一种结合小波变换和张量网络的医学图像分类方法
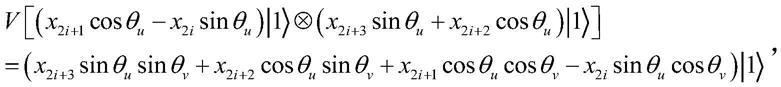
1.本发明涉及医学图像分类技术领域,尤其涉及一种结合小波变换和张量网 络的医学图像分类方法。
背景技术:
2.近几十年来,机器学习得到了蓬勃的发展,出现了许多算法,它们在各自的 时代都被证明是足够好的,例如朴素贝叶斯( bayes)、核方法(kernelmethods)、决策树(decision trees)、随机森林(random forests)和神经网络(neuralnetworks,nns)。近年来,深度神经网络取得了惊人的成功。卷积神经网络 (convolutional neural networks,cnns)是最成功的深度神经网络之一,其卷积 层能够从原始数据中提取出重要特征,再由池化层对数据进行压缩,最后输入全 连接层得到预测结果。
3.在医学图像分析领域,cnns模型及其变体被广泛用于结肠镜检查、hep-2 细胞图像分类、乳腺肿块分类、脑小血管疾病的生物标志物检测和皮肤癌分类。 过去两年新型冠状病毒(covid-19virus)在全球范围内大肆传播,使得人们更加 重视智能医学领域,研究人员正在思考如何使用机器协助人类战胜疾病。精确的 计算机医学图像分析工具可以协助医生识别和定位病灶,提高诊断效率和准确 性。医学图像包括x射线、计算机断层扫描(ct)、磁共振成像(mri)、正电 子发射断层扫描(pet)和超声波等,将它们用于训练深度学习模型并不容易。 首先,医学图像一般存在各种质量的失真和退化,例如噪声、模糊和压缩效应。 并且,与自然图像不同,标记大量医学图像既昂贵又耗时,因此可用于训练深度 神经网络模型的医学图像总是有限的。最后,医学图像分类任务在要求模型具有 高精度的同时还要求模型的预测结果有据可依。
4.因此,cnns及其变体在用于医学图像分类任务时具有不可避免的缺点。随 着模型层数的加深,医学图像的失真会导致更多的偏差;小数据集通常会导致深 度神经网络在训练时出现过拟合的现象;在经典机器学习算法中,可解释性和高 精度往往是鱼和熊掌的关系,cnns当中的非线性运算为其带来了出色的准确率, 但也限制了其可解释性。因此,人们渴望找到一种方法,既可以兼顾cnns的优 点,又可以弥补其缺点。
技术实现要素:
5.本发明提供一种结合小波变换和张量网络的医学图像分类方法,解决的技 术问题在于:现有医学图像分类方法在小数据集下无法兼顾高准确率、避免过拟 合和可解释性。
6.为解决以上技术问题,本发明提供一种结合小波变换和张量网络的医学图 像分类方法,包括步骤:
7.s1、将具有n个像素的医学二维灰度图像展平为长度为n的一维向量v(x);
8.s2、将一维向量v(x)中的每一个元素xi特征映射为希尔伯特空间当中的一个 量子态,得到n个量子态;
9.s3、通过结合了小波变换和张量网络的粗粒化网络对n个量子态进行l次粗 粒化处理,每次输出一个仅含有单个|1>态的项,从而得到l个仅含有单个|1>态的 项作为粗粒化输出;
10.s4、将该粗粒化输出特征映射为多个特征值并通过张量积连接起来输入训 练完成的张量分类网络中,得到预测的分类结果。
11.进一步地,在所述步骤s3中,所述粗粒化网络基于粗粒化单元构建,所述 粗粒化单元包括两个解纠缠器和一个等距;该两个解纠缠器用于输入通过张量 积连接的步骤s2所得n个量子态中的四个相邻量子态,通过解纠缠各自得到一 个仅含有单个|1>态的项;该等距用于对该两个解纠缠器输出的两个仅含有单个 |1》态的项进行粗粒化操作,得到对应的一个仅含有单个|1>态的项。
12.进一步地,分别用u、v表示解纠缠器和等距,则u、v定义为:
[0013][0014][0015]
其中,θu=-π/6,θv=π/12。
[0016]
进一步地,所述粗粒化网络由解纠缠器和等距组成多层网络结构,每层网络 结构包含2个以上解纠缠器和1个以上等距,每个解纠缠器具有两个输入指标 和两个输出指标,每个等距具有两个输入指标和一个输出指标;每层网络结构的 最后一个解纠缠器与第一个解纠缠器通过一个附加的等距相连接;
[0017]
在非顶层的网络结构中,一个等距的两个输入指标各连接相邻两个解纠缠 器的一个输出指标,一个解纠缠器的两个输出指标各连接相邻两个等距的一个 输入指标,同一层中各个等距的输出指标连接下一层网络结构中解纠缠器的输 入指标;
[0018]
在最底层的网络结构中,每相邻两个解纠缠器的四个输入指标用于输入通 过张量积连接的步骤s2所得n个量子态中的每四个相邻量子态;
[0019]
