基于可视化分布GAN的MSWI过程二噁英排放风险预警方法
基于可视化分布gan的mswi过程二噁英排放风险预警方法
技术领域
1.本发明属于城市固废焚烧领域。
背景技术:
2.城市固废(municipal solid waste,msw)的产生量随城市人口的不断增加而逐年提高。城市固废焚烧(msw incineration,mswi)是当今世界大部分国家采用的具有无害化、减量化和资源化等优势的处理手段。由于mswi过程所产生的副产品二噁英(dioxins,dxn)为剧毒污染物,不但损害中毒者的内分泌系统和破坏染色体进而导致细胞癌变,而且在生物体内具有累积效应,是造成焚烧建厂存在“邻避效应”的主要原因。因此,控制其排放是亟需解决的环保问题。对dxn排放的风险等级进行预警,进而优化控制mswi过程,对减少污染物排放具有重要的实际意义。
3.目前,工业界主要对mswi过程末端烟囱排放烟气中的dxn进行检测。离线直接检测法和在线间接检测法均很难满足mswi过程以减少dxn排放为目的的实时优化控制。此外,由于dxn排放浓度检测的难度大、周期长、费用昂贵,导致构建数据驱动模型的样本真值极其稀少。因此,本技术所研究的mswi过程dxn排放浓度检测问题属于典型的小样本问题,具有样本数量少、样本不平衡等特性。通常而言,较少数量的建模样本难以准确反映工业过程的真实特性,难以构建鲁棒可靠的污染物浓度排放回归预测模型;相对而言,构建风险判别分类模型较为容易。此外,工业现场领域专家也常习惯于用排放浓度的低、中、高等等级语言描述污染排放程度的风险,并依据自身经验获得判别结果以调整相关控制参数。但是,样本的不平衡,即某类样本的数量远小于其他类,这也是导致所构建的风险判别模型具有片面性和偏差性的主要原因。
4.综上,本技术提出基于主动学习机制gan的mswi过程dxn排放风险预警模型构建方法。首先,在原始gan的基础上引入dxn风险等级作为条件信息,将其与随机噪声输入生成器后生成预设定dxn风险等级的虚拟样本,与真实样本共同输入判别器后根据判别结果更新生成器和判别器;接着,先使用最大均值差异(maximum mean discrepancy,mmd)对虚拟样本进行初筛,再对初筛虚拟样本采用主成分分析(principal component analysis,pca)以获得可视化分布信息,根据其判断初筛虚拟样本是否合格;最后,基于虚拟样本和真实样本组成的混合样本构建dxn排放风险预警模型。结合实际dxn数据验证了所提方法的有效性。
5.国内某mswi电厂的炉排炉焚烧工艺流程如图1所示。
6.由图1可知,msw由专用车辆收集、称重后运输至卸料大厅,倾倒入密封的固废池中,并通过抓斗送至焚烧炉料斗内,由给料器推至炉排;msw在焚烧炉内依次经历干燥、点燃、燃烧和燃烬四个阶段,燃烬后的残渣落入水冷渣斗后由捞渣机送至灰渣坑中,收集后送至填埋场处理;焚烧过程产生的烟气加热余热锅炉产生高压蒸汽进而推动汽轮发电机发电;添加活性炭和消石灰后,锅炉出口烟气中进入反应器,产生的飞灰进入飞灰储罐,烟气进入袋式除尘器去除烟气颗粒物、中和反应物和活性炭吸附物,处理之后分为三部分:尾部飞灰进入飞灰罐,部分烟灰混合物在混合器中加水后重新进入反应器,尾部烟气通过引风
机经烟囱排入大气,其中包含hcl、so2、co、co2、no
x
和dxn等物质。
7.由于固废不完全燃烧和新规合成反应生成两种原因导致mswi过程产生的焚烧灰、飞灰和烟气中包含dxn。因此,焚烧过程中烟气需要达到850℃并保持2s以确保有毒有机物的有效分解。在烟气处理阶段向反应器内注入石灰和活性炭,吸附dxn和部分重金属,然后经袋式除尘器过滤通过引风机排入烟囱,以减少排放烟气中的dxn浓度。此外,该阶段产生的积灰存在的dxn记忆效应也会导致dxn排放浓度增加。现场分布式控制系统(dcs)采集和存储上述各阶段与dxn相关的过程变量以及常规污染物(co、hcl、so2、no
x
和hf等)浓度。然而,由于高成本和长周期等原因使得排放烟气中dxn的检测较为困难。
8.由上可知,构建dxn排放风险预警模型的样本存在数量少、分布不均和维数高等特点。因此,本技术提出一种基于主动学习机制虚拟样本对抗生成策略建立mswi过程dxn排放风险预警建模。
技术实现要素:
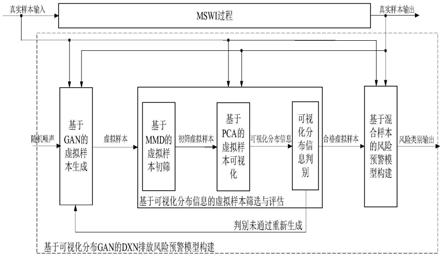
9.本技术提出的基于主动学习机制gan的mswi过程dxn排放风险预警模型构建策略,包括:基于gan的虚拟样本生成、基于可视化分布信息的虚拟样本评估与筛选和基于混合样本的风险预警模型构建三个模块,如图2所示。
