基于组合识别和空间相关性的新能源出力异常校正方法与流程
1.本发明属于电力系统技术领域,具体涉及基于组合识别和空间相关性的新能源出力异常校正方法。
背景技术:
2.随着全球经济的快速发展,能源需求量呈现逐年增长趋势。在环境污染日益严峻和化石能源紧缺的双重压力下,新能源凭借可再生、清洁、低碳等优势,在世界范围内受到高度重视和广泛应用。但新能源发电出力的间歇性、随机性和波动性,导致新能源大规模并网时给电力系统稳定运行造成一定冲击。准确掌握新能源出力预测,有利于采取相应的稳定控制措施,帮助提高新能源利用率以及新能源消纳能力。预测前,需要对采集的原始新能源出力数据进行挖掘。然而,由于电厂运行时机组存在弃风、弃光现象、此外,受极端天气、外界电磁干扰或设备故障等影响,导致原始数据中存在大量异常值。数据挖掘过程中,这些不良数据将严重干扰真实的新能源出力特性,导致特性分析存在偏差,影响后续应用,造成预测精度低等后果。因此,对新能源出力进行有效的异常值识别和校正是十分必要的。
3.目前,常用异常数据识别方法大致可以分为数学方法和人工智能算法。数学方法中包括统计量分析法、3sigma法和四分位法。统计量分析法通过对变量做描述性统计,判断不合理数据,适用于处理不在有效数据范围内的堆积型异常数据,但不适用于处理大量的分散型异常数据。3sigma法则基于数据服从正态分布的假设,依据分布在距离平均值3sigma之外的数据的概率不到0.3%,将超过3倍标准差的数据视为异常值。然而由于实际新能源发电数据往往并不严格服从正态分布,导致3sigma法的应用受限。四分位法将数据按照升序平均分为四份,计算异常值范围,将超出上下限的数据判为异常值。四分位法根据实测数据进行离群值分析,且不需要事先假设数据服从某种分布,因此,受到广泛应用,但当异常数据比重较大时,异常数据识别效果显著下降。人工智能法包括支持向量机回归和基于密度的离群点检测等算法。支持向量机回归算法是用函数拟合数据,但当数据中存在大量异常值时,回归估计过程中会因趋近异常数据而发生畸变,导致回归拟合效果不理想。基于密度的离群点检测算法则是依据同一簇内数据对象周围的密度与其邻域周围的密度相似,判断落在簇外的数值为离群点,识别异常数据,可以有效实现分散性数据的辨识。仅仅使用单个的数学方法或者人工智能算法进行异常数据识别存在着一定的局限性,为改善单一方法的不足,本发明提出一种结合四分位数和基于密度的离群点检测组合异常数据识别方法,为更全面、更准确地检测新能源出力异常值。对检测出的异常数据进行校正也会影响用于后续应用的数据质量,传统的校正方法包括基于统计学的重构方法和基于机器学习的重构方法。但这些方法仅仅是基于数学统计规律对单个数据序列中异常值进行校正,导致校正过程完全未考虑新能源电站的自然条件和出力特性,因此,本发明还提出基于组合异常识别和计及空间相关性的新能源出力异常校正方法,结合存在相关性的新能源电站出力进行校正避免校正值脱离实际。
技术实现要素:
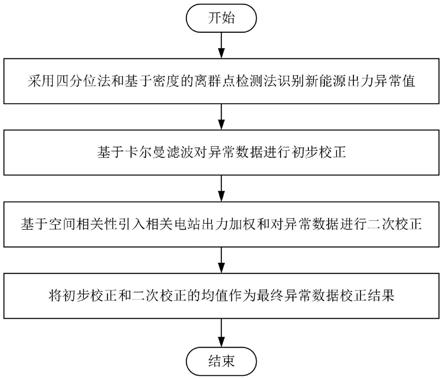
4.发明目的:本发明针对目前新能源出力数据异常识别和校正方法的不足,包括异常识别类型不完全以及异常数据校正值脱离新能源电站实际历史自然条件等问题,提出基于组合异常识别和计及空间相关性的新能源出力异常校正方法,采用基于四分位法和离群点检测的组合法识别异常数据,然后通过卡尔曼滤波并计及空间相关性校正异常数据,使新能源出力异常值被充分识别并且校正值更加符合其出力特性。
5.技术方案:本发明提供了基于组合识别和空间相关性的新能源出力异常校正方法,包括以下步骤:
6.(1)采用四分位法和基于密度的离群点检测法对新能源出力数据进行异常值识别;
7.(2)基于卡尔曼滤波获取异常数据初步校正结果;
8.(3)基于互信息计算新能源电站出力间的空间相关性,为各新能源电站选择多个相关的电站;
9.(4)基于所选电站出力的加权和对异常数据进行二次校正;
10.(5)将初步校正和二次校正结果的平均值作为最终的异常数据修正值。
11.进一步地,步骤(1)中,所述的四分位法为:
12.a)假设数据长度为n,将新能源出力数据按照从小到大的顺序进行排列,经过排序后的数据为:
13.x=[x1,x2,...,xn]
[0014]
其中,xi为升序排列中第i个新能源出力值,i=1,2,...,n;
[0015]
b)将改组数据平均分成4份,每份序列占总序列的25%,共有3个分界点,由小到大依次为下四分位数q1,中位数q2,上四分位数q3,其中,第2个四分位数计算公式如下:
[0016][0017]
c)下四分位数和上四分位数的计算公式如下:
[0018]
当n=2k(k=1,2,
…
)时,从q2处将样本x分为两部分,且q2不包含在两部分数据内,分别计算两部分的中位数q
′2和q
″2(q
′2《q
″2),则q1=q
′2,q3=q
″2;
[0019]
当n=4k+3(k=0,1,2,
…
)时,有:
[0020][0021]
当n=4k+1(k=0,1,2,
…
)时,有:
[0022][0023]
d)根据上下四分位数计算四分位距:
[0024]iqr
=q
3-q1;
[0025]
e)根据四分位距,确定数据样本中异常值的内限[f
l
,fu]为
[0026][0027]
其中,f
l
表示内限的下限值,fu表示内线的上限值;处于内限以外的数据均判为异常值。
[0028]
进一步地,步骤(1)中,所述的基于密度的离群点检测法为:
[0029]
给定一个n维样本数据集s={s1,...sn},每个样本si={p1,...pm}si∈s是一个m维数据,局部离群点算法的基本定义如下:
[0030]
f)对象si的k-距离用distk(si)表示,是对象si和sj之间的距离dist(si,sj),si∈s,其中dist(si,sj) 采用欧氏距离公式计算,sj∈s,且sj满足以下条件:
[0031]
1)至少有k个对象s
′
l
∈s\{si},使得dist(si,s
′
l
)≤dist(si,sj);
[0032]
2)至多有k-1个对象s
″
l
∈s\{si},使得dist(si,s
″
l
)≤dist(si,sj);
[0033]
其中,s\{si}表示数据集s除样本si以外的子集;dist(si,s
′
l
)表示对象si和s
′
l
间的距离; dist(si,s
″
l
)表示对象si和s
″
l
间的距离;dist(si,sj)表示对象si和sj间的距离;
[0034]
g)对象si的k-邻域用nk(si)表示,该邻域包含数据集中所有与si的距离不大于k-距离distk(si)的对象,是一个集合:
[0035]
nk(si)={so|so∈s\{si},dist(si,so)≤distk(si)}
[0036]
式中,dist(si,so)表示对象si和so间的距离;distk(si)表示对象si的k-距离;
[0037]
h)对象si相对于对象so的可达距离用reach_distk(si,so)表示,计算公式如下:
[0038]
reach_distk(si,so)=max{dist(si,so),distk(si)}
[0039]
式中,dist(si,so)表示对象si和so间的距离;distk(si)表示对象si的k-距离;
[0040]
i)对象si的局部可达密度用lrd(si)表示,计算公式如下:
[0041][0042]
式中,|nk(si)|表示邻域所含元素的绝对值之和;reach_distk(si,so)表示对象si相对于对象so的可达距离;
[0043]
j)对象si的局部离群因子用lofk(si)表示:
[0044][0045]
式中,|nk(si)|表示邻域所含元素的绝对值之和;lrd(si)表示对象si的局部可达密度;
[0046]
对数据集s中每个数据对象重复步骤f)至j)计算出局部离群因子,将这些值按照从大到小降序排列,将离群因子较大的z个数据对象视为数据集s的离群点集合;将采用四分位法和基于密度的离群点检测法识别出的异常值取并集作为最终的异常识别结果。
[0047]
进一步地,所述步骤(2)中,基于卡尔曼滤波的异常数据初步校正法为:
[0048]
2.1卡尔曼滤波算法中的状态方程和量测方程分别为:
[0049]
xk=fkx
k-1
+ωk[0050]
yk=hkxk+vkq=1,2,...,k;
[0074]
则这k个相关电站出力的加权和即异常值二次校正结果为:
[0075][0076]
进一步地,所述步骤(5)具体为:
[0077]
从二次校正序列中取出与待校正电站异常数据相同位置的值,与一次校正结果求取平均值,作为最终的异常数据校正结果。
[0078]
有益效果:与现有技术相比,本发明提出了基于组合异常识别和计及空间相关性的新能源出力异常校正方法,利用四分位法和基于密度的离群检测法识别出分散型异常值和堆积型异常值,基于卡尔曼滤波对异常数据进行初步校正,同时,考虑了新能源出力间的空间相关性,对异常数据进行二次校正,使得校正结果更加贴合新能源电站实际自然气象条件,有利于提升新能源出力数据质量,避免异常值的干扰。本发明可为新能源出力预测提供更高质量的原始数据,有利于提高预测准确度,为新能源大规模接入电网制定相应的稳定控制措施,同时,也有利于提升新能源消纳水平,促进新能源发电进一步发展。
附图说明
[0079]
图1为本发明基于组合识别和空间相关性的新能源出力异常校正方法的流程示意图。
[0080]
图2为实施例中某风电场基于本发明所提四分位法和离群点检测法的组合异常识别结果。
[0081]
图3为实施例中某风电场基于本发明计及空间相关性的数据异常校正结果。
具体实施方式
[0082]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0083]
本发明提供了一种基于组合异常识别和计及空间相关性的新能源出力异常校正方法,如图1所示,该方法包括以下步骤:
[0084]
(1)采用四分位法和基于密度的离群点检测法对新能源出力数据进行异常值识别;
[0085]
(2)基于卡尔曼滤波获取异常数据初步校正结果;
[0086]
(3)基于互信息计算新能源电站出力间的空间相关性,为各新能源电站选择多个相关的电站;
[0087]
(4)基于所选电站出力的加权和对异常数据进行二次校正;
[0088]
(5)将初步校正和二次校正结果的平均值作为最终的异常数据修正值。
[0089]
下面详细说明使用本发明中的方法进行新能源出力异常数据识别和校正的具体实施过程。以某地区新能源电站出力数据为例,共包含16个风电场,每个风电场的出力数据包含从 2018年10月1日至2019年9月30日每5分钟一测的历史数据,取整点时刻的出力值构成每小时一点的出力序列进行测试。
[0090]
步骤(1)采用四分位法和基于密度的离群点检测法对新能源出力数据进行异常值识别,所述的四分位法为:
[0091]
假设数据长度为n,将新能源出力数据按照从小到大的顺序进行排列,经过排序后的数据为:
[0092]
x=[x1,x2,...,xn]
[0093]
其中,xi为升序排列中第i个新能源出力值,i=1,2,...,n。
[0094]
将改组数据平均分成4份,每份序列占总序列的25%,共有3个分界点,由小到大依次为下四分位数q1,中位数q2,上四分位数q3。其中,第2个四分位数计算公式如下:
[0095][0096]
下四分位数和上四分位数的计算公式如下:
[0097]
当n=2k(k=1,2,
…
)时,从q2处将样本x分为两部分,且q2不包含在两部分数据内,分别计算两部分的中位数q
′2和q
″2(q
′2《q
″2),则q1=q
′2,q3=q
″2。
[0098]
当n=4k+3(k=0,1,2,
…
)时,有:
[0099][0100]
当n=4k+1(k=0,1,2,
…
)时,有:
[0101][0102]
根据上下四分位数计算四分位距:
[0103]iqr
=q
3-q1[0104]
根据四分位距,确定数据样本中异常值的内限[f
l
,fu]为如下,处于内限以外的数据均判为异常值。
[0105][0106]
其中,f
l
表示内限的下限值,fu表示内线的上限值。
[0107]
