一种基于两阶段自愈网络的表情识别系统及方法
1.本发明涉及图像识别处理技术领域,尤其涉及一种基于两阶段自愈网络的表情识别系统及方法。
背景技术:
2.表情识别是指研究一个自动、高效、准确的系统来识别人脸表情的状态,进而通过人脸表情信息了解人的情绪状态,比如高兴、悲伤、惊讶、恐惧、厌恶和愤怒等。表情识别开始应用于许多领域中,该研究在人机交互、医疗科学,商品评价等方面有着重要的应用价值,是当前计算机视觉、模式识别、情感计算等领域的重要研究课题。
3.在需要进行人机交互的表情识别技术领域,通常需要能够对人的情感进行准确分析,以进行有效的人机交互,为用户的交互体验带来感官上的改善,但现有的人机交互技术缺乏有效的情感分析手段,因此人机交互技术需要一种更加实用的技术手段。在现有的许多面部表情识别数据集中都存在标注不一致或者是标签错误的情况,其原因可能是标签注释者的主观性或者是图片本身的模糊性,给大规模的面部表情进行注释是非常困难的;不仅如此,目前的面部表情识别在因性别不同而引起的表情差异方面存在局限性,没有利用不同性别在展现相同表情时的差异,心理学研究发现,不同性别的人在表达方式上存在差异,比如男性倾向于通过嘴区域表达他们的情绪,而女性更多的是通过眼部来传达她们的感情。表情识别技术能够从一幅图像中提取出人脸部分并识别出人脸的表情,将人脸的表情类型作为结果进行输出。作为一种算法,其应用远远滞后于研究,并没有在人机情感交互过程中表现其应有的应用价值。
4.目前,在一些户外场景下,进行表情识别的图像中往往人脸姿态多变、背景复杂(比如光照多变)。该场景下图像中不同表情类型的分布是极不平衡的。同时,因为人脸表情具有很强的主观性,一些表情类型也容易混淆,因此造成训练数据集标签错误而引发模型预测不准确。不仅如此,目前的面部表情识别在因性别不同而引起的表情差异方面存在局限性。
技术实现要素:
5.针对现有技术的不足,本发明提供了一种基于两阶段自愈网络的表情识别系统及方法。
6.一种基于两阶段自愈网络的表情识别系统包括输入模块、输出模块、预处理模块、训练模块;
7.所述输入模块用于获取待识别人脸图像,输出人脸中间图像数据标准化的待识别人脸样本图像到预处理模块;
8.所述预处理模块通过表情识别模型从待识别人脸图像中提取出人脸特征,所述人脸特征为模型算法识别的数字矩阵,输出预处理后的表情识别模型到训练模块;
9.其中,所述表情识别模型是通过使用多个人脸样本图像进行深度学习训练,并在
训练过程中调整所述表情识别模型的模型参数而获得的,所述表情识别模型的模型参数指向人脸样本图像中人脸各区域的权重值,每个人脸样本图像具有一种表情类型;
10.所述训练模块包括服务器;训练预处理后的表情识别模型,把训练后的表情识别模型输出到输出模块;
11.服务器包括处理器、存储介质和存储器;存储器中存储至少一段程序,该程序由处理器加载并执行以实现表情识别;存储器包括存储程序区和存储数据区;其中存储程序区存储功能所需的应用程序;存储数据区存储设备使用所创建的数据;所述存储介质中存储至少一段程序,该程序由处理器加载并执行以实现表情识别;
