基于PSO-CNN-LSTM的水库水位预测预警方法与流程
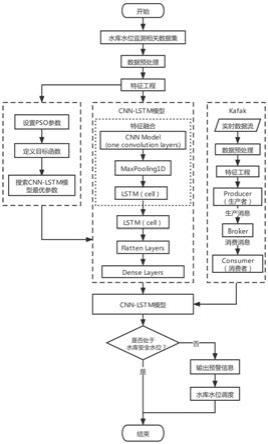
基于pso-cnn-lstm的水库水位预测预警方法
技术领域
1.本发明涉及大坝水位预测预警领域,具体涉及一种基于pso-cnn-lstm的水库水位预测预警方法。
背景技术:
2.水库做为重要的水利工程枢纽,发挥着巨大的工程效益,承载着人民日常生活及工农业生产的艰巨任务。水库不仅为防汛抗洪调度、确保一方平安做出了巨大贡献,而且兼顾着灌溉、发电、人蓄饮水的重任,稍有不慎则会给国家及人民带来难以预料的灾难,水库健康监测就尤为重要。
3.水库水位监测是水库健康监测项目中最为重要的监测目标之一。水库水位直接影响着水库的健康状况,需实时对水库水位进行监测调度,以控制在一个安全区间,保证水库安全。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种基于pso-cnn-lstm的水库水位预测预警方法,实现快速有效的水库水位预测,为水库调控提供可靠数据。
5.为实现上述目的,本发明采用如下技术方案:
6.一种基于pso-cnn-lstm的水库水位预测预警方法,包括以下步骤:
7.步骤s1:获取水库历史监测数据,并预处理;
8.步骤s2:将预处理后的水库历史监测数据按采集时间进行排序,构建特征数据集;
9.步骤s3:基于pso搜索cnn-lstm模型最优参数;
10.步骤s4:对特征数据集进行处理,并划分为训练集和测试集;
11.步骤s5:基于步骤s3得到的最优参数和训练集,构建并训练cnn-lstm模型;
12.步骤s6:基于训练后的cnn-lstm模型,进行水库水位实时预测。
13.进一步的,所述步骤s1具体为:
14.步骤s11:获取水库历史监测数据包括水库的水位、泄洪量、降雨量、监测时间;
15.步骤s12:选择水位、泄洪量、降雨量、监测时间,将其按照时间对齐,使每一条数据都为同一时间的水位、泄洪量、降雨量;
16.步骤s13:选择近期的一段缺失值较少的数据,使用上一个或者下一个值填补其中的缺失。
17.进一步的,所述步骤s2具体为:
18.步骤s21:构造的函数表达式,并根据f(α)、水库水位观测时间,进行时效分量构造,得到时效分量
19.f(α)=a1α+a
2 lnα
20.其中a1,a2为系数,t为监测当日至起始监测日的累计天数;
21.步骤s22:水位特征变换的函数表达式如下所示:
[0022][0023]
其中水库水位数据采集时间为t
t
(t=0,1,2,
…
,n),为t0~tn时段的水库水位,hi为的任意一个非空子集,w为水库水位。
[0024]
根据f(w)进行水库水位特征变换得w1,w2,w3分别为:
[0025][0026]
进一步的,所述步骤s3具体为:
[0027]
步骤s31:将mse作为粒子群寻优模型超参数的评价指标,cnn-lstm模型中的loss作为pso寻优的目标函数
[0028]
步骤s32:将cnn-lstm模型嵌入pso模型中,同时将模型需要寻优的超参数设置为粒子群对应的维度,设置完成后进行迭代,在寻优迭代完成后选取loss值最小的一组作为cnn-lstm模型的超参数。
[0029]
进一步的,所述步骤s4具体为:
[0030]
步骤s41:采用最大最小值进行归一化,归一化函数表达式如下所示:
[0031][0032]
其中x为单个数据的取值,min为数据所在列的最小值,max为数据所在列的最大值;
[0033]
步骤s42:归一化后得数据集,并按数据采集时间进行排序,并按预设比例划分为训练集和测试集;
[0034]
步骤s43:根据划分好的训练集、测试集,将其拆分为自变量和因变量;
[0035]
步骤s44:将拆分出来的组自变量、因变量,将其重塑为cnn-lstm模型可读3d数据,重塑后数据形状为shape。
