一种基于图分类的套利团伙识别方法与流程
1.本发明涉及电子信息技术领域,特别涉及一种基于图分类的套利团伙识别方法。
背景技术:
2.随着互联网技术的快速发展,给金融、电商等行业带来了新的机遇和挑战。平台和商家可以借助网络在线上发布各种优惠活动来吸引用户,增加流量,但却有这样一群人他们通过各种手段在多个平台套取营销活动的优惠,甚至已经形成了一条完整的产业链,称之为羊毛党或套利团伙。这些套利团伙给商家和平台造成了巨大的损失,据统计每年由于黑产套利造成的经济损失达到百亿。现有的识别套利团伙的方法主要还是以专家规则和传统的机器学习模型为主,专家规则虽然可解释性强,但是需要对历史风险事件的总结和归纳,而且总结的规则可能因人而异,一致性较差,响应速度慢。传统机器学习模型的识别维度主要是单用户或单商户,很难识别这种团伙性质的异常,因为往往从单个用户的维度看这些套利用户都没有问题,但是将一个套利团伙的用户放到一起异常却很明显。而图能够更加直接、自然地展现团伙内部的关联关系,在处理团伙识别问题上具有天然的优势。
技术实现要素:
3.本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于图分类的套利团伙识别方法,针对现有的套利团伙识别问题,提出一种有效的检测手段,具有较高的准确率和较好的鲁棒性。
4.本发明提供了如下的技术方案:
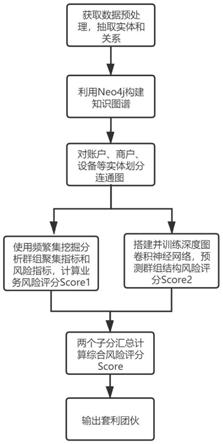
5.本发明提供一种基于图分类的套利团伙识别方法,包括以下:
6.s1:获取数据预处理,抽取构图的实体和关系,构建知识图谱;
7.s2:对构建好的图谱,利用连通子图算法进行群组划分;
8.s3:计算每个群组的风险指标信息,形成业务风险评分;
9.s4:搭建并训练深度图卷积神经网络,用于预测群组的结构风险评分;
10.s5:综合业务风险评分和结构风险评分计算群组的综合风险评分,筛选风险群组;
11.上述的步骤s1,包含:
12.s1.1:从业务数据表中获取原始交易数据和操作数据,进行数据清洗等预处理工作,抽取构图所需的实体和关系信息。实体包括:账户、商户、设备、ip等;关系包括:消费,登录,转账,提现等;
13.s1.2:根据步骤s1.1中抽取的实体和关系,将数据导入图数据库neo4j构建图谱,或使用networkx等构图工具构图,当数据量较大时neo4j的性能明显优于networkx;
14.上述的步骤s2,包含:
15.s2.1:基于步骤s1.2中构建的图谱,采用连通子图算法在全图上进行子图划分,形成一个个彼此之间互相割裂,但内部联系紧密的群组;
16.上述的步骤s3,包含:
17.s3.1:根据步骤s2.1划分的用户群组,使用fp-growth频繁集挖掘算法,计算群组中用户的聚集度指标,得到聚集度评分;
18.s3.2:基于步骤s3.1的聚集度指标和现有的用户黑名单、设备黑名单等,计算群组的风险程度评分;
19.s3.3:基于步骤s3.1和步骤s3.2中得到的聚集度评分和风险程度评分,计算群组总的业务风险评分;
20.上述的步骤s4,包含:
21.s4.1:搭建深度图卷积神经网络,模型可以接受任意的图作为输入而不限制图的结构和节点数量,基于部分标签群组训练神经网络。
22.s4.2:基于步骤s4.1的训练好的神经网络,将步骤s1.2中得到的用户群组作为输入,得到每个群组是否是套利群组的概率,将该概率处理后作为每个群组的结构风险评分;
23.上述的步骤s5,包含:
24.s5.1:基于步骤s3和步骤s4中得到的群组业务风险评分和群组结构风险评分,计算每个群组的综合风险评分,筛选群组综合风险评分大于一定阈值的群组或取前topn的群组,作为风险群组输出。
25.与现有技术相比,本发明的有益效果如下:
26.本发明根据套利团伙的特性,通过构建知识图谱的方式能够直接、自然地展现群组中账户之间的关联关系,资金流向等。同一个套利团伙的成员之间必定通过某种关系相联系。所以采用连通子图算法对构建的图谱进行群组划分,可以使得套利团伙更容易被发现;
27.同时,本发明采用深度图卷积神经网络对整个图进行分类,直接预测整个群组的风险,很多套利团伙具有典型的结构特征,如雪花结构,链式结构等。而传统的图神经网络都是预测群组中单个实体的风险,未能充分考虑图结构的信息,不能有效识别套利团伙;