10.在图2中,真实样本输入和对应的输出分别记为x
real
和y
real
;随机噪声记为x
noise
;gan生成器生成的虚拟样本记为其中表示虚拟样本输入集,表示对应的虚拟样本输出集;经过mmd初筛的虚拟样本记为其中表示初筛虚拟样本输入集,表示对应初筛虚拟样本输出集;可视化分布信息记为d
pca
;经过可视化分布信息判别得到的合格虚拟样本记为其中表示合格虚拟样本输入集,表示对应的合格虚拟样本输出集;所构建风险预警模型的风险类别输出记为
11.该策略不同模块的功能如下:
12.1)基于gan的虚拟样本生成模块:在原始gan的基础上引入dxn排放风险等级作为条件信息,将其和随机噪声共同输入生成器以生成指定类型的虚拟样本;进一步,将虚拟样本和真实样本再输入判别器,并根据判别结果更新生成器和判别器;最后,在生成器和判别器的博弈对抗中,使得生成的虚拟样本越来越接近真实样本。
13.2)基于可视化分布信息的虚拟样本筛选与评估模块:首先,使用mmd计算虚拟样本和真实样本的相似程度对虚拟样本进行初筛;然后,基于pca进行虚拟样本可视化以获得降维后的分布信息;最后,依据分布信息进行判别并确定是否合格,若是,则标定为合格虚拟样本;若否,则重新生成虚拟样本。
14.3)基于混合样本的风险预警模型构建模块:基于混合样本采用随机森林算法构建dxn排放风险预警模型。
15.4.1基于gan的虚拟样本生成模块
16.gan是一种基于博弈场景的无监督生成模型,通过生成器和判别器的博弈对抗生成接近真实样本的虚拟样本。由于原始gan生成的虚拟样本类型不可控,本模块在原始gan的基础上引入dxn排放风险等级作为条件信息控制生成虚拟样本的类型。
17.基于gan的虚拟样本生成流程如图3所示。
18.虚拟样本生成的流程为:首先,将x
noise
和y
real
共同输入生成器以生成虚拟样本的输入接着,将x
real
、和y
real
再输入判别器,根据判别结果y
real/vir
更新生成器和判别器;然后,将x
noise
和期望生成的dxn排放风险等级输入训练好的生成器以生成最后,将和组合,得到虚拟样本
19.本技术中,每批训练样本数设为nb,学习率为α
ir
,最大训练代数为ne。生成器采用三层神经网络,隐含层使用relu激活函数,输出层使用线性激活函数,如下:
[0020][0021]
其中,ω
g1
为生成器输入层和隐含层之间的权值;b
g1
为生成器输入层和隐含层之间的偏置;relu激活函数relu(x)=max(0,x),x为任意输入值;为生成器隐含层输出;ω
g2
为生成器隐含层和输出层之间的权值;b
g2
为生成器隐含层和输出层之间的偏置。
[0022]
判别器采用三层神经网络,隐含层使用relu激活函数,输出层使用sigmoid激活函数,如下:
[0023][0024]
其中,为和(x
real
,y
real
)组成的混合样本;ω
d1
为判别器输入层和隐含层之间的权值;b
d1
为判别器输入层和隐含层之间的偏置;为判别器隐含层输出;ω
d2
为判别器隐含层和输出层之间的权值;b
d2
为判别器隐含层和输出层之间的偏置;sigmoid激活函数x为任意输入值。
[0025]
目标函数o
gan
如式(3)所示:
[0026][0027]
其中,p
data
(x
real
)表示x
real
的分布;为判别器对于(x
real
,y
real
)的输出;p
noise
(x
noise
)表示x
noise
的分布;为判别器对于的输出。
[0028]
判别器计算样本是来自p
noise
(x
noise
)还是p
data
(x
real
)的概率,生成器根据判别器结果学习真实样本的分布p
data
(x
real
)以减少log(1-y
dvir
),生成器和判别器在最小最大的博弈对抗中共同训练。
[0029]
4.2基于可视化分布信息的虚拟样本筛选与评估模块
[0030]
基于可视化分布信息的虚拟样本筛选与评估流程是:首先,根据虚拟样本和真实样本的mmd值对虚拟样本进行初筛;然后,对虚拟样本的pca可视化分布信息进行最终判断;最后,若判别不通过则重新生成虚拟样本,继续执行上述操作,若判别通过则得到合格的虚拟样本。流程如图4所示。
[0031]
4.2.1基于mmd的虚拟样本初筛模块
[0032]
首先,取若干个生成器,生成若干组虚拟样本。
[0033]
接着,计算每组虚拟样本质量。本技术中,采用mmd度量虚拟样本与真实样本的总体均值差异,进而衡量两者之间的分布差异。