每个解纠缠器用于保留输入的张量积连接下的两个量子态的纠缠,并解除 这两个量子态与输入其他解纠缠器量子态之间的纠缠,每个解纠缠器分别从两 个输出指标输出仅含有单个|1>态的第一项和第二项,其中第一项、第二项分别 为该两个量子态在尺度函数运算中位于后两位和前两位输入时得到的结果;
[0020]
每个等距用于对输入的张量积连接下的两个仅含有单个|1》态的项进行粗粒 化操作,得出输入到与其相连的两个解纠缠器中的4个相邻量子态经过d4小波 变换后的结果。
[0021]
进一步地,在步骤s2中,一维向量v(x)中的第i个元素xi被映射为:
[0022]
|φ(xi)》=|0》+xi|1》。
[0023]
进一步地,在步骤s3中,对四个相邻量子态组成的张量积由相邻的第一解纠缠器、第二解纠缠器以及 所述
第一解纠缠器、所述第二解纠缠器均连接的第一等距进行粗粒化的过程包 括步骤:
[0024]
s31、第一解纠缠器对张量积进行解纠缠,输出只含有单个 |1》态的第二项至第一等距中;第二解纠缠器对张量积进行解纠 缠,输出只含有单个|1》态的第一项至第一等距中;
[0025]
s32、第一等距对输入的两个只含有单个|1>态的项进行张量积操作,得到只 含有单个|1>态的项输入该第一等距连接的下一层网络结构中的一解纠缠器中。
[0026]
进一步地,第一解纠缠器根据自身的定义对张量积进行解纠 缠,用公式表示为:
[0027][0028]
其中,(x
2i+1
sinθu+x
2i cosθu)|1>、(x
2i+1
cosθ
u-x
2i sinθu)|1>分别为第一解纠缠器输出 的仅含有单个|1》态的第一项和第二项;
[0029]
同理,第二解纠缠器输出的仅含有单个|1》态的第一项和第二项分别为 (x
2i+3
sinθu+x
2i+2
cosθu)|1》、(x
2i+3
cosθ
u-x
2i+2
sinθu)|1》:
[0030]
则第一等距根据自身的定义对第一解纠缠器输出的第二项和第二解纠缠器 输出的第一项进行张量积得到只含有单个|1》态的项,用公式表示为:
[0031][0032]
其中,作用到原始输入数据(x
2i x
2i+1 x
2i+2 x
2i+3
)上的系数为:
[0033][0034]
进一步地,所述步骤s4具体包括步骤:
[0035]
s41、保留步骤s3所得粗粒化输出中所有|1》态的项的系数,并使用离差标 准化方法将这l个系数值归一化到区间[0,1]当中,得到l个归一化值;
[0036]
s42、采用如下公式对l个归一化值进行特征映射:
[0037][0038]
其中,x指代l个归一化值中的任一个,φ(x)表示对x映射后得到的特征 值;
[0039]
s43、通过张量积将步骤s42得到的l个特征值连接起来,得到该医学二维 灰度图像对应的全局特征映射;
[0040]
s44、将该全局特征映射输入训练完成的张量分类网络中,预测得到该医学 二维
灰度图像的分类结果。
[0041]
进一步地,张量分类网络采用矩阵乘积态,用线性决策函数表示为:
[0042][0043]
其中,fj(x)表示张量分类网络对第j个样本的预测结果,φ(x)j表示数据集 中第j个样本的全局特征映射,w表示权重矩阵,由l个权重张量组成, n=0,1,2,....,l,经数据集训练后,w固定不变。
[0044]
进一步地,在训练张量分类网络的过程中,使用交叉熵损失函数来计算张量 分类网络的预测结果和真实标签之间的距离,并使用反向传播算法来更新张量 分类网络中的权重张量;交叉熵损失函数表示为:
[0045][0046]
其中,yj表示第j个样本的标签,正类为1,负类为0;pj表示第j个样本被 预测为正类的概率。
[0047]
本发明提供的一种结合小波变换和张量网络的医学图像分类方法,提出一 种在医学图像上表现优异的粗粒化网络,该粗粒化网络结合了小波变换和 mera(多尺度纠缠重整化拟设,multi-scale entanglement renormalizationansatz),即将d4小波编码到mera中,形成一个内部参数固定的模型,本发 明将其命名为waveletmera。本发明还构建一个如全连接层般的可训练张量网 络(即张量分类网络)。本发明使用mnist数据集、covid-19数据集和lidc数 据集进行多维验证,结果表明waveletmera的准确率稳定居高,比cnns的深 度神经网络具有更好的粗粒化能力,这种能力使waveletmera能够在保证精度 的同时,更大程度上减少模型的参数量。结果表明waveletmera不仅在分类上 优于当前主流的深度神经网络,而且在数据预处理方面也优于普通小波变换。不 仅如此,waveletmera还具有张量网络本身的可解释性优势,能够为医生提供 更有针对性、更高效的诊断协助,缓解医疗紧张和医患冲突问题。
附图说明
