基于特征增强的多类别光学图像旋转目标自适应检测方法
1.本发明属于图像处理技术领域,涉及一种光学图像旋转目标检测方法,具体涉及一种基于特征增强的多类别光学图像旋转目标自适应检测方法,可用于资源管理、安全预警、非法活动识别等领域。
背景技术:
2.近年来随着我国的卫星数量逐渐增多以及获取的图像质量也在不断提升,能够采集到高分辨率的光学图像,这为各种资源的监视和管理等相关研究带来了新的挑战。光学图像旋转目标检测为这方面的研究提供了一种高效的思路。光学图像旋转目标检测是指在已经获取的光学图像上,检测出图像中所有感兴趣目标的边界框位置和类别,旋转目标指的是目标的边界框位置包含边界框的中心点坐标、边界框的长、边界框的宽以及边界框的长边与水平方向的逆时针夹角。然而光学图像旋转目标检测仍存在一些难点,例如背景信息的复杂度高、目标的尺寸变化大、目标密集排列以及目标以任意方向出现。
3.现有的光学图像目标检测方法主要分为传统的目标检测方法和基于深度学习的目标检测方法。传统的目标检测方法在给定的图像上选择一些候选的区域,对这些区域提取特征,再使用训练的分类器进行分类,该类传统的检测方法在信息丰富的光学图像上检测精度普遍低且消耗时间过长。基于深度学习的目标检测方法中具有代表性的有j.redmon等人在2016年提出的yolov3算法。针对传统的目标检测算法普遍出现的运算速度慢的缺点,yolov3直接在输出层回归边界框的位置和所属类别信息,从而满足实时性能需求,但由于yolov3为水平边界框定位的目标检测方法,无法定位旋转目标的角度。
4.为了获得旋转目标的方向信息,研究学者在yolov3的基础上通过设计旋转的先验框去匹配旋转目标实现更精确的定位。例如申请公布号为cn110674674a,名称为“一种基于yolov3的旋转目标检测方法”的专利申请,公开了一种基于yolov3的旋转目标检测方法,该方法通过重新设计yolov3算法中边界框的产生、iou的计算和损失函数的计算方法,解决了无法定位旋转目标角度以及目标检测准确率和召回率低的问题,但该方法中小尺度目标经过特征提取网络的多次下采样后特征容易丢失,导致小尺度目标的漏检,同时该网络特征提取网络提取目标的语义特征和位置特征不充分,导致目标检测的准确率低。
技术实现要素:
5.本发明的目的在于克服上述现有技术存在的缺陷,提出了一种基于特征增强的多类别光学图像旋转目标自适应检测方法,用于解决现有技术中存在的任意方向多尺寸密集排列的旋转目标召回率与准确率低的问题。
6.本发明的技术思路为,获取训练样本集和测试样本集,对训练样本集进行镜像翻转和任意方向扰动角度的数据增强,搭建一个包含主干网络和检测网络的光学图像旋转目标检测网络模型,其中主干网络包含特征提取子网络和特征增强子网络,检测网络包含定位子网络和分类子网络,利用训练样本集训练光学图像旋转目标检测网络模型,得到训练
好的光学图像旋转目标检测网络模型,将测试样本作为训练好的光学图像旋转目标检测网络模型的输入进行检测得到所有目标的边界框位置和类别置信度,并滤除目标类别置信度中低于置信度阈值的目标边界框位置和类别置信度,得到过滤后的目标边界框位置和类别置信度,然后通过旋转目标的非极大值抑制rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到过滤后的目标边界框和类别置信度;
7.根据上述技术思路,实现本发明目的采取技术方案包括如下步骤:
8.(1)获取训练样本集和测试样本集:
9.(1a)获取包括m个旋转目标类别的t幅大小为n
×
n的光学图像h={h1,h2,
…
,h
t
,
…
,h
t
},每幅光学图像h
t
至少包含k个旋转目标,并通过标注框对每幅光学图像h
i
中的每个旋转目标进行标注,将标注框中心的水平坐标x和垂直坐标y、标注框的长l和宽w、标注框的长边与水平方向的逆时针夹角θ作为h
t
中每个旋转目标的边界框位置标签,将标注框内目标的类别c作为h