[0034]
假设,服从分布其中是一组虚拟样本数量;服从分布p
real
,n
real
是真实样本数量。进一步,通过高维映射函数获得两个域样本在再生希尔伯特空间(reproducing kernel hilbert space,rkhs)中期望差值的上确界,即:
[0035][0036]
其中,h为rkhs,φ(
·
)表示将样本映射到高维rkhs,和eq[φ(x
real
)]表示样本映射到rkhs中的期望值,σ是高斯核的带宽。
[0037]
根据式(4)分别计算n组虚拟样本与真实样本(x
real
,y
real
)的mmd值以对其进行初筛,为第一组虚拟样本,为第二组虚拟样本,为第n组虚拟样本,初筛函数如下:
[0038][0039]
其中,min(
·
)表示取n组虚拟样本与(x
real
,y
real
)mmd值最小的那组虚拟样本,即其作为质量最好的初筛虚拟样本
[0040]
4.2.2基于pca的虚拟样本可视化模块
[0041]
本技术中的dxn样本为高维样本,难以对所生成的虚拟样本的分布进行直观地感受。因此,本技术采用pca将虚拟样本降到1维进行可视化以提供整体分布信息
[0042]
pca通过一组正交向量将原始数据投影到新的空间,消除了原始数据冗余的同时保留了主要信息。基于pca的虚拟样本可视化实现步骤如下。
[0043]
首先,对进行中心化处理,得到中心化样本u,其中为样本数量,为样本维数;
[0044]
接着,计算u的协方差矩阵c:
[0045]
c=uu
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0046]
然后,采用特征分解法计算c的特征向量和特征值:
[0047]
c=wλw
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0048]
其中,w为特征向量组成的矩阵;λ为特征根按照从大到小顺序排列的对角阵;
[0049]
再然后,将降到1维,如下:
[0050]
x
pca
=μ1u
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0051]
式中,x
pca
为降到1维的虚拟样本;μ1为最大特征值对应的特征向量。
[0052]
最后,计算x
pca
分布函数,得到pca可视化结果。
[0053]
4.2.3可视化分布信息判别模块
[0054]
虚拟样本pca可视化结果提供的整体分布信息d
pca
:
[0055]dpca
=(r
real
∩r
vir
)/s
real
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0056]
其中,r
real
为真实样本分布函数与x轴包含的区域;r
vir
为虚拟样本分布函数与x轴包含的区域;s
real
为真实样本分布函数与x轴包含的区域的面积;r
real
∩r
vir
表示r
real
与r
vir
重叠部分的面积。
[0057]
本技术提出的可视化分布信息判别函数如下:
[0058][0059]
其中,θs为依据经验设定的阈值。
[0060]
若φ
visual
(d
pca
)的值为1,表示该虚拟样本为合格虚拟样本;反之,该虚拟样本为不合格虚拟样本。
[0061]
4.3基于混合样本的风险预警模型构建模块
[0062]
判别得到的合格虚拟样本和真实样本(x
real
,y
real
)组合,得到混合样本s
mix
。
[0063][0064]
使用随机森林(random forest,rf)作为风险预警模型的分类器,步骤如下。
[0065]
首先,利用bootstrap算法和rsm算法对s
mix
进行样本和特征的随机采样,获得n个子样本集;
[0066]
接着,利用n个子样本集构建n个决策树,每个决策树得到一个分类结果;
[0067]
最后,对n个分类结果进行投票,选择投票数量最多的类别作为最终的分类结果
附图说明
[0068]
图1基于炉排炉的mswi工艺流程图
[0069]
图2基于主动学习机制gan的dxn排放风险预警模型构建策略
[0070]
图3基于gan的虚拟样本生成流程图
[0071]
图4基于主动学习机制的虚拟样本评估和筛选流程
[0072]
图5基于dxn数据生成虚拟样本质量和epoch的关系
[0073]
图6dxn数据集50次风险预警模型的精度
[0074]
图7dxn数据测试风险预警实验结果