[0036]
1.进一步的,所述cnn-lstm模型的自变量为n=(batch_size-width)/width组包括rainfall、flood_discharge、timeffcent、ln_timeffcent、water_ago1level、water_ago2level、water_level特征的矩阵;batch_sizew为数据量,width自变量窗口宽度;自变量矩阵序列表示为f(x),其函数表达式如下:
[0037]
f(x)=(x0,x1,x2,
…
,xn),(n∈z
*
)
[0038]
将其中f(x)中矩阵x0展开如下:
[0039][0040]
矩阵k
ij
中,i为自变量窗口宽度,j为输入特征维度。
[0041]
因变量序列为:
[0042]
y={x
i,j
,x
i+1,j
,x
i+2,j
,
…
,x
n-i,j
}
[0043]
进一步的,所述步骤s5具体为:
[0044]
步骤s51:将步骤s4处理完的训练集数据,输入cnn-lstm模型,将数据读入conv1d中进行特征融合;
[0045]
步骤s52:将融合后的特征进行池化,池化完成后的数据、pso模型搜索到的超参数输入lstmlayers中进行训练,训练完成后通过fatten layers进行降维,将降维后数据输入dense layers指定维度并输出的预测特征。
[0046]
本发明与现有技术相比具有以下有益效果:
[0047]
1、本发明基于pso-cnn-lstm模型的水库水位预测预警方法,使用历史水位、降雨量、泄洪量、时效因子预测未来水位。能有效的把握未来水库水位的变化趋势,从而进行水库水位的调度。
[0048]
2、本发明使用cnn进行数据的特征融合,能有效的将数据特征细粒度化,细粒度化后使用lstm进行模型训练,提取其粗粒度特征信息,使模型有更好的预测效果。
附图说明
[0049]
图1是本发明方法流程图;
[0050]
图2是本发明一实施例中cnn-lstm水库水位预测架构图;
[0051]
图3是本发明一实施例中数据拆分示意图;
[0052]
图4是本发明一实施例中特征融合方式示意图;
[0053]
图5是本发明一实施例中详细特征融合方式示意图。
具体实施方式
[0054]
下面结合附图及实施例对本发明做进一步说明。
[0055]
请参照图1,本发明提供一种基于pso-cnn-lstm的水库水位预测预警方法,包括以下步骤:
[0056]
步骤s1:获取水库历史监测数据,并预处理,具体为:
[0057]
步骤s11:获取水库历史监测数据包括水库的水位、泄洪量、降雨量、监测时间;
[0058]
步骤s12:选择水位、泄洪量、降雨量、监测时间,将其按照时间对齐,使每一条数据都为同一时间的水位、泄洪量、降雨量;
[0059]
步骤s13:选择近期的一段缺失值较少的数据,使用上一个或者下一个值填补其中的缺失。
[0060]
步骤s2:将预处理后的水库历史监测数据按采集时间进行排序,构建特征数据集,具体为:
[0061]
步骤s21:构造的函数表达式,并根据f(α)、水库水位观测时间,进行时效分量构造,得到时效分量
[0062]
f(α)=a1α+a
2 lnα
[0063]
其中a1,a2为系数,t为监测当日至起始监测日的累计天数;
[0064]
步骤s22:水位特征变换的函数表达式如下所示:
[0065][0066]
其中水库水位数据采集时间为t
t
(t=0,1,2,
…
,n),为t0~tn时段的水库水位,hi为的任意一个非空子集,w为水库水位。
[0067]
根据f(w)进行水库水位特征变换得w1,w2,w3分别为:
[0068][0069]