[0048]
图1是本发明实施例提供的张量和张量运算的图形符号表示图;
[0049]
图2是本发明实施例提供的cnns与mera的结构图;
[0050]
图3是本发明实施例提供的d4小波变换中原始数据、尺度函数和小波函数 的关系图;
[0051]
图4是本发明实施例提供的8位量子多体态的4种张量网络表示图;
[0052]
图5是本发明实施例提供的mera两种张量的性质示意图;
[0053]
图6是本发明实施例提供的随着距离x的增加,mps和mera捕捉数据之 间相关性能力的衰减曲线图;
[0054]
图7是本发明实施例提供的实现小波变换的由幺正门组成的量子线路图;
[0055]
图8是本发明实施例提供的图7中电路的幺正门组可以被组合以形成如公 式(9)
和(8)所示的解纠缠器u和等距v图;
[0056]
图9是本发明实施例提供的|0>+x
2i
|1>和|0>+x
2i+1
|1>位于一次尺度函数运算的 前后两位示意图;
[0057]
图10是本发明实施例提供的四个相邻数据通过一个粗粒化单元进行粗粒化 的过程展示图;
[0058]
图11是本发明实施例提供的用“zigzag”展平方法将医学二维灰度图像展 开成向量的示意图;
[0059]
图12是本发明实施例提供的一种结合小波变换和张量网络的医学图像分类 方法的流程图;
[0060]
图13是本发明实施例提供的张量分类网络(mps)的结构图;
[0061]
图14是本发明实施例提供的肺部cxr图像在经过4层waveletmera图的 前后对比图;
[0062]
图15是本发明实施例提供的waveletmera在covid-19测试集上的混淆矩 阵示意图;
[0063]
图16是本发明实施例提供的对covid-19数据集进行预处理的过程展示图;
[0064]
图17是本发明实施例提供的waveletmera在covid-19-mask测试集上的混 淆矩阵示意图;
[0065]
图18是本发明实施例提供的waveletmera在lidc测试集上的混淆矩阵 图示意图。
具体实施方式
[0066]
下面结合附图具体阐明本发明的实施方式,实施例的给出仅仅是为了说明 目的,并不能理解为对本发明的限定,包括附图仅供参考和说明使用,不构成对 本发明专利保护范围的限制,因为在不脱离本发明精神和范围基础上,可以对本 发明进行许多改变。
[0067]
作为量子多体物理和量子信息科学领域中强大的数值工具,张量网络 (tensor networks,tns)被用于结合量子物理和机器学习的研究中,近年来取得 了蓬勃的发展。tns和nns都是由简单的单元(张量或神经元)构成以实现复 杂的功能。作为矩阵的扩展,张量能够表示现实世界中的文本、图像、音频、视 频等高维数据特征。张量和张量运算的图形符号如图1所示,(a):标量s、向量 vi、矩阵m
ij
、三阶张量t
ijk
的图形符号表示;(b):矩阵乘或张量收缩的图形符号 表示;(c):两个矩阵乘积的迹的图形符号表示。
[0068]
tns是一种基于张量的数据分析方法,它能够解决张量在其阶数上升时所 面临的“维度灾难”问题。然而,与nns不同的是,tns在高维空间中做线性 运算,这使得它们更容易进行理论分析,并促进了更具可解释性的算法的开发。 这里强调tns的可解释性,因为它们自然地结合了基于统计物理和量子场论的 量子概率解释,并且tns上的操作是透明和具体的。在医疗行业智能化的发展 过程中,tns已经展现了令人惊讶的效果。
[0069]
发展张量网络的一个关键动机是粗粒化的思想,在物理学中被称为重整化 群,具有粗粒化思想的代表性张量网络如树张量网络(tree tensor network,ttn)、 多尺度纠缠重整化拟设(multi-scale entanglement renormalization ansatz,mera) 分别见于图4(c)、4(d)。令人惊讶的是,cnns拥有物理学的“基因”,其卷积操 作蕴含着粗粒化的思想,并且cnns在结构上与mera张量网络非常相似,如 图2所示,图2上部分是在肺部图像上执行卷
积运算的过程,下部分是mera 的粗粒化过程,原始数据需要经过特征映射之后再输入张量网络。因此,本例开 发了一种基于mera的轻量级方法,它不仅受益于tns的可解释性,也弥补了 cnns模型过于复杂所带来的缺点。
[0070]
小波和小波变换是近几十年来信号和图像处理领域最重要的发展之一。d4 小波具有四个尺度函数系数h和四个小波函数系数g如下所示:
[0071][0072]
尺度函数与小波函数由函数系数(h和g)与四个输入数据的内积给出,尺度 函数如公式(2)所示,小波函数如公式(3)所示:
[0073]
s(x)=h0x
