一种光伏发电运维系统的设计方法
本发明涉及光伏发电技术领域,具体涉及一种光伏发电运维系统的设计方法。
背景技术:
太阳能是一种重要的清洁能源。然而,光伏电站因为受天气、光照等因素的影响导致发电功率具有不稳定性,往往与输入现有电网的额定功率差别较大,在光伏电站并网时可能会对现有电网产生危害,会影响到电力调度。除此之外,太阳能电池板为了吸收光能往往直接暴露在外部环境,其表面因此常常受到沙尘、落叶、鸟粪等污染物污染,降低了太阳能电池工作效率。因此,建立光伏发电运维系统具有较高的应用价值。而现有的光伏发电运维系统需要人工检查光伏阵列是否被污染,效率低下,且采用机器人定期清洗则可能造成资源浪费。
技术实现要素:
针对人工检查光伏阵列是否需要清洗的方式效率低下,机器人定期清洗可能造成资源浪费这一问题,本发明提出了一种基于深度学习算法的光伏发电运维系统和方法,旨在于实时观察光伏组件工作状态,当光伏阵列受到污染时自动发出警报,同时能预测未来一段时间内发电功率以方便电力调度。
本发明的目的通过以下的技术方案实现:
一种光伏发电运维系统的设计方法,包括如下步骤:
s1、建立基于卷积神经网络和残差连接的inception-resnet-v2模型,将模型应用于光伏阵列污染图像分类任务中;
s2、编写基于gru-lightgbm(gatedrecurrentunit-lightgradientboostingmachine)集成的光伏发电功率预测模型;
s3、开发基于ssm框架的光伏运维系统,利用ajax技术实现数据动态更新,利用echarts框架实现数据可视化;
s4、在云端服务器上部署光伏运维系统,将inception-resnet-v2模型分类结果响应到前端,实现污染警报和运维功能,将gru-lightgbm模型预测值响应到前端,实现光伏发电功率预测功能。
进一步地,步骤s1所述的基于卷积神经网络和残差连接的inception-resnet-v2模型等主要包括:
inception-resnet-v2神经网络模型的基础算法来源于卷积神经网络。在图像识别任务中,深度卷积神经网络通过逐层组合低级的特征来建立原始图像的高级特征。cnn神经网络通常由若干个卷积层和子采样层组成,其中子采样层也称池化层,层与层之间没有跨越连接,在网络最后一层使用单层或多层全连接层输出分类结果。卷积计算思想是通过输入的图像与矩阵参数项连接得到特征映射,输出若干个特征图,每个特征图中的每个元素均由初始输入图片中部分像素计算得到。
卷积层的计算过程以二维图像卷积计算为例,其公式如下:
y=x*w(1)
式(1)中,表示卷积计算,x表示输入的样本,大小为
进一步地,建立基于卷积神经网络和残差连接的inception-resnet-v2模型还包括:在inception-resnet-v2网络中建立了1×1卷积层,该卷积层的作用是分开通道特征的学习和空间特征的学习,并且可以在残差连接前对过滤器按比例缩放,以匹配网络的输入。由于光伏阵列图像数据各像素位的数值大小差异较大,因此在模型训练之前,需要对光伏阵列图像数据标准化处理,处理公式为:
式(3)中,xi为标准化前的数据,x′i为标准化后的数据,n为总样本量。
进一步地,步骤s2所述基于gru-lightgbm集成的光伏发电功率预测模型等主要包括:
集成了gru和lightgbm两种模型:采用keras深度学习框架建立gru回归预测模型,采用lightgbm机器学习库建立lightgbm回归预测模型。本预测模型采集的数据包含功率、天气湿度、光照强度、风速、温度、天气、风向等特征,其中除天气与风向特征外均为非语义类数值型特征,无需对此类特征采用语义分析算法进行处理。针对非语义类特征,由于神经网络可能会将数值较大的特征训练较大的权重,将数值较小的特征训练较小的权重,从而导致模型预测效果差,所以对非语义类特征进行标准化处理,采用公式为:
式(4)中,μx为特征均值,σx为特征方差。
对于语义类特征数据,采用词频-逆文本频率(tf-idf)算法,根据词频计算不同样本数据中天气或风向特征之间的区别。词频的计算公式为:
逆文本频率为总文本数与文本中含有该词的文本数量加1的比值后取对数,公式为:
tf-idf的公式为:
tf-idf=tf×idf(7)
式(5)(6)(7)中,t为某个样本中含词t的数量,|d|为文本总数,d:t∈d为文本中含词t的文本数量。
进一步,步骤s3包括:本地数据库开发,根据在光伏运维系统的前端显示界面需要展示的信息,在mysql数据库中新建一个数据库,命名为alldata,并且在alldata数据库中建立四张表,分别为电池工作状态信息、电网状态信息、逆变器工作状态信息与工作信息、双入输入信息,对应的表名称分别为cell、net、input和output,并将四张表均设置为主键自增长,用于自动增加记录表的行数。
基于ssm框架的光伏运维系统,由spring、springmvc和mybatis三个轻量级框架整合开发,其中spring和springmvc主要负责系统接收前端的请求,进行请求操作后,将结果封装成json数据格式响应至前端,前端程序接受到响应后,立刻将json数据解析再赋值到前端界面对应位置的变量中。
进一步地,步骤s4所述在云端服务器上部署光伏运维系统,主要包括:
在云服务器上部署tomcatweb服务器,测试启动成功,部署光伏运维系统;部署云端数据库,测试数据库远程连接,数据库可实现远程数据传输功能。
部署光伏运维系统,测试双入输入模块、逆变器模块、电池与电网模块、功率曲线模块中实际曲线部分、实时效率模块和天气预报模块。
一方面,用户可以通过运维界面实时观察到光伏阵列的工作状态,可以快速判断光伏发电系统是否出现故障,方便用户维护;其次,运维界面提供报警模块,可以向用户反映光伏阵列是否受到污染,方便用户决定是否需要对太阳能电池表面进行清洗,节省定期清洗造成的清洗资源浪费;除此之外,光伏运维系统提供光伏发电功率预测功能,可以观察到未来一段时间内的发电功率,方便用户决定电力调度规则。
本发明相对于现有技术具有如下优点:
本发明一方面,用户可以通过运维界面实时观察到光伏阵列的工作状态,可以快速判断光伏发电系统是否出现故障,方便用户维护;其次,运维界面提供报警模块,可以向用户反映光伏阵列是否受到污染,方便用户决定是否需要对太阳能电池表面进行清洗,节省定期清洗造成的清洗资源浪费;除此之外,光伏运维系统提供光伏发电功率预测功能,可以观察到未来一段时间内的发电功率,方便用户决定电力调度规则。
附图说明
构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
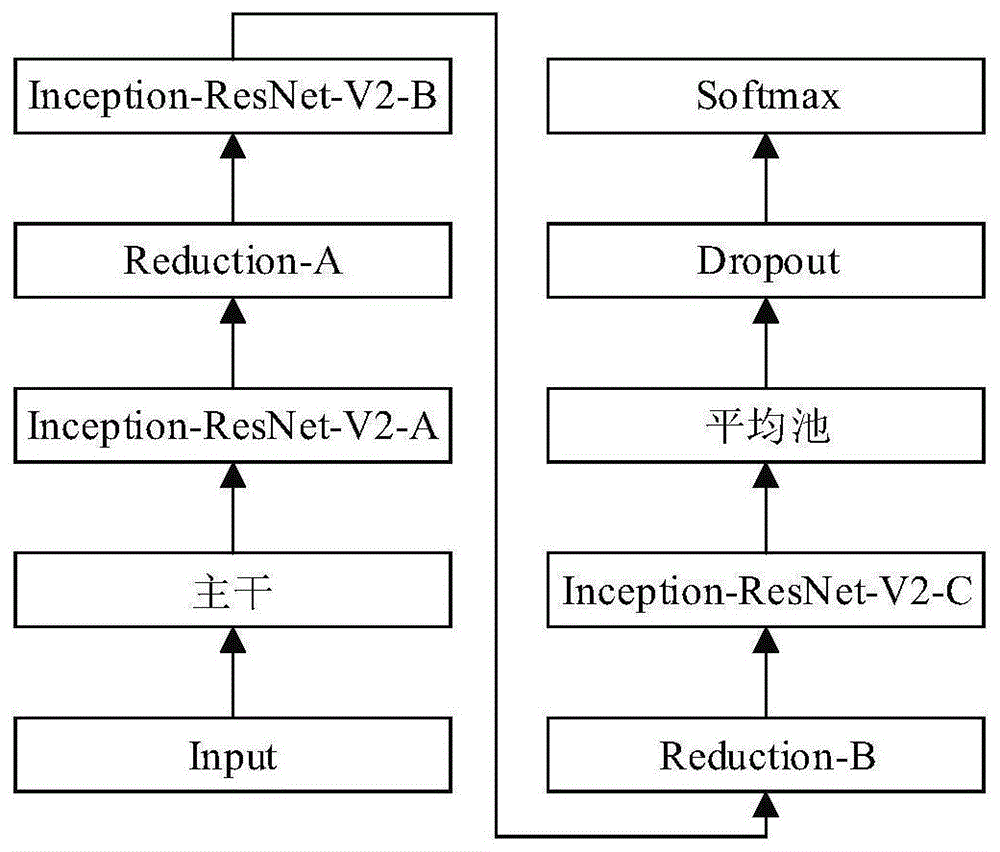
图1为本实施例的inception-resnet-v2网络建模流程图。
图2为本实施例的基于卷积神经网络的光伏阵列污染图像模型仿真流程图。