步骤s3:使用pso算法对cnn-lstm模型的回溯长度、lstm层神经元个数、dropout率、读入容量等超参数进行寻优,以获得更优的模型超参数,其中pso的目标函数设置为mse,设置pso模型的参数,即惯性权重、学习因子、粒子个数、粒子群搜索维度。其中粒子群搜索维度分别为cnn-lstm模型的回溯长度、两层lstm层神经元个数、两层dropout率及批次读入模型的数据容量
[0070]
将mse作为粒子群寻优模型超参数的评价指标,cnn-lstm模型中的loss作为pso寻优的目标函数。
[0071]
将cnn-lstm模型嵌入pso模型中,同时将模型需要寻优的超参数设置为粒子群对应的维度,设置完成后进行迭代,在寻优迭代完成后选取loss值最小的一组作为cnn-lstm模型的超参数。
[0072]
步骤s4:对特征数据集进行处理,并划分为训练集和测试集,具体为:
[0073]
步骤s41:采用最大最小值进行归一化,归一化函数表达式如下所示:
[0074][0075]
其中x为单个数据的取值,min为数据所在列的最小值,max为数据所在列的最大值;
[0076]
步骤s42:归一化后得数据集,并按数据采集时间进行排序,并按预设比例划分为训练集和测试集;
[0077]
步骤s43:根据划分好的训练集、测试集,将其拆分为自变量和因变量;
[0078]
步骤s44:将拆分出来的组自变量、因变量,将其重塑为cnn-lstm模型可读3d数据,重塑后数据形状为shape。
[0079]
2.在本实施例中,cnn-lstm模型的自变量为n=(batch_size-width)/width组包括rainfall、flood_discharge、timeffcent、ln_timeffcent、water_ago1level、water_ago2level、water_level特征的矩阵;batch_sizew为数据量,width自变量窗口宽度;自变量矩阵序列表示为f(x),其函数表达式如下:
[0080]
f(x)=(x0,x1,x2,
…
,xn),(n∈z
*
)
[0081]
将其中f(x)中矩阵x0展开如下:
[0082][0083]
矩阵k
ij
中,i为自变量窗口宽度,j为输入特征维度。
[0084]
因变量序列为:
[0085]
y={x
i,j
,x
i+1,j
,x
i+2,j
,
…
,x
n-i,j
}
[0086]
步骤s5:基于步骤s3得到的最优参数和训练集,构建并训练cnn-lstm模型;
[0087]
步骤s51:将步骤s4处理完的训练集数据,输入cnn-lstm模型,将数据读入conv1d中进行特征融合;
[0088]
步骤s52:将融合后的特征进行池化,池化完成后的数据、pso模型搜索到的超参数输入lstmlayers中进行训练,训练完成后通过fattenlayers进行降维,将降维后数据输入denselayers指定维度并输出的预测特征。
[0089]
步骤s6:基于训练后的cnn-lstm模型,进行水库水位实时预测。
[0090]
实施例1:
[0091]
在本实施例中,使用kafka读入传感器采集到的水库水位、泄洪量、降雨量等数据。生产者通过调用kafka相关的pythonapi,将从流数据中读取出来的消息,生产并push到broker中。消费者则通过相应的分区分配策略,通过pull操作将流数据从broke拉取出来,cnn-lstm模型中。
[0092]
基于训练好的训练好的cnn-lstm模型,将数据读入cnn-lstm模型中进行水库水位预测,预测完成后将预测值保存,以备后步骤使用。
[0093]
根据保存的水库水位预测值,使用该预测值与水库标准安全水位进行对比。若判断条件成立,将保存的预测值与水库标准安全水位输出,并根据输出的预测信息及水库标准安全水位信息,进行水库水位调度,流程结束;若判断条件不成立则结束流程。
[0094]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1