练数据空间必须是稠密的,经过稠密数据检测,确认无误才能训练。
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,能够通过预制模型,低成本高质量的得到帧连续四维人脸结果,通过训练稠密三维人脸形状、动作、表情数据得到帧连续人脸预测模型,可以通过得到帧连续四维预测模型,能够将输入的二维输入投影或三维输入投影在四维空间中得到高置信度还原。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
在附图中:
图1是本发明的构建方法结构示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例:如图1所示,本发明提供技术方案,一种基于帧连续四维扫描的人脸形状表情模型构建方法,包括如下步骤:
s1、基于大批传统的不同人的三维半身像形状模型数据集合,转换三维信息保存格式,清洗不合理数据,注册为形状待训练数据集合,作为整个训练过程的基础形状库;
s2、基于大批原始的三维形状模型的五官以及其他blendshapes变形情况,灌入三维表情、动作待训练数据库,将变形情况完全数据归一化,作为训练过程的基础表情动作数据库;
s3、确保s1步和s2步的成年男女头部模型,使用各自独立的基础库;
s4、将模型参数化;
s5、持续s4步中参数据化的过程,直到延展至整个数据空间,以此得到了三组基础参数化后的人脸的三维形状、动作、表情数据库;
s6、要输出帧连续的四维形状、动作和表情;
s7、训练模型的使用到sklearn的回归分析,以及基于基础梯度下降法的信赖域狗腿(dogleg)方法,用基础机器学习的过程,得出帧连续四维人脸数据模型;
s8、得到帧连续四维人脸数据模型后,能够通过输入二维的图片预测出高置信度的帧连续四维模型,也能通过某个时刻的三维模型,预测出高置信度的帧连续四维模型。
根据上述技术方案,s4中具体步骤如下:
a.调整最初的一组模型,将模型参数归一化到一定的标准差范围内,好做拟合,每个3d人脸模型被表达为基于标准顶点(vertex)的线性骨骼蒙皮linearblendskinning(lbs)和纠正式变形器blendshapes,包括v(>5000)个顶点,以及四个关节部位(脖子、下巴、两处眼球);
b.动作的参数化过程并不使用所有数据,在旋转动作的操作中,截取一组脖子和下巴持续的的n个动作集合,激活其中的k(k<n)个动作;
c.表情的参数化过程类似于形状归一化过程,将不同模型的表情参数化,并综合对比参数情况,归一化到可比较的状态,降低标准差到一个合适小的范围之内。
根据上述技术方案,s7中对于关节的位置,从三维模型的mesh到关节的位置,我们训练得到一个稀疏矩阵p1,通过这个习得得稀疏回归矩阵p1,之后这个可以与mesh顶点数据计算得到关节位置。
根据上述技术方案,s8中整个过程是通过二维输入投影或三维输入投影在四维空间中得到高置信度还原,其中二维的计算需要先对图片做人脸拾取,并确认关键点,然后先转换到三维模型。这个预测的过程都会用到关节位置预测矩阵p1,动作变形器组合回归矩阵p2等变换得到不同姿势位置的脸型。
根据上述技术方案,s6中输入的训练数据空间必须是稠密的,经过稠密数据检测,确认无误才能训练。
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,能够通过预制模型,低成本高质量的得到帧连续四维人脸结果,通过训练稠密三维人脸形状、动作、表情数据得到帧连续人脸预测模型,可以通过得到帧连续四维预测模型,能够将输入的二维输入投影或三维输入投影在四维空间中得到高置信度还原。
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!