t
中每个目标的类别标签,c∈{1,2,
…
,m},其中,m≥2,t≥20,h
t
表示第t幅光学图像,k≥2;
10.(1b)以l_step为滑动步长,并通过大小为n
×
n的滑窗将每幅光学图像h
t
裁剪为p个光学子图像h’t
={h’t1
,h’t2
,
…
,h’ts
,
…
,h’tp
},得到裁剪后的光学图像集合h’={h
’1,h
’2,
…
,h’t
,
…
,h’t
},其中,h’ts
表示h
t
裁剪得到的第s个光学子图像;
11.(1c)通过光学子图像h’ts
中目标相对于h
t
中目标的水平偏移量x
diff
和垂直偏移量y
diff
,计算图像h’ts
中目标的水平坐标x’=x
‑
x
diff
和垂直坐标y’=y
‑
y
diff
,并将图像h’ts
中目标的标注框中心的水平坐标x’和垂直坐标y’、标注框的长l和宽w、标注框的长边与水平方向的逆时针夹角θ作为h’ts
中目标的边界框位置标签,图像h’ts
中目标的标注框的类别c作为h’ts
中目标的类别标签;
12.(1d)对h’t
中包含旋转目标的光学子图像集合h”t
中的每个光学子图像分别进行镜像翻转和随机角度扰动的数据增强,得到数据增强后的光学子图像集合h
”’
t
,并将h”t
和h
”’
t
构成的光学子图像集合以及中每个光学子图像的标签作为训练样本集,将从裁剪后的光学子图像集合h’中随机抽取的r
×
p幅裁剪后的光学子图像集合h
*
以及h
*
中每个光学子图像的标签作为测试样本集,其中,
13.(2)构建基于特征增强的光学图像旋转目标检测网络模型:
14.构建包括顺次连接的主干网络和检测网络的光学图像旋转目标检测网络模型,其中:
15.主干网络包括顺次连接的特征提取子网络和特征增强子网络;特征提取子网络包括多个卷积层和多个block块,block块包括顺次连接的两个卷积层和一个残差连接层;特征增强子网络包含顺次连接的上采样层和block1块;
16.检测网络包括并行连接的定位子网络和分类子网络;定位子网络包含顺次连接的卷积层、全连接层和先验框层;分类子网络包含顺次连接的卷积层和全连接层;
17.(3)对基于特征增强的光学图像旋转目标检测网络模型进行迭代训练:
18.(3a)初始化迭代次数为w,最大迭代次数为w,w≥10000,并令w=1;
19.(3b)将从训练样本集随机选取的b个训练样本作为光学图像旋转目标检测网络模型的输入进行前向传播,主干网络中的特征提取子网络对每个训练样本的所有目标进行特征提取,特征增强子网络对特征提取子网络所提取的特征进行合并后,对合并后的特征进行卷积融合,得到融合后的语义特征和位置特征,检测网络中的定位子网络利用融合后的位置特征计算目标预测边界框,分类子网络利用融合后的语义特征计算目标预测类别,其中,b≥10;
20.(3c)定位子网络采用smoothl1函数,并通过目标的预测边界框和目标的边界框位置标签计算目标的位置损失值l1,分类子网络采用交叉熵函数,并通过目标的预测类别置信度和目标的类别标签计算目标的类别置信度损失值l2,然后采用随机梯度下降法,并通过l1与l2的和对主干网络和检测网络中的卷积核权重参数ω
w
和全连接层结点之间的连接权重参数θ
w
进行更新;
21.(3d)判断w=w是否成立,若是,得到训练好的基于特征增强的光学图像旋转目标检测网络模型,否则,令w=w+1,并执行步骤(3b);
22.(4)获取光学图像旋转目标的自适应检测结果:
23.(4a)将测试样本中的每幅光学子图像作为训练好的基于特征增强的光学图像旋转目标检测网络的输入,进行目标的边界框位置和目标的类别置信度检测,得到中所有目标的边界框位置和类别置信度,并滤除目标类别置信度中低于置信度阈值λ的目标边界框位置和类别置信度,得到过滤后的目标边界框位置和类别置信度,然后通过旋转目标的非极大值抑制rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到的过滤后的目标边界框和类别置信度;