步骤(1)采用四分位法和基于密度的离群点检测法对新能源出力数据进行异常值识别,所述的基于密度的离群点检测法为:
[0108]
假设给定一个n维样本数据集s={s1,...sn},每个样本si={p1,...pm}si∈s是一个m维数据。局部离群点算法的一些基本定义如下:
[0109]
对象si的k-距离用distk(si)表示,是对象si和sj之间的距离dist(si,sj),si∈s,其中dist(si,sj)采用欧氏距离公式计算,sj∈s,且sj满足以下条件:
[0110]
1)至少有k个对象s
′
l
∈s\{si},使得dist(si,s
′
l
)≤dist(si,sj);
[0111]
2)至多有k-1个对象s
″
l
∈s\{si},使得dist(si,s
″
l
)≤dist(si,sj);
[0112]
其中,s\{si}表示数据集s除样本si以外的子集;dist(si,s
′
l
)表示对象si和s
′
l
间的距离; dist(si,s
″
l
)表示对象si和s
″
l
间的距离;dist(si,sj)表示对象si和sj间的距离。
[0113]
对象si的k-邻域用nk(si)表示,该邻域包含数据集中所有与si的距离不大于k-距
离distk(si) 的对象,是一个集合:
[0114]
nk(si)={so|so∈s\{si},dist(si,so)≤distk(si)}
[0115]
式中,dist(si,so)表示对象si和so间的距离;distk(si)表示对象si的k-距离。
[0116]
对象si相对于对象so的可达距离用reach_distk(si,so)表示,计算公式如下:
[0117]
reach_distk(si,so)=max{dist(si,so),distk(si)}
[0118]
式中,dist(si,so)表示对象si和so间的距离;distk(si)表示对象si的k-距离。
[0119]
对象si的局部可达密度用lrd(si)表示,计算公式如下:
[0120][0121]
式中,|nk(si)|表示邻域所含元素的绝对值之和;reach_distk(si,so)表示对象si相对于对象so的可达距离。
[0122]
对象si的局部离群因子用lofk(si)表示:
[0123][0124]
式中,|nk(si)|表示邻域所含元素的绝对值之和;lrd(si)表示对象si的局部可达密度。
[0125]
对数据集s中每个数据对象重复上述步骤计算出局部离群因子,将这些值按照从大到小降序排列,将离群因子较大的z个数据对象视为数据集s的离群点集合。将采用四分位法和基于密度的离群点检测法识别出的异常值取并集作为最终的异常识别结果。
[0126]
某地区16个风电场各自的异常值识别结果具体如表1所示。可以明显看出共有4个风电场异常值为0,分别是6#风电场、10#风电场、11#风电场和12#风电场。同时,16#风电场的异常值个数最多。
[0127]
表1 16个风电场出力数据异常识别结果
[0128][0129]
步骤(2)基于卡尔曼滤波获取异常数据初步校正结果,所述的基于卡尔曼滤波的异常数据初步校正法为:
[0130]
2.1卡尔曼滤波算法中的状态方程和量测方程分别为:
[0131]
xk=fkx
k-1
+ωk[0132]
yk=hkxk+vk[0133]
式中,xk为未知过程在k时刻的状态向量;yk为k时刻的观测向量;fk为k时刻的状态转移矩阵;hk为k时刻的输出转移矩阵;ωk和vk分别为k时刻系统噪声向量和量测噪声向量,均假定满足高斯白噪声且相互独立。
[0134]
2.2假定当前时刻为k时刻,则现有系统状态为xk,则在上一时刻状态x
k-1
及其协方差矩阵p
k-1
的基础上,可以得到k时刻的预测状态向量x
k|(k-1)
及相应协方差矩阵p
k|(k-1)
:
[0135]
x
k|(k-1)
=fkx
k-1
[0136][0137]
式中,t表示转置;wk为k时刻系统噪声向量ωk对应的协方差矩阵;fk为k时刻的状态转移矩阵。
[0138]