图3的(a)为本实施例的inception-resnet-v2分类模型在进行未受污染光伏图像的测试图。
图3的(b)为本实施例的inception-resnet-v2分类模型在进行受污染光伏图像的测试图。
图4为本实施例的gru-lightgbm建模流程图。
图5的(a)为本实施例在晴天天气下的光伏发电功率预测曲线图。
图5的(b)为本实施例在阴天天气下的光伏发电功率预测曲线图。
图5的(c)为本实施例在晴转多云天气下的光伏发电功率预测曲线图。
图5的(d)为本实施例在阴转多云天气下的光伏发电功率预测曲线图。
图6为本实施例的光伏运维系统架构图。
图7的(a)为本实施例的光伏运维系统在光伏阵列无污染时的显示效果图。
图7的(b)为本实施例的光伏运维系统在光伏阵列受污染时的显示效果图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
图1所示为inception-resnet-v2网络建模流程图。nception-resnet-v2网络模型较深,所以对网络采用模块化建模和编程,分为主干模块、inception-resnet模块和降维模块。dropout表示淘汰规则优化网络,inception-resnet-v2-a、inception-resnet-v2-b、inception-resnet-v2-c表示网络的三个分支模块;reduction-a与reduction-b降维模块作用是缩放前一层输出的大小,以匹配连接下一层模块的输入维度。inception-resnet-v2网络的主干模块经过三个卷积层后,进行第一次分裂,其中一分支进入池化层,另一分支进入卷积层,计算结束后将两分支连成一层,由此处进行第二次分裂,二次分裂的两分支分别进入若干层卷积层,之后再连为一层,连接后进行第三次分裂,第三次分裂的一支进入池化层,另一支进入卷积层,计算结束后将两分支连成一层。
图2所示为基于卷积神经网络的光伏阵列污染图像模型仿真流程图。
其具体步骤为:
(1)采集光伏阵列图像作为初始数据。
(2)原始数据进行预处理,对所采集的图像进行去色处理,并将所采集的图像压缩至相同大小。将所有图像分成训练集、验证集和测试集三个数据集,且每个数据集中受污染图像与洁净图像的比例相同,防止出现不平衡数据集使模型无法得出精确的结果。
(3)引入keras深度学习框架必要的类与方法,包括input、dropout、dense、flatten、activation、concatenate、conv2d、maxpool2d、averagepooling2d和model对象,利用引入对象编写模型主干模块程序,将该模块定义为stem方法。
(4)调整模型参数,设置模型的迭代次数;根据模型的损失值是否趋近于0判断是否需要返回程序调节参数重新训练模型。
(5)绘制损失曲线和精度曲线,分析模型是否发生过拟合或欠拟合。若模型在训练集上的损失曲线收敛且趋于0,在验证集上的损失曲线与其差别较大,则说明该模型过拟合;若模型在训练集和验证集上的损失曲线均不收敛或均不趋于0,则说明该模型欠拟合。
(6)绘制roc_auc曲线,模型实际分类结果越逼近左上角曲线则说明该分类器分类精度越高,如果模型的roc_auc曲线在随机分类器曲线下方,则说明模型不可用。
(7)仿真结束保存模型。