24.(4b)对测试样本中的每幅光学子图像进行l1倍缩小和l2倍放大,并将缩小后的光学子图像和放大后的光学子图像作为训练好的基于特征增强的光学图像旋转目标检测网络的输入,进行目标的边界框位置和目标的类别置信度检测,得到和中所有目标的边界框位置和类别置信度,并滤除目标类别置信度中低于置信度阈值λ的目标边界框位置和类别置信度,得到过滤后的目标边界框位置和类别置信度,然后通过旋转目标的非极大值抑制rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到的过滤后的目标的边界框和类别置信度,以及的过滤后的目标的边界框和类别置信度;
25.(4c)对和中的过滤后的目标边界框位置和类别置信度进行合并,并通过rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到所有目标的边界框位置和类别置信度,
26.本发明与现有技术相比,具有以下优点:
27.1、本发明所构建的基于特征增强的光学图像旋转目标检测网络模型中的主干网络,包括有顺次连接的特征提取子网络和特征增强子网络,特征增强子网络通过对特征提取子网络所提取的特征进行卷积融合,增强了目标的语义特征和位置特征,同时检测网络
在卷积融合后的高分辨率特征图上检测出更多的小尺度目标,减小了小尺度目标漏检的几率,与现有技术相比,有效提高了任意方向的多尺度旋转目标的召回率和准确率。
28.2、本发明通过对原始、放大和缩小后的尺度的光学图像进行旋转目标检测,能够检测出更多的旋转目标,与现有技术相比,有效提高了尺度差距大的旋转目标的召回率。
附图说明
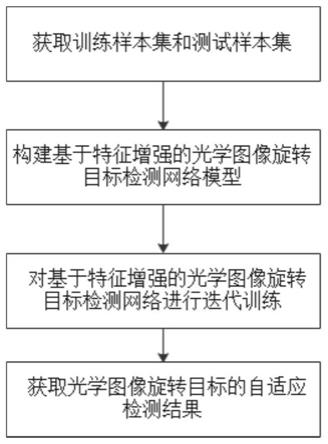
29.图1是本发明的实现流程图;
30.图2是本发明光学图像旋转目标检测网络模型的结构示意图;
31.图3是本发明仿真使用的光学图像;
32.图4是本发明与现有技术目标检测召回率的仿真对比图。
具体实施方式
33.以下结合附图和具体实施例,对本发明作进一步详细描述:
34.参照图1,本发明包括如下步骤:
35.步骤1)获取训练样本集和测试样本集:
36.(1a)获取包括m个旋转目标类别的t幅大小为n
×
n的光学图像h={h1,h2,
…
,h
t
,
…
,h
t
},每幅光学图像h
t
至少包含k个旋转目标,并通过标注框对每幅光学图像h
i
中的每个旋转目标进行标注,将标注框中心的水平坐标x和垂直坐标y、标注框的长l和宽w、标注框的长边与水平方向的逆时针夹角θ作为h
t
中每个旋转目标的边界框位置标签,将标注框内目标的类别c作为h
t
中每个目标的类别标签,c∈{1,2,
…
,m},其中,m≥2,t≥20,h
t
表示第t幅光学图像,k≥2;
37.本实施例中,旋转目标通过标注框对每幅光学图像h
i
中的每个旋转目标进行标注时采用的标注软件为rolabelimg,获取的光学图像包含240幅分辨率为1米以及300幅分辨率为2米的光学舰船图像,获取的光学图像中包含的8类舰船分别为第1类直升机航母、第2类护卫舰、第3类补给舰、第4类民船、第5类小游艇、第6类大型航母、第7类石油运输船和第8类潜艇,m=8,t=540,n=20000,k=2;
38.(1b)以l_step为滑动步长,并通过大小为n
×
n的滑窗将每幅光学图像h
t
裁剪为p个光学子图像h’t
={h’t1
,h’t2
,
…
,h’ts
,
…
,h’tp
},得到裁剪后的光学图像集合h’={h
’1,h
’2,
…
,h’t
,
…
,h’t
},其中,h’ts
表示h
t
裁剪得到的第s个光学子图像;
39.本实施例中,l_step=200,n=608,p=9216,所述的8类舰船中第1类直升机航母和第6类大型航母的尺度大,采用608
×
