一种提高深度文本匹配模型适应性的小样本学习方法
1.本发明涉及一种小样本学习方法,具体涉及一种提高深度文本匹配模型适应性的小样本学习方法,属于自然语言处理中的文本匹配技术领域。
背景技术:
2.文本匹配,旨在识别两个文本片段之间的关系,一直以来都是自然语言处理和信息检索中的一个关键研究问题。许多具体的任务都可被视为特定形式的文本匹配,例如问答系统、自然语言推理以及同义识别等。
3.随着深度学习的快速发展,近年来,许多神经网络模型被应用于文本匹配领域。由于其强大的学习文本表示的能力与建模文本对之间交互的能力,深度文本匹配方法在各项基准任务上都取得了令人印象深刻的表现。然而,一些工作表明,基于深度学习的方法通常需要大量标签数据进行训练,即,对有标签数据的规模有很强的依赖性。当可用的标签数据有限时,往往会导致模型的性能不佳,阻碍了深度文本匹配模型的泛化性和适应性。因此,如何有效地解决该问题,是进一步提升深度学习实际应用能力的关键。
4.对于小样本学习文本匹配的场景,目前,经典的解决方案是投入大量资源,以获取或标注相关的训练数据,从而使可用的有标签数据规模足以达到常规深度学习模型训练的需要。例如,产品搜索系统的语义匹配功能需要处理一些生活常识文本与产品信息文本之间的匹配,如果这方面的有标签数据不是很充足的话,产品方就要耗费大量的人力与时间成本进行数据的收集与标记。相比来讲,另外一种被认为更加有效的方案是,借助其它相似的数据集进行模型训练,同时提高模型在不同领域数据上的适应性,从而解决当前数据集上的小样本学习问题。因此,小样本学习问题,可以结合模型的适应性方法来进行解决。
5.与训练数据的领域不同的数据,被称为域外数据。在实际应用中,经常会有深度文本匹配模型预测域外数据的情况,此时模型的性能会有所降低,所以,需要模型适应性的方法来减轻模型在域外数据上的性能损失。目前,现有的模型适应性技术,大都基于“目标领域与源领域在数据规模上是相当的”的前提。然而,这种前提条件在许多情况下是不切实际的,因为在实际应用中,很难为所有域外数据都收集一个相应的大规模有标签数据集。因此,如何解决深度文本匹配模型的小样本学习与模型适应性问题,显得至关重要。
技术实现要素:
6.本发明针对现有技术存在的缺陷,面向如何提高小样本学习深度文本匹配模型的跨领域适应性这一问题,创新性地提出一种提高深度文本匹配模型适应性的小样本学习方法。
7.本方法的创新点在于:综合了应用于文本匹配模型的小样本学习与跨领域适应性方法,沿最小化目标域小样本数据集损失的方向,对源域数据的权重进行梯度下降。
8.本发明采用以下技术方案实现。
9.一种提高深度文本匹配模型适应性的小样本学习方法,包括以下步骤:
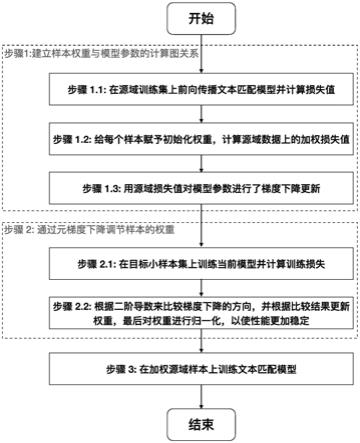
10.步骤1:建立样本权重与模型参数的计算图关系。
11.具体地,步骤1包括以下步骤:
12.步骤1.1:在一批次源域训练集数据上前向传播文本匹配模型,并计算相应的损失值:
13.costs(yi,li)=ces(yi,li)
ꢀꢀꢀ
(1)
14.其中,costs表示模型在源域上的损失值;ces代表交叉熵损失函数;li表示第i个样本的标签值;yi是模型对第i个样本的预测值:
15.yi=tmms(ai,bi,θ)
ꢀꢀꢀ
(2)
16.其中,tmms表示在源域的任务或数据集上训练的文本匹配模型;ai、bi分别表示输入到模型进行文本匹配的两条句子;θ表示深度文本匹配模型的参数。
17.步骤1.2:为损失值对应的每个样本,赋予一个初始化权重。考虑到源域和目标域之间的数据分布差异较大,本发明将样本权重初始值设为0。然后,计算源域数据上的加权损失值之和,作为源域损失值:
[0018][0019]