图3为inception-resnet-v2分类模型测试图,向模型输入未受污染的光伏阵列图像数据,模型向前端响应结果为无污染,如图3的(a)所示;向模型输入受污染的光伏阵列图像数据,模型向前端响应结果受无污染,如图3的(b)所示。
图4为gru-lightgbm建模流程图。gru-lightgbm集成模型在建模过程中,采用keras深度学习框架建立gru回归预测模型,采用lightgbm机器学习库建立lightgbm回归预测模型。在进行数据采集、数据预处理后,生成训练集、验证集和测试集,分别使用gru模型和lightgbm模型进行验证分析。当模型在训练集和验证集上的损失几乎不再变化且趋于0时,此时可认为模型已经收敛,进一步绘制模型损失曲线没有出现欠拟合或过拟合的问题时,保存网络模型。
图5的(a)-(d)为不同天气情况下的光伏发电功率预测曲线。由图5的(a)-(d)可以观察到,各个模型在发电功率变化比较平稳条件下的预测效果均比较好,其中gru-lightgbm模型预测曲线比其它模型更贴近真实曲线;在晴转多云这种发电功率有突变的天气情况下,lstm模型和dbn模型的预测曲线与实际曲线拟合偏差较大,尤其在发电功率突变点的预测值与真实值相距甚远,相比之下,gru-lightgbm模型的预测曲线比lstm模型和dbn模型更贴近真实曲线,在突变点的预测值与真实值之差小于lstm与dbn模型的预测值与真实值之差;在阴转多云这种全天天气变化较大,光伏发电功率出现较大波动的情况下,lstm与dbn预测模型已经无法准确地拟合实际发电功率曲线,模型欠拟合程度较高,然而,gru-lightgbm模型依然逼近实际曲线。
图6为光伏运维系统架构图。本发明开发的光伏运维系统由spring、springmvc和mybatis三个轻量级框架整合开发,其中spring和springmvc主要负责系统接收前端的请求,进行请求操作后,将结果封装成json数据格式响应至前端,前端程序接受到响应后,立刻将json数据解析再赋值到前端界面对应位置的变量中。mybatis则主要负责数据库操作服务。在光伏运维系统的架构流程中,先由用户发送请求至前端控制器dispatcherservlet类对象,dispatcherservlet类对象收到用户请求后会调用处理器映射器handlermapping,通过一组已注册的处理器适配器中寻找到一个与该处理器适配器相匹配的处理器适配器handleradaptor,通过指定的处理器适配器把控制流转发给处理器,处理器完成并结束调用业务逻辑后,将模型数据以及逻辑视图传回到前端控制器,前端控制器在接收到逻辑视图后会通过视图解析器viewresolver对象将一个逻辑视图映射到真正的视图,该真正的视图返回至前端控制器,前端控制器获得返回的真视图后将控制权交给视图,同时传入模型数据,视图通过视图层的定义,将数据展现至前端界面,完成相应请求。
图7的(a)为本实施例的光伏运维系统在光伏阵列无污染时的显示效果图。图7的(b)为本实施例的光伏运维系统在光伏阵列受污染时的显示效果图。在系统前端的显示界面中,主要包括:双入输入模块、逆变与输出模块、电池与电网模块、功率曲线、实时效率、污染警报以及天气预报,各模块的功能如表格1:
表格1光伏运维系统功能模块
上述具体实施方式为本发明的优选实施例,并不能对本发明进行限定,其他的任何未背离本发明的技术方案而所做的改变或其它等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!