608的滑窗可以获取完整的直升机航母和大型航母,同时第5类小游艇的尺度小,若采用较大的滑窗,第5类小游艇和第8类潜艇经过特征提取子网络的5次下采样后特征丢失,造成漏检;
40.(1c)通过光学子图像h’ts
中目标相对于h
t
中目标的水平偏移量x
diff
和垂直偏移量y
diff
,计算图像h’ts
中目标的水平坐标x’=x
‑
x
diff
和垂直坐标y’=y
‑
y
diff
,并将图像h’ts
中目标的标注框中心的水平坐标x’和垂直坐标y’、标注框的长l和宽w、标注框的长边与水平方向的逆时针夹角θ作为h’ts
中目标的边界框位置标签,图像h’ts
中目标的标注框的类别c
作为h’ts
中目标的类别标签;
41.(1d)对h’t
中包含旋转目标的光学子图像集合h”t
中的每个光学子图像分别进行镜像翻转和随机角度扰动的数据增强,得到数据增强后的光学子图像集合h
”’
t
,并将h”t
和h
”’
t
构成的光学子图像集合以及中每个光学子图像的标签作为训练样本集,将从裁剪后的光学子图像集合h’中随机抽取的r
×
p幅裁剪后的光学子图像集合h
*
以及h
*
中每个光学子图像的标签作为测试样本集,其中,
42.本实施例中,r=50,镜像翻转具体指的是对图像进行左右翻转,对图像进行镜像翻转是为了增强旋转目标的中心坐标位置信息,提升模型的泛化能力;随机角度扰动具体指的是随机从5
°
、10
°
、15
°
和20
°
中选择一个角度对图像进行逆时针旋转,对图像进行随机角度扰动是为了增强旋转目标的角度信息,提升模型的泛化能力;
43.步骤2)构建基于特征增强的光学图像旋转目标检测网络模型:
44.构建包括顺次连接的主干网络和检测网络的光学图像旋转目标检测网络模型,其中:
45.主干网络包括顺次连接的特征提取子网络和特征增强子网络;特征提取子网络包括多个卷积层和多个block块,block块包括顺次连接的两个卷积层和一个残差连接层;特征增强子网络包含顺次连接的一个上采样层和block1块;
46.检测网络包括并行连接的定位子网络和分类子网络;定位子网络包含顺次连接的卷积层、全连接层和先验框层;分类子网络包含顺次连接的卷积层和全连接层;
47.特征提取子网络包括5个卷积层和26个block块,具体结构为:第一卷积层、第一至第二block、第二卷积层、第三至第六block、第三卷积层、第七至第十四block、第四卷积层、第十五至第二十二block、第五卷积层和第二十三至第二十六block;
48.第一卷积层的卷积核尺寸为5
×
5,第二至第五卷积层卷积核的尺寸均为3
×
3,激活函数均为relu函数,第一至第五卷积层的卷积步长均为2,第一至第五卷积层卷积核的个数分别为64、128、256、512和1024;
49.每个block包含依次连接的卷积层block_c1和卷积层block_c2,block_c1的卷积核尺寸为1
×
1,block_c2的卷积核尺寸为3
×
3,卷积步长均为1,激活函数均为relu函数;
50.特征增强子网络包括顺次连接的一个上采样层和block1,block1包含6个卷积层,具体结构为:并行连接的block_c1、block_c2、block_c2,block_c1、block_c2,block_c1;
51.特征增强子网络的增强方式为:第二十六block的特征作为定位子网络中第六卷积层以及分类子网络中第九卷积层的输入,分别用于回归大尺度目标的边界框位置以及预测大尺度目标的类别;第二十六block的特征经过上采样层与第二十二block的特征通过通道拼接的方式合并,再经过block1得到第一次增强后的特征作为定位子网络中第七卷积层以及分类子网络中第十卷积层的输入,分别用于回归中尺度目标的边界框位置以及预测中尺度目标的类别;第一次增强后的特征经过上采样层与第十四block的特征通过通道拼接的方式合并,再经过block1得到第二次增强后的特征作为定位子网络中第八卷积层以及分类子网络中第十一卷积层的输入,分别用于回归小尺度目标的边界框位置以及预测小尺度目标的类别;