其中,losss表示源域损失值,y表示模型对源域样本的预测值,l表示源域样本的标签值;为源域中第i个样本的权重值,其初始化为0,i∈{1,2,
…
,n}。
[0020]
步骤1.3:为将样本权重与源域损失值之间的计算图连接,用源域损失值losss对模型参数θ进行梯度下降更新:
[0021][0022]
其中,表示在源域样本上更新一步后的模型参数;α表示学习率;表示源域损失值对模型参数的偏导数;ws表示源域样本的权重。为偏导数的运算符。
[0023]
从而使样本权重与模型参数之间建立起计算图关系。至此,在不改变模型参数值的情况下,建立了计算图连接。
[0024]
步骤2:通过元梯度下降调节样本的权重。
[0025]
具体地,步骤2包括以下步骤:
[0026]
步骤2.1:为了比较源域分布与目标域分布上模型梯度下降方向的异同,在目标小样本集上训练当前模型,并计算训练损失:
[0027][0028]
其中,loss
t
表示目标域损失值;tmm
t
表示在目标域上训练时的深度文本匹配模型;m表示目标域样本的数目。
[0029]
目标域样本的权重设置为常数1。这是因为与源域样本相比,目标域样本数据之间的分布没有差异。
[0030]
步骤2.2:由于loss
t
(y,l)形式化为当根据目标域损失值loss
t
(y,l)计算对于源域样本权重ws的二阶导数时,梯度自然能够流过因此,梯度携带的比较信
息在源域样本的权重梯度上累积。源域样本的权重调节过程如下:
[0031][0032]
其中,表示更新后的源域样本权重,α表示学习率,表示模型在目标域小样本集上损失值对源域样本权重的二阶偏导数。
[0033]
步骤2.3:受模型无关元学习算法的启发,采用二阶导数来比较梯度下降的方向,并根据比较结果更新权重。
[0034]
元权重调节首先消除调整后的权重的负值,然后对它们进行批量归一化,以使性能更加稳定:
[0035][0036][0037]
其中,表示当前要进行归一化处理的源域样本权重,表示批次数据内其它源域样本的权重,m是目标域训练集的数据批次大小,k表示源域批次数据中第k个样本的序号。
[0038]
步骤3:在加权源域样本上,训练文本匹配模型。
[0039]
具体地,通过元权重调节将计算得到的样本权重分配给源域样本,以便在源域样本上训练文本匹配模型后获得加权损失:
[0040][0041]
其中,losss表示模型在源域样本上的最终加权损失值,i∈{1,2,...,n}。
[0042]
由此,使在源域数据中与目标域数据更相似的数据能够获得更大的权重分配,促进它们在更大程度上决定基础模型参数更新的走势,最终提高了基础模型在问答匹配数据上的表现。
[0043]
有益效果
[0044]
本发明,与现有技术相比,具有如下优点:
[0045]
本发明采用元权重调节方式,解决了传统的跨领域文本匹配方法在小样本学习设置下表现不足的问题,增强了文本匹配模型在少样本学习环境中的适应性。本方法与基础模型无关,可应用于各种基于深度学习的文本匹配模型。
[0046]
通过在一系列文本匹配数据集上进行全面的比较实验,以检验本方法在小样本学习设置上对于不同数据集与任务适应性提升的效果。实验结果表明,本方法明显优于现有方法,有效提高了深度文本匹配模型对少样本目标任务或数据集的适应性。
附图说明
[0047]
图1是本发明方法的流程图。
具体实施方式
[0048]
下面结合附图对本发明方法做进一步详细说明。
[0049]
实施例
[0050]
一种提高深度文本匹配模型适应性的小样本学习方法,如图1所示,包括以下步骤:
[0051]
步骤1:建立自然语言推理源域数据样本权重与bert模型参数的计算图关系。
[0052]
具体地,步骤1包括以下步骤:
[0053]