12.所述输出模块根据输入的人脸图像,通过训练模块输入的表情识别模型输出对应的表情与性别信息;
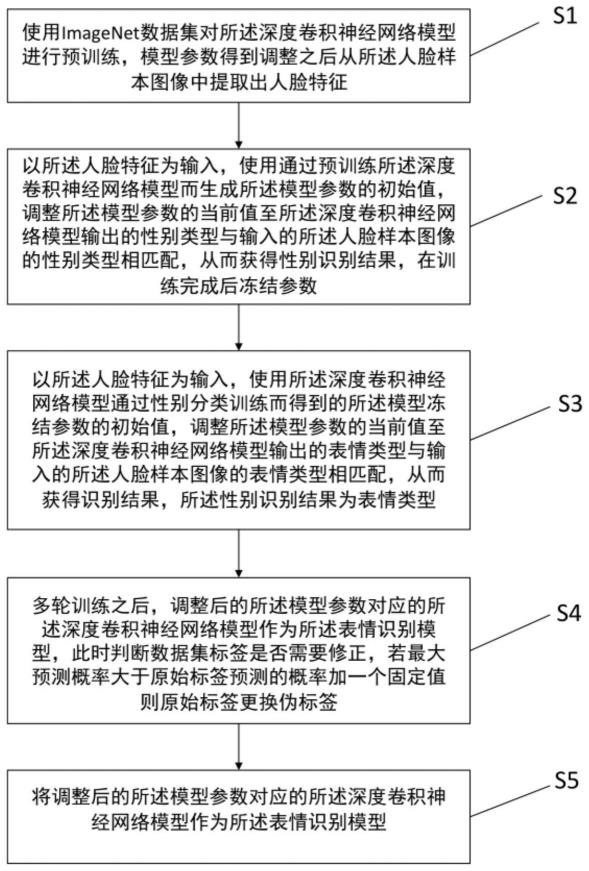
13.一种基于两阶段自愈网络的表情识别方法,通过一种基于两阶段自愈网络的表情识别系统实现,具体步骤如下:
14.步骤1:利用人脸检测器dilb对被识别人的图像的人脸进行锁定,获取只包含人脸的中间图像,对所述中间图像进行归一化处理使输入人脸中间图像数据标准化,得到待识别人脸样本图像;通过人脸识别算法即深度神经网络模型获取待识别人脸样本图像的人脸特征;
15.所述深度卷积神经网络模型为残差网络resnet18;所述人脸特征为在深度学习中,输入图片得到的一组输出的数据;
16.步骤2:使用imagenet数据集对深度神经网络模型进行预训练,得到深度神经网络模型神经元之间的权重参数的初始值;
17.步骤3:使用包含性别标签的公开表情数据集对深度神经网络模型进行训练,以步骤1获取的待识别人脸样本图像为输入,使用步骤2生成的深度神经网络模型参数的初始值,调整深度神经网络模型参数的当前值至深度卷积神经网络模型输出的性别类型与输入的待识别人脸样本图像的性别类型相匹配,从而获得性别识别结果;在训练完成后冻结深度神经网络模型中的模型参数的当前值;
18.表情数据集为深度学习中,训练识别模型的大量的表情图片,每张图片对应一个表情类型;表情类型指模型最后输出的表情结果;
19.步骤4:以步骤1得到的人脸特征为输入,对步骤3得到的冻结深度神经网络模型中的模型参数的当前值进行表情识别深度学习训练,通过调整所述冻结深度神经网络模型中的模型参数的当前值至深度卷积神经网络模型输出的表情类型与输入的人脸样本图像的表情类型相匹配,从而识别待识别人脸样本图像对应的表情类型;
20.步骤4.1:以步骤1得到的人脸特征为输入,使用人脸特征对深度卷积神经网络模型随机生成区域引导特征,所述区域引导特征指向待识别人脸样本图像中未遮挡的人脸区域和与影响表情变化的人脸区域;
21.步骤4.2:对区域引导特征进行归一化处理得到区域引导特征像素块的初始值;
22.步骤4.3:对所述区域引导特征像素块的初始值与冻结深度神经网络模型参数的当前值作点乘计算,得到区域引导表情特征;
23.步骤4.4:根据区域引导表情特征,计算深度卷积神经网络模型预测得到的目标值与人脸样本图像的实际标注值之间的损失值,根据损失值调整所述冻结深度神经网络模型
中的模型参数的当前值至深度卷积神经网络模型输出的表情类型和输入的人脸样本图像的表情类型相匹配,从而识别待识别人脸图像对应的表情类型;
24.其中,目标值是指深度卷积神经网络模型预测出来的表情类型;人脸样本图像的标注值指向所述人脸样本图像的表情类别;损失值是指目标值和标注值之间的差距;
25.根据损失值调整模型参数的步骤为:
26.步骤4.4.1:比较深度卷积神经网络模型预测到的目标值与实际标注值之间的损失值,通过反向传播计算使得损失值减小;