52.本实施例中,所述的大尺度目标包含第1类直升机航母、第6类大型航母和第7类石
油运输船,中尺度目标包含第2类护卫舰、第3类补给舰和第4类民船,第三先验框层的先验框负责回归小尺度的目标包含第5类小游艇和第8类潜艇,所述的上采样层采用双线性插值方法;
53.设计特征增强子网络的原因为:低层次的特征分辨率高,包含更多细节的位置和语义信息,但是由于经过的卷积层少,导致噪声较多,高层次的特征分辨率低,对细节的感知能力差,通过通道拼接的方式对特征提取网络的低层次和高层次的特征进行合并,再经过卷积融合使得检测网络同时获得低层次的目标细节语义特征和高层次的空间位置特征,提升目标检测的准确率,同时检测网络在卷积融合后的高分辨率特征图上检测出更多的小尺度目标,减小了小尺度目标漏检的几率;
54.定位子网络包括3个卷积层、3个全连接层和3个先验框层,具体结构为:第六卷积层、第一全连接层、第一先验框层、第七卷积层、第二全连接层、第二先验框层、第八卷积层、第三全连接层和第三先验框层;
55.第六卷积层的卷积核个数为1024,卷积核尺寸为5
×
5,第七卷积层的卷积核个数为512,卷积核尺寸为3
×
3,第八卷积层的卷积核个数为256,卷积核尺寸为3
×
3,该三个卷积层的卷积步长均为1,激活函数均为relu函数;
56.第一、第二和第三全连接层的隐层单元个数分别为135、180和180;
57.第一先验框层的三个先验框的长分别为0.728、0.573和0.478,宽分别为0.147、0.115和0.096,第二先验框层的四个先验框的长分别为0.374、0.248、0.159和0.095,宽分别为0.074、0.049、0.036和0.049,第三先验框层的四个先验框的长分别为0.057、0.043、0.030和0.029,宽分别为0.029、0.021、0.016和0.013,该三个先验框层的角度均为0
°
,20
°
,40
°
,60
°
,80
°
,100
°
,120
°
,140
°
,160
°
;
58.分类子网络包括3个卷积层和3个全连接层,具体结构为:第九卷积层、第四全连接层、第十卷积层、第五全连接层、第十一卷积层、第六全连接层;
59.第九卷积层的卷积核个数为1024,卷积核尺寸为5
×
5,第十卷积层的卷积核个数为512,卷积核尺寸为3
×
3,第十一卷积层的卷积核个数为256,卷积核尺寸为3
×
3,该三个卷积层的卷积步长均为1,激活函数均为relu函数;
60.第四、第五和第六全连接层的隐层单元个数分别为243、324和324。
61.本实施例中,利用kmeans聚类算法设计先验框的长和宽。其中,第一先验框层、第二先验框层和第三先验框层的先验框分别用于回归大尺度、中尺度和小尺度目标的边界框位置,因此该三个先验框层的先验框尺度从大到小排序依次为第一先验框层的先验框、第二先验框层的先验框、第三先验框层的先验框;所述的训练样本集的大尺度目标所占比例为25%,因此为第一先验框层设计3个尺度的先验框的长和宽,中尺度目标和小尺度目标在所有目标中所占比例分别为45%和30%,因此为第二和第三先验框层设计4个尺度的先验框的长和宽;先验框的长和宽的数值为608
×
608大小的训练样本尺寸归一化后的数值;
62.通过kmeans聚类算法计算得到先验框的长和宽的指的是将所有旋转目标的长度和宽度作为聚类的两个维度,以任意两个目标边界框的交并比iou的值作为它们的距离,通过kmeans聚类算法对旋转目标边界框的长度和宽度进行迭代聚类,其中两个目标边界框的iou的值越大,距离就越近。具体步骤为:初始化迭代次数为v=1,最大迭代次数v=500,随机挑选11个目标边界框的长度和宽度作为11个目标边界框集合的聚类中心;对于剩余的每