步骤1.1:以自然语言推理训练集作为源域,利用文本匹配模型bert在源域的一个批次数据上进行前向传播,以计算相应的源域损失值:
[0054]
costs(yi,li)=ces(yi,li)
[0055]
其中,costs表示模型在源域上的损失值;ces代表交叉熵损失函数;li表示第i个样本的标签值;yi是模型对第i个样本的预测值:
[0056]
yi=berts(ai,bi,θ)
[0057]
其中,berts表示在自然语言推理源域任务上训练的文本匹配模型bert;ai、bi分别表示输入到模型进行文本匹配的两条句子;θ表示深度文本匹配模型的参数。
[0058]
步骤1.2:为损失值对应的每个样本,赋予一个初始化权重。考虑到源域和目标域之间的数据分布差异较大,本发明将样本权重初始值设为0。然后,计算源域数据上的加权损失值之和,作为源域损失值:
[0059][0060]
其中,losss表示源域损失值,y表示模型对源域样本的预测值,l表示源域样本的标签值;为源域中第i个样本的权重值,初始化为0,i∈{1,2,
…
,n}。
[0061]
步骤1.3:为将样本权重与源域损失值之间的计算图连接,用源域损失值losss对模型参数θ进行梯度下降更新:
[0062][0063]
其中,表示在源域样本上更新一步后的模型参数;α表示学习率;表示源域损失值对模型参数的偏导数;ws表示源域样本的权重。
[0064]
从而使自然语言推理句子对权重与模型参数之间建立起计算图关系。至此,在不改变bert模型参数值的情况下,建立了计算图连接。
[0065]
步骤2:通过元梯度下降调节样本的权重。
[0066]
步骤2.1:为了比较自然语言推理的分布与问答匹配的分布上bert模型梯度下降方向的异同,在问答匹配小样本集上训练当前bert模型并计算训练损失:
[0067]
[0068]
其中,loss
t
表示目标域损失值;bert
t
表示在目标域上训练时的深度文本匹配模型bert;m表示目标域样本的数目。
[0069]
目标域样本的权重设置为常数1。这是因为与源域样本相比,目标域样本数据之间的分布没有差异。
[0070]
步骤2.2:由于loss
t
(y,l)形式化为当根据目标域损失值loss
t
(y,l)计算对于源域样本权重ws的二阶导数时,梯度自然能够流过因此,梯度携带的比较信息在源域样本的权重梯度上累积。源域样本的权重调节过程如下:
[0071][0072]
其中,表示更新后的源域样本权重,α表示学习率,表示模型在目标域小样本集上损失值对源域样本权重的二阶偏导数。
[0073]
步骤2.3:受模型无关元学习maml算法的启发,采用二阶导数来比较梯度下降的方向,并根据比较结果更新权重。
[0074]
元权重调节首先消除调整后的权重的负值,然后对它们进行批量归一化,以使性能更加稳定:
[0075][0076][0077]
其中,表示当前需要进行归一化处理的源域样本权重,表示批次数据内其它源域样本的权重,m是目标域训练集的数据批次大小,k表示源域批次数据中第k个样本的序号。
[0078]
步骤3:在加权源域样本上,训练文本匹配bert模型。
[0079]
具体地,通过元权重调节将计算得到的样本权重分配给源域样本,以便在源域样本上训练文本匹配bert模型后获得加权损失:
[0080][0081]
其中,losss表示模型在源域样本上的最终加权损失值,i∈{1,2,...,n}。由此使得在自然语言推理数据中,与问答匹配数据更相似的数据获得更大的权重分配,从而更大程度上决定bert模型参数更新的走势,最终提高bert模型在问答匹配数据上的表现。
[0082]
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1