具体实施方式
[0075]
本技术所采用的dxn数据来自北京某基于炉排炉的mswi电厂,涵盖了2012~2018年所记录的67个有效dxn排放浓度检测样本;原始输入特征经过处理后从314维降至120维,此处将输出dxn排放浓度分为5个风险等级,其划分标准如表1所示,其中,高风险、中高风险、中风险、中低风险和低风险相应的样本数为27、12、11、11和6。随机选择2/3作为训练集构建模型,剩下的1/3用于测试模型性能。
[0076]
表1 dxn排放风险等级划分标准
[0077][0078]
对于dxn数据集:生成器隐含层采用relu激活函数,输出层采用线性激活函数;判别器隐含层采用relu激活函数,输出层采用sigmoid激活函数,具体参数设置如表2所示。
[0079]
表2 dxn数据集虚拟样本生成实验参数设置
[0080][0081]
图5表示基于dxn数据生成虚拟样本质量和epoch的关系。
[0082]
由图5可知,当epoch达到1000时,生成虚拟样本的质量达到稳定。因此,从1100次到2000次训练中每100次选择一个生成器,共10个生成器,每个生成器生成10组虚拟样本集,每组虚拟样本的5个风险等级各60个,共300个虚拟样本。从10个生成器的10组虚拟样本集筛选出与真实样本mmd值最低的作为初筛后的虚拟样本集。实验结果如表3所示。
[0083]
表3 dxn数据集基于mmd的虚拟样本初筛实验结果
[0084][0085]
由表3可知,第2000次训练得到的生成器生成的第4组虚拟样本与真实样本的mmd值最低,因此选择该组虚拟样本。
[0086]
为保证可视化的效果,从300个虚拟样本随机选择27个低风险、12个中低风险、11个中风险、11个中高风险、6个高风险,共67个虚拟样本进行可视化。依据经验将阈值设为0.8,可视化结果得到的分布信息为0.81大于设定阈值。因此,该组虚拟样本为合格虚拟样本。
[0087]
使用上述合格虚拟样本和真实样本组成混合样本构建风险预警模型,相关参数如表4所示。
[0088]
表4 dxn数据集混合样本风险预警模型构建的相关参数
[0089][0090]
50次实验的精度如图6所示。
[0091]
由图6可知,混合样本训练的风险预警模型性能好于真实样本训练的模型。
[0092]
此外,共进行5组对比实验,相关参数如表5所示。
[0093]
表5 dxn数据集基于混合样本的风险预警模型构建相关参数
[0094][0095]
表5中,风险等级按照高风险、中高风险、中风险、中低风险和低风险的顺序排列。虚拟样本从筛选虚拟样本中随机抽取,其中不平衡虚拟样本和不平衡混合样本指其中各风险等级样本比例与真实样本的比例相同,平衡虚拟样本和平衡混合样本指其各风险等级的样本数相同。
[0096]
考虑rf算法的随机性,5种实验均重复执行50次。图7为实验a、b、c、d和e所构建的风险预警模型的准确率,表6得出了统计结果的对比。
[0097]
表6 dxn数据测试风险预警统计结果对比
[0098][0099]
由上可知:1)真实样本的平均准确率为48.9091%,不平衡虚拟样本的平均准确率为48.0909%,平衡虚拟样本的平均准确率为47.4989%,本技术所提方法生成的虚拟样本很接近真实样本;2)基于混合样本的平均准确率为70.8444%和78.8085%,相较于未添加虚拟样本的准确率提升了44%和59%,表明添加虚拟样本有助于提高模型性能;3)平衡混合样本的平均准确率相较于不平衡混合样本提高了11%,表明平衡数据建模效果好于不平衡数据;4)混合样本准确率的标准差低于真实样本,表明添加虚拟样本有助于提高模型的稳定性。
[0100]
本技术提出基于可视化分布gan的mswi过程dxn排放风险预警方法,创新性表现在:1)首次提出基于gan和可视化分布的dxn排放浓度风险预警策略;2)基于gan的vsg方法
可以通过条件信息生成指定类型的虚拟样本,有效的扩展样本数量,填补真实样本的信息空白;3)基于可视化分布信息的虚拟样本评估和筛选方法使用mmd对虚拟样本进行初筛,对初筛虚拟样本可视化结果提供的分布信息进行判别,判别通过后得到合格的虚拟样本,合格虚拟样本的质量更加接近真实样本。基于工业dxn数据验证了所提策略和方法的有效性。未来研究方向包括:如何处理高维、离散的过程数据,如何使生成器和判别器在博弈对抗的过程中更加稳定,以获得更优质的虚拟样本。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1