个目标边界框,通过计算目标边界框和该11个目标边界框集合的聚类中心的iou值,将目标边界框加入与其距离最小的目标边界框集合;将11个目标边界框集合中所有边界框长度和宽度的平均值分别作为新的目标边界框集合的聚类中心的长度和宽度,若这11个目标边界框集合下一轮与上一轮的聚类中心长度和宽度的差值分别达到阈值l
diff
=0.001以及w
diff
=0.001或者达到迭代次数v=500,聚类结束,得到11个目标边界框集合的聚类中心的长度和宽度,否则v=v+1,继续下一轮迭代;
63.任意两个同一中心点、长和宽,旋转框角度偏差20
°
的旋转边界框的交并比riou的值为0.4,因此设计负责检测舰船目标的同一中心点、长和宽的先验框的角度偏差为20
°
,保证先验框能够匹配到任意角度的旋转目标;
64.步骤3)对基于特征增强的光学图像旋转目标检测网络模型进行迭代训练:
65.(3a)初始化迭代次数为w,最大迭代次数为w,w≥10000,并令w=1;
66.本实施例中,w=300000,设计w=300000是为了让网络训练更充分;
67.(3b)将从训练样本集随机选取的b个训练样本作为光学图像旋转目标检测网络模型的输入进行前向传播,主干网络中的特征提取子网络对每个训练样本的所有目标进行特征提取,特征增强子网络对特征提取子网络所提取的特征进行合并后,对合并后的特征进行卷积融合,得到融合后的语义特征和位置特征,检测网络中的定位子网络利用融合后的位置特征计算目标预测边界框,分类子网络利用融合后的语义特征计算目标预测类别,其中,b≥10;
68.本实施例中,b=16,设计b=16是因为实验所用设备的内存限制,每次迭代的训练样本的数量最大只能设置到16,否则超出内存;
69.(3c)定位子网络采用smoothl1函数,并通过目标的预测边界框和目标的边界框位置标签计算目标的位置损失值l1,分类子网络采用交叉熵函数,并通过目标的预测类别置信度和目标的类别标签计算目标的类别置信度损失值l2,然后采用随机梯度下降法,并通过l1与l2的和对主干网络和检测网络中的卷积核权重参数ω
w
和全连接层结点之间的连接权重参数θ
w
进行更新;
70.步骤(3c)中所述的目标的位置损失值l1、目标的类别置信度损失值l2、smoothl1函数和交叉熵函数的表达式,以及卷积核权重参数ω
w
和各全连接层结点之间的连接权重参数θ
w
的更新公式分别为:
[0071][0072][0073][0074][0075]
[0076][0077]
其中,gtbox
i
为第i个目标的边界框位置标签,pbox
i
为第i个目标的预测边界框,p
i
为第i个目标的m类的预测类别置信度向量,p
ij
为第i个目标第j类的预测类别置信度,y
i
为第i个目标的m类的类别标签向量,若第i个目标的类别为c,则y
i
=[0,
…
,1,
…
,0],1的位置在类别标签向量y
i
的第c个位置,y
ij
为y
i
的第j个位置的值,k’表示目标总数;η表示学习率,1e
‑
6≤η≤0.1,ω
w+1
和θ
w+1
分别表示ω
w
和θ
w
更新后的结果,表示偏导计算;
[0078]
本实施例中,初始学习率η=0.001,在迭代到第15万次时,学习率η=0.0001,迭代到第20万次时学习率η=0.00001,优化器函数使用随机梯度下降sgd,学习率在网络迭代到一定次数时进行衰减的是为了防止损失函数陷入局部最小值;
[0079]
(3d)判断w=w是否成立,若是,得到训练好的基于特征增强的光学图像旋转目标检测网络模型,否则,令w=w+1,并执行步骤(3b);
[0080]
步骤4)获取光学图像旋转目标的自适应检测结果:
[0081]
(4a)将测试样本中的每幅光学子图像作为训练好的基于特征增强的光学图像旋转目标检测网络的输入,进行目标的边界框位置和目标的类别置信度检测,得到中所有目标的边界框位置和类别置信度,并滤除目标类别置信度中低于置信度阈值λ的目标边界框位置和类别置信度,得到过滤后的目标边界框位置和类别置信度,然后通过旋转目标的非极大值抑制rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到的过滤后的目标边界框和类别置信度;