2i
+h1x
2i+1
+h2x
2i+2
+h3x
2i+3
,
ꢀꢀ
(2)
[0074]
w(x)=g0x
2i
+g1x
2i+1
+g2x
2i+2
+g3x
2i+3
,
ꢀꢀ
(3)
[0075]
其中i∈{i|1≤i<(n/2),i∈z},这里n表示输入数据的总个数。在进行小波变 换时,尺度函数和小波函数的值是迭代计算的。每次迭代,上式中的i都会增加 1。尺度函数能够捕捉数据的分布特征,并使用一般的数据量模拟出原始数据的 分布,小波函数能够捕捉数据之间的差异,如图3所示。d4小波存在一个边缘 问题:当i=(n/2)-1时,小波变换应该作用于输入数据x
n-2
、x
n-1
、xn、x
n+1
,但 xn和x
n+1
并不存在。该边缘问题有两种解决办法:(1)将原始数据视为周期性的, 即首尾相连的,紧跟在x
n-1
之后的数据就变为了x0和x1;(2)将原始数据的首尾两 端都看作是镜像的,这样输入数据就变为了x
n-2
、x
n-1
、x
n-1
、x
n-2
。
[0076]
tns能够解决使用经典计算机模拟量子多体系统时遇到的“维度灾难”问 题。一个n位量子多体态可以被表示为
[0077][0078]
其对应的希尔伯特空间(hilbert space)维数为dn。如图4(a)所示,量子态的系数可以表示为一个n阶的张量,其每一阶的维数为d,则该系数张量 的参数数量随着n的增加呈指数上升。当n足够大时,该张量已不能够被经典 计算机处理。
[0079]
因此,一些tns,例如矩阵乘积态(matrix product state,mps),被用来近 似高阶张量。mps是一种张量分解方法,它可以使用一个3阶张量链来逼近任 意高阶张量,如图4(b)。n阶系数张量的mps形式可以表示为:
[0080][0081]
其中表示构成mps的各个三阶张量,in是各张量的物理指标,αn被称 为虚拟指标,连接mps当中的各个张量。指标αn的维度大小为χ,它决定了mps 的近似表示能力,张量的参数量由指数级别的dn减少到多项式级别的 n
·d·
χ2。当χ=d
n2
时,mps的近似是精确的,可以表示任意张量。mps捕捉数 据之间相关性的能力随两数据之间距离的增长
呈指数衰减,如图4所示:(a)的张量图像表示;(b)矩阵乘积态(matrixproductstate,mps);(c)树张量网络(treetensornetwork,ttn);(d)多尺度纠缠重整化拟设(multi-scaleentanglementansatz,mera)。
[0082]
mera也是张量网络的一种,与mps一样可以近似地表示一个高阶张量,见图4(d),被设计用于在一个强大的数值算法中实现实空间重整化群思想。与mps相比,mera能够捕捉相距较远的数据之间的相关性,如图6所示,即mera捕捉数据之间相关性的能力随两数据之间距离的增长呈幂律衰减。
[0083]
mera有两种类型的张量:解纠缠器和等距,分别如图5(a)和图5(b)所示。对于标准的二元mera来说,这两种张量都需要满足特定的限制,解纠缠器必须是幺正的:等距需要满足:解纠缠器保留输入同一解纠缠器的两数据之间的纠缠,并解除输入到不同解纠缠器的数据之间的纠缠;再由等距层对解纠缠层的输出进行粗粒化。解纠缠器和等距的特性使得mera能够在同一层捕捉同一尺度上的所有纠缠。
[0084]
与类似mps这样的一维单层张量相比,分层结构的张量网络可以更好地表示线性层之间的相关性。ttn也是一种分层张量网络,由一些等距张量构成如图4(c)。由于等距的特性,ttn也能够完成对原始数据的粗粒化或重整化,每层ttn能够减少原数据一半的数据量。但是与mera相比,ttn存在明显的劣势,比如位于图4(c)中i4、i5的相邻数据在ttn的最顶端张量才会相遇。这就需要最顶层张量捕获部分相邻数据之间的短程纠缠,而就限制了其捕捉长程纠缠的能力,而mera的解纠缠层能够弥补ttn这一不足。
[0085]
重整化群的思想影响了小波变换的发展,并且小波已经被证明是重整化群应用的有用工具。mera与小波变换都与重整化群具有密切的联系,可以使用由一些幺正门组成的量子线路实现小波变换,如图7所示,每一层电路都有两个子层,分别由幺正门u(θ1)和u(θ2)构成。当每个幺正门u(θ2)左上方的指标腿与|1>态收缩且θ1=-π/6、θ2=π/12时,灰色阴影区域中的电路部分可以实现d4小波变换的尺度函数。
[0086]
图7所示电路当中的幺正门定义如下:
[0087][0088]
图7中的灰色阴影区域用公式表示如下:
[0089][0090]