28.最后,本发明不仅通过深度图神经网络判断群组的结构风险,同时还结合业务指标,使用频繁集挖掘算法分析群组的业务指标信息,计算业务风险评分,和业务数据相结合,增加了模型结果的可解释性。
附图说明
29.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
30.图1是本发明的系统总体示意图;
31.图2是本发明的图分类网络结构图;
32.图3是本发明的图卷积过程示意图。
具体实施方式
33.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
34.实施例1
35.如图1-3,本发明实施例提供的基于图分类的套利团伙识别方法,首先获取用户的交易和操作数据进行预处理,抽取构图的实体和关系,构建知识图谱,并对构建好的图谱,采用连通子图算法进行群组划分。然后计算每个群组的风险指标信息,形成业务风险评分。接着搭建并训练深度图卷积神经网络,预测群组的结构风险评分。最后综合业务风险评分和结构风险评分计算群组的综合风险评分,筛选风险群组。
36.图1是根据实例的实施过程所展示的基于图分类的套利团伙识别方法的流程图,参照图1所示,该方法包括如下步骤:
37.s1:获取数据预处理,抽取构图的实体和关系,构建知识图谱;
38.s1.1:从业务数据表中获取原始交易数据和操作数据,进行数据清洗等预处理工作,抽取构图所需的实体和关系信息。实体包括:账户、商户、设备、ip等;关系包括:消费,登录,转账,提现等;
39.具体的,从交易数据表中获取用户的消费信息,从操作数据表中获取用户的登录信息,在本实施例中构图所需的实体有:账户,商户,银行卡,设备和ip,每种实体包含自身的属性信息。关系类型包括:账户和账户之间的转账关系,账户和商户之间的消费关系,账户和设备的登录关系,账户和ip的登录关系,账户和银行卡之间的提现关系,共计5种实体,5种关系。
40.s1.2:根据步骤s1.1中抽取的实体和关系,将数据导入图数据库neo4j构建图谱,或使用networkx等构图工具构图,当数据量较大时neo4j的性能明显优于networkx。
41.具体的,基于步骤s1.1中抽取的实体和关系,构建图谱。在本实施例中由于实体数量较大达到了2000多万,所以利用neo4j图数据进行构图和后面的连通子图划分。在此数据量级情况下,neo4j的性能明显优于networkx。若数据量较小,可以采用networkx构图,更加方便灵活。
42.s2:对构建好的图谱,利用连通子图算法进行群组划分;
43.s2.1:基于步骤s1.2中构建的图谱,采用连通子图算法在全图上进行子图划分,形成一个个彼此之间互相割裂,但内部联系紧密的群组。
44.具体的,在neo4j中利用连通子图算法将全图进行分割,形成一个个群组。每个用户有个群组编号,同一个群组中的用户群组号相同。
45.s3:计算每个群组的风险指标信息,形成业务风险评分;
46.s3.1:根据步骤s2.1划分的用户群组,使用fp-growth频繁集挖掘算法,计算群组中用户的聚集度指标,得到聚集度评分;
47.具体的,经过步骤s2已经得到所有用户的群组信息,每个用户只属于一个群组,一个群组中可能包含多个用户。套利团伙一般都有想对明显的聚集性,所以需要计算每个群组的聚集性指标。在本实施例中采用fp-growth频繁项集挖掘算法,计算群组中用户的聚集度指标,最后形成聚集度评分。
48.fp-growth算法针对每个群组的具体执行步骤如下:
49.1)扫描一次群组中的用户特征信息,找出频繁1项集合,记为l,并把它们按照支持度计数进行降序排列,本实施例中最小支持度计数为3;
50.2)基于步骤1)中的l,再次扫描群组用户信息,构造表示群组信息项集关联的fp树;
51.3)在fp上递归地找出所有频繁项集;
52.4)最后在所有频繁项集中产生强关联规则,即用户特征的关联信息。
53.使用频繁集挖掘算法得到每个群组的频繁项集和对应的支持度。利用每个群组最大的频繁项集l和最大频繁项集的支持度s计算每个群组的聚集度评分score1_1,计算公式如下:
[0054][0055]