[0082]
步骤(4a)中所述的旋转目标的非极大值抑制rnms方法具体步骤为:
[0083]
(4a1)对所有旋转目标的类别置信度进行排序,得到一个旋转目标的边界框的集合{b1,b2,
…
,b
f
,
…
,b
n
},其中,b
f
表示{b1,b2,
…
,b
f
,
…
,b
n
}中第f个边界框;
[0084]
(4a2)分别计算边界框b1与边界框b
f
的交并比若大于旋转边界框交并比阈值则说明边界框b
f
与边界框b1检测的是同一目标,因此将边界框b
f
从集合中删去,若小于等于旋转边界框交并比阈值则说明边界框b
f
与边界框b1检测的不是同一目标,因此保留边界框b
f
,得到一个新的旋转目标的边界框的集合其中,b
f
∈{b2,b3…
,b
f
,
…
,b
n
};
[0085]
(4a3)若结束;否则将集合替代集合{b1,b2,
…
,b
f
,
…
,b
n
},执行步骤(4a2);
[0086]
(4b)对测试样本中的每幅光学子图像进行l1倍缩小和l2倍放大,并将缩小后的光学子图像和放大后的光学子图像作为训练好的基于特征增强的光学图像旋转目标检测网络的输入,进行目标的边界框位置和目标的类别置信度检测,得到和中所有目标的边界框位置和类别置信度,并滤除目标类别置信度中低于置信度阈值λ的目标边
界框位置和类别置信度,得到过滤后的目标边界框位置和类别置信度,然后通过旋转目标的非极大值抑制rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到的过滤后的目标的边界框和类别置信度,以及的过滤后的目标的边界框和类别置信度;
[0087]
本实施例中,l1=1,l2=0.5,λ=0.5,对图像进行0.5倍放大,是为了将小尺度目标和中尺度目标放大,特征提取子网络对特征进行5次下采样后依然能够提取更多小尺度目标和中尺度目标的特征,进而检测出更多的小尺度目标和中尺度目标,提升小尺度目标和中尺度目标的召回率;对图像进行1倍缩小,是为了实现图像分辨率为1米和2米的自适应检测,进而提升目标的召回率。
[0088]
(4c)对和中的过滤后的目标边界框位置和类别置信度进行合并,并通过rnms方法对同一目标重复检测的边界框位置的目标的边界框和类别置信度进行过滤,得到所有目标的边界框位置和类别置信度,
[0089]
以下结合仿真实验,对本发明效果作进一步说明:
[0090]
1.仿真条件和内容:
[0091]
仿真实验采用如图3所示的从“谷歌地图”下载的国内外多个地区的17级和18级光学图像,地面分辨率1米和2米。
[0092]
仿真实验在cpu型号为intel(r)core(tm)i7
‑
8750h、gpu型号为nvidia geforce rtx 2080 ti的服务器上进行。操作系统为ubuntu 16.04系统,深度学习框架为caffe,编程语言为python3.5;
[0093]
对本发明和现有的一种基于yolov3的旋转目标检测方法的召回率进行对比仿真,其结果如图4所示;
[0094]
2.仿真结果分析:
[0095]
参照图4,图4(a)为现有技术对图3进行光学图像舰船目标检测,其中,旋转边界框指出检测出的舰船目标的位置,旋转边界框的上方文字显示了目标的类别置信度,从图4(a)可以看出,图中大多数舰船目标都能被检测到,但是存在较多漏检的舰船目标;图4(b)为本发明对图3进行光学图像舰船目标检测,其中,旋转边界框指出检测出的舰船目标的位置,旋转边界框的上方文字显示了目标的类别和类别置信度,从图4(b)可以看出,只有少量的漏检舰船目标,并可以检测到密集排列的舰船目标。由此说明,本发明能够检测出绝大多数舰船目标,提升了旋转目标检测的召回率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1