2.3当新的观测向量yk更新后,可以得到k时刻的状态向量的最优估计值xk,即:
[0139]
xk=x
k|(k-1)
+kk(y
k-hkx
k|(k-1)
)
[0140]
式中,x
k|(k-1)
为k时刻的预测状态向量;hk为k时刻的输出转移矩阵;kk为卡尔曼滤波增益,其计算公式如下:
[0141][0142]
式中,t表示转置;p
k|(k-1)
为k时刻预测状态向量相应的协方差矩阵;vk为k时刻量测噪声向量vk对应的协方差矩阵;hk为k时刻的输出转移矩阵。
[0143]
2.4更新k时刻系统状态的协方差矩阵,并作为算法递归运行的条件,更新公式如下:
[0144]
pk=(i-k
khk
)p
k|(k-1)
[0145]
式中,i为单位矩阵;hk为k时刻的输出转移矩阵;p
k|(k-1)
为k时刻预测状态向量相应的协方差矩阵;p
k|(k-1)
为k时刻预测状态向量相应的协方差矩阵。
[0146]
将所得状态向量的最优估计值xk和更新后相应的协方差矩阵pk输入步骤2.2,进行下一时刻的估计。
[0147]
步骤(3)、基于互信息计算任意两个新能源电站出力数据间的空间相关性,并按照降序排列,互信息计算公式如下:
[0148][0149]
式中,xi和xj分别指第i个和第j个新能源电站出力数据,n是新能源电站总个数。
[0150]
步骤(4)、逐一为各新能源电站选取与之互信息最大的其余k个电站,并以互信息的归一化值为权重系数,求出k个相关电站出力的加权和,作为异常值二次校正结果,本发明中 k取3。
[0151]
假设第m个新能源电站所选相关电站集为则其中第l 个相关电站对应的权重系数计算公式如下:
[0152][0153]
式中,代表第m个新能源电站与第q个相关电站出力数据间的互信息值, q=1,2,...,k。
[0154]
则这k个相关电站出力的加权和即异常值二次校正结果为:
[0155][0156]
步骤(5)、从二次校正序列中取出与待校正电站异常数据相同位置的值,与一次校正结果求取平均值,作为最终的异常数据校正结果。
[0157]
本发明引入互信息对风电场出力间的空间相关性进行分析,16个风电场两两出力间的互信息具体如表2所示:
[0158]
表2某地区16个风电场出力间互信息
[0159]
[0160][0161]
从表2可以看出,16个风电场出力间均存在一定的相关系数,说明这些风电场的出力间存在不同程度的空间相关性。这是因为风电场出力主要取决于风速变化,处于同一区域的风电场易受同一阵风影响,产生一致的风电出力变化趋势,表现出显著的空间相关性。以该地区1#风电场为例,从表2可以看出与之最相关的3个风电场分别为风电场14、风电场3和风电场15,其与1号风电场出力间的互信息均在0.7左右,选取这三个风电场用于对处理异常值进行二次校正。
[0162]
图2为1#风电场基于四分位法和离群点检测法的异常识别结果。图中圆点代表检测出的异常点,可以看出风电场出力异常值主要集中在局部峰值处。图3为1#风电场采用计及空间相关性的异常数据校正方法的结果。虚线代表风电场出力真实值曲线,实线代表风电场出力校正值曲线,将异常值所在位置用标记表示,星型标记表示异常数据的原始值,圆形标记表示异常数据的校正值,可以看出局部峰值处的异常值得到了修正。
[0163]
综上所述,本发明所提方法可以实现新能源出力异常值识别和校正。基于四分位法和离群点检测的组合异常识别法,可以更全面地识别出多种类型的异常值。考虑了空间相关性的数据异常校正方法,基于互信息衡量不同新能源电站出力间的空间相关程度,将相关电站出力值的加权和引入异常数据校正过程,使得异常数据校正值更加符合电站所处位置的历史自然条件,更加贴合真实的风电出力数据。可为新能源出力预测提供高质量的出力数据,有利于内部特征提取,从而提高预测精度,同时,也能更准确地掌握新能源出力特性,有利于采取相应的稳定控制措施,减少新能源大规模并网对系统造成的冲击,进而提高新能源消纳水平。
[0164]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1