其中size(g)表示群组g的大小,size(features)表示特征数。α用来控制支持度计数s和频繁项集大小l对聚集度分值的影响,本实施例中α取值为0.5;
[0056]
s3.2:基于步骤s3.1的聚集度指标和现有的用户黑名单、设备黑名单等,计算群组的风险程度评分;
[0057]
具体的,将群组中满足聚集度阈值的特征和业务现有的黑名单进行对比,计算这些特征命中黑名单的比例。在本实施例中使用的黑名单有:账户黑名单,ip黑名单,设备黑名单。风险评分score1_2的计算公式如下:
[0058][0059]
其中,phonenum,devicennum,modelnum分别表示群组中手机号数数量,设备数量,设备型号数量,blackphonenum,blackdevicenum,blackmodelnum则分别表示命中黑名单的手机号数量,设备数量和设备型号数量。
[0060]
s3.3:基于步骤s3.1和步骤s3.2中得到的聚集度评分和风险程度评分,计算群组总的业务风险评分。
[0061]
具体的,根据步骤s3.1中得到的聚集度评分score1_1和步骤s3.2中得到风险度评分score1_2,计算群组总的业务风险评分score1,计算公式如下:
[0062]
score1=(score1+score2)*50
[0063]
其中score1_1和score1_2分别为群组的聚集度评分和风险度评分,score1的分值范围为0到100。
[0064]
s4:搭建并训练深度图卷积神经网络,用于预测群组的结构风险评分;
[0065]
s4.1:搭建深度图卷积神经网络,模型可以接受任意的图作为输入而不限制图的结构和节点数量,基于部分标签群组训练神经网络;
[0066]
具体的,搭建一个用于图分类的深度图神经网络,网络结构如图2所示。在本实施例中网络主要由图卷积层,池化层,卷积层和全连接层4部分组成。卷积层主要用于融合周围节点的信息和网络结构的信息,使用3个图卷积层,最后一个图卷积层输出每个节点的特征维度为1,根据该值对图中所有节点进行排序,图卷积过程如图3所示。排好序的节点序列进入池化层,池化层用来对卷积层的输出进行标准化处理,池化层预先设定一个值k,用来限定进入池化层的节点数,若图中节点数大于k,则根据卷积层最后一层的排序结果从大到小取topk个节点,若图中节点数小于k,则补0,正因为有该池化层的存在,网络才可以处理任意结构和节点数量的图输入,本实施例中k值取20。将排好序的k个节点特征变成1维长向量,1位卷积层用于抽取节点序列的特征信息,最后接上全连接层完成分类任务。将准备好的有标签群组作为输入训练该网络,保证网络在测试集中表现稳定。
[0067]
s4.2:基于步骤s4.1的训练好的神经网络,将步骤s1.2中得到的用户群组作为输入,得到每个群组是否是套利群组的概率,将该概率处理后作为每个群组的结构风险评分。
[0068]
具体的,将训练好的深度图神经网络用于预测步骤s1.2中的每个用户群组,将每个群组的预测概率乘以100作为改群组的结构风险评分score2,计算公式如下:
[0069]
score2=(prob)*100
[0070]
其中prob为网络预测输出该群组的概率,score2的分值范围为0到100。
[0071]
s5:综合业务风险评分和结构风险评分计算群组的综合风险评分,筛选风险群组。
[0072]
s5.1:基于步骤s3和步骤s4中得到的群组业务风险评分和群组结构风险评分,计算每个群组的综合风险评分,筛选群组综合风险评分大于一定阈值的群组或取前topn的群组,作为风险群组输出。
[0073]
具体的,将步骤s3和步骤s4中得到的群组业务风险评分score1和群组结构风险评分score2加权平均,作为群组的总和风险评分score,计算公式如下:
[0074]
score=α*score1*(1-α)*score2
[0075]
其中,本实施例中α取值为0.5,具体使用中可以根据业务需求做调整。
[0076]
最后,挑选出群组风险分值大于一定阈值的群组或取前topn的群组,作为风险群组输出。在本实施例中选取套利风险分大于80的为高风险群组,将这些群组中的用户加入营销黑名单,其余中风险群组则由人工进行复核审查。
[0077]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1