原幺正门中的(sinθ2cosθ2)两项被保留下来。同理,当与|0>态收缩时,图7中的灰色阴影区域实现d4小波变换的小波函数。每层电路一半的输出对应于尺度函数的结果,继续向上传递作为下一层电路的输入。
[0091]
在这些理论基础上,本发明实施例提供了一种结合小波变换和张量网络的医学图像分类方法,参考图12,具体包括步骤:
[0092]
s1、将具有n个像素的医学二维灰度图像展平为长度为n的一维向量v(x);
[0093]
s2、将一维向量v(x)中的每一个元素xi特征映射为希尔伯特空间当中的一个量
子态,得到n个量子态;
[0094]
s3、通过结合了小波变换和张量网络的粗粒化网络对n个量子态进行l次粗 粒化处理,每次输出一个仅含有单个|1>态的项,从而得到l个仅含有单个|1>态的 项作为粗粒化输出;
[0095]
s4、将该粗粒化输出特征映射为多个特征值并通过张量积连接起来输入训 练完成的张量分类网络中,得到预测的分类结果。
[0096]
步骤s3中的粗粒化网络结合了d4小波变换和mera,本例称之为 waveletmera,其结构如图8(b)所示,其中浅灰色的指标表示每层waveletmera 的第一个输出位。waveletmera基于图8(a)右边所示的粗粒化单元构建,该粗 粒化单元由8(a)左边所示的d4小波变换中的幺正门组变换而来。具体的,粗粒 化单元包括两个解纠缠器和一个等距;该两个解纠缠器用于输入通过张量积连 接的步骤s2所得n个量子态中的四个相邻量子态,通过解纠缠各自得到一个仅 含有单个|1>态的项;该等距用于对该两个解纠缠器输出的两个仅含有单个|1>态 的项进行粗粒化操作,得到对应的一个仅含有单个|1>态的项。
[0097]
所述粗粒化网络由m层网络结构组成,图8(b)为m=2层的示例。每层网络 结构包含2个以上解纠缠器和1个以上等距,每个解纠缠器具有两个输入指标 和两个输出指标,每个等距具有两个输入指标和一个输出指标;每层网络结构的 最后一个解纠缠器与第一个解纠缠器通过一个附加的等距相连接。
[0098]
在非顶层的网络结构中,一个等距的两个输入指标各连接相邻两个解纠缠 器的一个输出指标,一个解纠缠器的两个输出指标各连接相邻两个等距的一个 输入指标,同一层中各个等距的输出指标连接下一层网络结构中解纠缠器的输 入指标。在最底层的网络结构中,每相邻两个解纠缠器的四个输入指标用于输入 通过张量积连接的步骤s2所得n个量子态中的每四个相邻量子态。
[0099]
每个解纠缠器用于保留输入的张量积连接下的两个量子态的纠缠,并解除 这两个量子态与输入其他解纠缠器量子态之间的纠缠,每个解纠缠器分别从两 个输出指标输出仅含有单个|1>态的第一项和第二项,其中第一项、第二项分别 为该两个量子态在尺度函数运算中位于后两位和前两位输入时得到的结果;
[0100]
每个等距用于对输入的张量积连接下的两个仅含有单个|1>态的项进行粗粒 化操作,得出输入到与其相连的两个解纠缠器中的4个相邻量子态经过d4小波 变换后的结果。
[0101]
容易看出,输入数据在经过m层waveletmera后,长度由n减小到n/2m=l。
[0102]
在本例中,waveletmera当中的解纠缠器u和等距v可以被定义为:
[0103][0104][0105]
其中θu=-π/6,θv=π/12。
[0106]
在步骤s2中,一维向量v(x)中的第i个元素xi(图像中的第i个像素点)被 映射为希尔伯特空间当中的一个量子态|φ(xi)〉:
[0107]
|φ(xi)>=|0>+xi|1>,
ꢀꢀ
(10)
[0108]
其中的狄拉克符号“|>”表示一个向量,|0>表示向量(10)
t
,|1>表示向量 (0 1)
t
。完成特征映射后的相邻输入由张量积连接。d4小波每次作用于四个相 邻数据,参考图10,对于任意四个相邻量子态组成的张量积 由相邻的第一解纠缠器(位于图10左边)、 第二解纠缠器(位于图10右边)以及第一解纠缠器、第二解纠缠器均连接的第 一等距进行粗粒化的过程包括步骤:
[0109]
s31、第一解纠缠器对张量积进行解纠缠,输出只含有单个 |1>态的第二项至第一等距中;第二解纠缠器对张量积进行解纠 缠,输出只含有单个|1>态的第一项至第一等距中;
[0110]
s32、第一等距对输入的两个只含有单个|1>态的项进行张量积操作,得到只 含有单个|1>态的项输入该第一等距连接的下一层网络结构中的一解纠缠器中。
[0111]
更具体的,第一解纠缠器根据自身的定义对张量积进行收缩, 表示为
[0112][0113]
当输入向量当中存在含有多个|1>态的项时,waveletmera就不再编码d4 小波变换,因此,去除全|0>态的项和含有多个|1>态的项,仅保留含有单个|1》态 的项。公式(11)可以被继续推导为:
[0114][0115]
很明显可以看出,公式(12)得到的结果是一个纠缠态,所以这时需要考虑到 两种情况,如图9所示。对于四个相邻输入数据|φ(x
2i
)》、|φ(x
2i+1
)>、|φ(x
2i+2
)>、|φ(x
2i+3
)〉, 当i=0时,|φ(x2)〉和|φ(x3)〉在一次尺度函数运算当中位于后两位;当i=1时,|φ(x2)〉 和|φ(x3)〉位于前两位。所以公式(12)的结果包含了相邻输入|φ(x
2i
)〉和|φ(x
2i+1
)>在 两次尺度函数运算中得到的结果。是|φ(x
2i
)>和|φ(x
2i+1
) 在尺度函数运算中位于后两位输入时得到的结果(如图9(a)所示), 是|φ(x
2i
)>和|φ(x
2i+1
)>位于前两位输入时得到的结果(如 图9(b)所示)。
[0116]
第一解纠缠器的解纠缠过程用公式总结为:
[0117][0118]
其中,(x
2i+1
sinθu+x
2i cosθu)|1>、(x
2i+1
cosθ
u-x
2i sinθu)|1>分别为第一解纠缠器输出 的仅含有单个|1>态的第一项和第二项;
[0119]
|φ(x
2i+2
)>和|φ(x
2i+3
)>同理,第二解纠缠器输出的仅含有单个|1>态的第一项和第 二项分别为(x
2i+3
sinθu+x
2i+2
cosθu)|1>、(x
2i+3
cosθ
u-x
2i+2
sinθu)|1>。
[0120]
则第一等距根据自身的定义对第一解纠缠器输出的第二项和第二解纠缠器 输出的第一项进行张量积得到只含有单个|1>态的项,用公式表示为:
[0121][0122]
其中,作用到原始输入数据(x
2i x
2i+1 x
2i+2 x
2i+3
)上的系数为:
[0123][0124]
因此,公式(13)中|1>态的系数与原始数据经过公式(2)所示的d4小波变换尺 度函数得到的数值结果相等。
[0125]
在清楚如何使用waveletmera实现d4小波变换之后,则可以根据任务来 调整waveletmera的层数,以达到分类精度和参数量的最佳平衡。
[0126]
需要说明,本例步骤s1采用“zigzag”展平方法,使空间中的相邻像素尽 可能相互靠近,如图11所示,圆点表示展平化的起点,箭头表示终点。
[0127]
步骤s3的目的是对原始输入数据进行粗粒化,用于输入训练完成的张量分 类网络中,得到预测的分类结果(步骤s4)。具体的,步骤s4包括步骤:
[0128]
s41、保留步骤s3所得粗粒化输出中所有|1>态的项的系数,并使用离差标 准化方法将这l个系数值归一化到区间[0,1]当中,得到l个归一化值;
[0129]
s42、对l个归一化值进行特征映射:
[0130]
s43、通过张量积将步骤s42得到的l个特征值连接起来,得到该医学二维 灰度图像对应的全局特征映射;
[0131]
s44、将该全局特征映射输入训练完成的张量分类网络中,预测得到该医学 二维灰度图像的分类结果。
[0132]
图像中每个像素的特征映射过程为张量网络提供了非线性扩充,类似于机 器学习中的激活函数,从而使张量网络模型能够解决复杂的问题,步骤s42选 择的是正弦局部特征映射:
[0133][0134]
s=1,...,d,当d=2时,得到:
[0135][0136]
其中,x指代l个归一化值中的任一个,φ(x)表示对x映射后得到的特征值。
[0137]
对步骤s41得到的值进行公式(16)所示的特征映射,并通过张量积将它们连 接起来,可以得到:
[0138][0139]
需要说明的是,在训练过程中,对数据集中各个样本的处理过程与步骤 s1~s43一致,而步骤s1~s4整体由图12所示的网络模型实现。但在将该模型 投入应用前,需要训练张量分类网络,以固定其参数。
[0140]
在本例中,张量分类网络采用矩阵乘积态mps,如图13所示,除了中心张 量的物理指标作为网络的输出指标外,每个输入向量φ(xn)的指标腿与mps中每 个3阶张量的物理指标腿相连,表示即将被收缩。本例使用的mps,它首先在 输入数据和mps之间进行水平方向上的收缩,然后在权重张量之间进行垂直方 向上的收缩,其可以表示为一个线性决策函数:
[0141][0142]
其中,fj(x)表示张量分类网络对第j个样本的预测结果,φ(x)j表示数据集 中第j个样本的全局特征映射(求取过程与步骤s1~s43一致),w表示权重矩 阵,由l个权重张量组成,n=0,1,2,...,l,经数据集训练后,w固定不变。
[0143]
在训练张量分类网络的过程中,使用交叉熵损失函数来计算张量分类网络 的预测结果和真实标签之间的距离,并使用反向传播算法来更新张量分类网络 中的权重张量;交叉熵损失函数表示为:
[0144][0145]
其中,yj表示第j个样本的标签,正类为1,负类为0;pj表示第j个样本被 预测为正类的概率。
[0146]
本例使用mnist数据集、covid-19数据集和lidc数据集来验证本例所提 出方法的分类能力,并将其与其他tns(包括mps和ttn)、经典nns和一些 最先进的模型进行了对比实验。首先,将waveletmera的分类精度和参数数量 与mnist数据集中的其他四个模型进行比较。然后,在其他三个医学图像数据 集中,本例比较了参数量、准确率(accuracy)、灵敏度(sensitivity)、特异度 (specificity)、平衡准确度(balanced accuracy,ba)和单次迭代的大致时间,并 在每个数据集上绘制了waveletmera的混淆矩阵,由四个指标组成:真阳性 (true positive,tp)、假阳性(false positive,fp)、假阴性(false negative,fn)和真 阴性(true negative,tn),以协助评估waveletmera模型的分类能力。准确率 是模型正确分类的样本数与样本总数的比值(见公式(20))。特异度定义为样本 中实际阴性数与预测阴性结果数的比值(见公式(21))。灵敏度是对预测为阳性 的实际阳性病例比例的度量(见公式(22))。ba可以帮助确定数据集中正负样本 的比例是否平衡(见公式(23))。
[0147]
[0148][0149][0150][0151]
为了使实验结果更具有对比性,实验中使用的所有tns都将虚拟指标的维 度设置为χ=6。所有实验均在inter(r)core(tm)i7-10700 cpu@2.90ghz上 进行,并由python模拟。
[0152]
表1.在mnist数据集上的对比试验结果
[0153][0154]
mnist数据集被广泛应用于验证机器学习模型的基础分类能力,包含大量 尺寸为28
×
28的手写数字灰度图片。目前有方法提出了一种将经典神经网络与张 量网络相结合的可训练网络,称为hybrid tensor network(htn),并对比了几 种tns与经典nns在mnist数据集上的分类精度以及参数量,本例再加入本 文提出的waveletmera张量网络,如表1所示。
[0155]
由于mnist数据样本原尺寸就不大,因此本例对其只进行了一层粗粒化操 作。waveletmera在mnist数据集上的参数量为2.9
×
104,在测试集上的分类精 度能够达到96%。与没有使用waveletmera的mps相比,在参数量减半的情 况下,精度没有变化。无论是目前较为成功的张量网络ttn、htn,还是成熟 的神经网络fcn,参数量都远高于waveletmera,且精度相差无几。
[0156]
covid-19肺炎新出现不久,现有的公共网络资源中还没有合适和可用的数 据集。在这样的背景下,来自多哈卡塔尔大学和孟加拉国达卡大学的一个研究小 组,以及来自巴基斯坦和马来西亚的合作者,与医生合作,创建了这个关于 covid-19阳性病例以及健康和病毒性肺炎图像的cxr图像数据库。本例在上述 数据库中选取部分covid-19阳性病例与健康图像构成了一个平衡子集以训练 waveletmera和其他用于对比实验的模型。具体来说,该子集包含5112张肺部 cxr图像,其中2597张为健康图像,2515张为covid-19阳性病例图像。并且, 还另外选取了1091张健康图像与1101张covid-19阳性病例图像作为测试集, 共2192张。训练集与测试集中正负样本比例都接近于1:1,尺寸为128
×
128,并 且没有图片重复存在。
[0157]
首先,本例以waveletmera中mera的层数为变量(即小波变换的次数), 以参数量与测试集上的分类准确率为两个衡量指标,使用covid-19数据集进行 了对比实验,结果如表2所示。结果表明,对于尺寸为128
×
128的covid-19数据 集来说,当层数为4时,参数量的减少与准确率的下降能够达到一个平衡。平均 每一张肺部cxr图像经过4层waveletmera需要1秒钟。图14展示了4层 waveletmera变换前后肺部的cxr图像。
[0158]
表2.在covid-19数据集上,不同的waveletmera层数能够达到的参数量和准确率
[0159][0160]
除waveletmera之外,本例还实验了6种网络结构,其中包括使用控制变 量法以进行对照试验的网络结构,如:mps,db2+mps,mlp,db2+mlp,以及 目前通过肺部cxr图像就能够分类covid-19阳性病例的最先进的模型,如: patch-gtnc和fused-densenet-tiny。实验中使用的mps模型与waveletmera 当中充当可训练网络(全连接层)的mps是一样的,目的是验证waveletmera 当中粗粒化过程的有效性。db2+mps是将waveletmera替换为pywavelets函数 库中的db2小波变换函数,以进行waveletmera与普通小波变换的对比。 db2+mlp则是作为普通小波+经典神经网络的对照组。pywavelets函数库里面的 db2小波变换函数与d4小波具有相同的尺度函数与小波函数,采用镜像方法处 理边缘问题。fused-densenet-tiny目前在通过cxr图像对新冠肺炎分类的任务 上表现很好,模型精度高,参数少,但模型非常抽象且不可见。表3展示了对比 试验的结果,其中waveletmera每次迭代的时间仅包含训练阶段,图15给出 了waveletmera在covid-19测试集上的混淆矩阵。
[0161]
表3.covid-19数据集上的对比实验结果
[0162][0163]
与mps相比,4层waveletmera不仅减少了一百多万参数量,并且各项指 标都有大幅度的提升,证明waveletmera的粗粒化能够提取出原图片中更具价 值的信息;db2+mps由于处理边缘问题的方式不同,所以参数量稍大于 waveletmera,但分类效果明显差于waveletmera,由此证明waveletmera提 取特征的能力强于普通小波。patch-gtnc使用“patches”保留原图片的全局结 构信息,是目前在根据x-ray图像分类covid-19阳性病例任务中表现较好的张 量网络模型,但无论是参数量还是分类表现都不如waveletmera。mlp和 db2+mlp作为对照的经典方法在参数量上少于mps与waveletmera,但各项 指标都逊色于张量网络方法。轻量级的深度神经网络fused-densenet-tiny在各 项指标上跟
waveletmera模型的有效性。lidc数据集是一个包含临床胸部ct扫描并标注 病变区域的数据集。数据集中所有肺结节大小都在3mm-33mm,本例按照医生 对各图像标注的恶性程度,将lidc数据集分为良性与恶性两类,其中由2031 张恶性图像和1928张良性图像构成训练集,840张恶性图像和858张良性图像 构成测试集,都是64
×
64的灰度图像,且正负样本比例接近1:1。在实验中,本例 将waveletmera的层数设置为2,平均每一张图片的粗粒化处理时间为0.2秒 钟,能够得到参数量与准确率的最优平衡。对照试验中db2小波函数的变换次 数同样设定为2次。在表5中本例给出了waveletmera与其他6种模型的对比 实验结果,waveletmera每次迭代的时间仅包含训练阶段。其中lotenet*模型 是在lotenet模型的基础之上加入了卷积操作与全连接层。waveletmera在 lidc测试集上的混淆矩阵如图18所示。
[0170]
表5.lidc数据集上的对比实验结果
[0171][0172]
相比于covid-19数据集,lidc数据集的分类难度较高,waveletmera仍 然能够保持其参数量少且准确率高的优势,减少了20多万的参数量,并且在测 试集上的准确率达到98.47%,反观另外6种模型的准确率都低于80%。
[0173]
综上,本发明实施例提供的一种结合小波变换和张量网络的医学图像分类 方法,提出一种在医学图像上表现优异的粗粒化网络,该粗粒化网络结合了小波 变换和mera,即将d4小波编码到mera中,形成一个内部参数固定的模型, 本发明将其命名为waveletmera。本发明还构建一个如全连接层般的可训练张 量网络(即张量分类网络)。本发明使用mnist数据集、covid-19数据集和lidc 数据集进行多维验证,结果表明waveletmera的准确率稳定居高,比cnns的 深度神经网络具有更好的粗粒化能力,这种能力使waveletmera能够在保证精 度的同时,更大程度上减少模型的参数量。结果表明waveletmera不仅在分类 上优于当前主流的深度神经网络,而且在数据预处理方面也优于普通小波变换。 不仅如此,waveletmera还具有张量网络本身的可解释性优势,能够为医生提 供更有针对性、更高效的诊断协助,缓解医疗紧张和医患冲突问题。
[0174]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实 施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、 替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1