27.步骤4.4.2:通过交叉熵损失函数与softmax函数计算多个待识别人脸样本图像的损失值,并通过反向传播算法优化深度卷积神经网络模型,损失值具体为:
[0028][0029]
其中,n为样本的总个数,c为表情类别的总个数,μi为第i个样本分配到的注意力权重,xi为从每一张人脸样本图像所述提取的人脸特征,对应的yi为人脸样本图像的标注值,θ
t
为全连接层的参数,和为分类器参数,其中l遍历所有表情类型,e为自然常数,为第i个图片的输出值,从而得到某一类表情的概率;
[0030]
步骤5:经过步骤1到步骤4多轮训练之后,将调整参数后的深度卷积神经网络模型作为表情识别模型;此时判断数据集标签是否需要修正,若不需要修正则执行步骤7;数据集标签为人脸样本图像的实际标注值;
[0031]
判断是否需要修正:每个表情类型对应一个表情标签,在步骤4深度学习训练中,比较表情识别模型输出表情标签分配到的注意力权重的最高项与原数据集表情所分配的注意力权重,若表情标签分配到的注意力权重的最高项比表情原本标签所分配的注意力权重高出0.7则执行换标签操作并在下一轮训练中更改参数值,执行步骤5-6;如果表情标签分配权重的最高项比所述表情原本标签所分配权重小于等于0.7,则执行步骤7;
[0032]
所述表情标签分配权重为:
[0033]
γ
wr
=max{0,0.7-(μ
max-μ
min
)};
[0034][0035]
其中,μ
max
为高权重平均值,μ
min
低权重平均值,μi为第i个样本分配到的注意力权重,n为输入样本的总数,α为高权重占总数的比例,nα为高权重组的样本个数,(1-α)n为低权重组的样本个数,max函数通过比较数值大小从而输出最大值,γ
wr
则为权重正则化损失函数;
[0036]
步骤6:重新标记步骤5中低权重组的表情标签,生成一个伪标签,使其在下一轮迭代时获得更高的权重;标签的结果概率由深度卷积神经网络模型中的softmax函数执行,得到的结果达到最高概率的标签别作为预测类别,预测类别再与原始标签所对应的概率作比较,如果最高概率大于原始标签对应的概率加上一个固定值,则重新标记标签,所述计算预
测表情标签结果概率的公式为:
[0037][0038]
其中μi为第i个样本分配到的注意力权重,p
max
为表情预测中最大预测概率,xi为所述提取的人脸特征,θ
t
为全连接层的参数,为分类器参数,e为自然常数,c为表情类别的总个数,为第i个样本的输出值,argmax函数用来寻找具有最大评分的参量;
[0039]
步骤7:将调整深度卷积神经网络模型参数后对应的深度卷积神经网络模型作为表情识别模型,将待识别人脸图像输入到表情识别模型,输出表情类型与性别信息;所述softmax函数预测得到最大概率的表情标签输出为表情识别结果。
[0040]
本发明具有如下技术效果:
[0041]
一种基于两阶段自愈网络的表情识别系统及方法,能够得到具有高泛化能力的表情识别模型,在进行表情识别处理时修改原本数据集中错误的标签从而提高对待识别人脸图像的表情识别适应能力,进而大大提高对图像中表情的识别准确率。解决现有技术应用在对人脸姿势多变、背景复杂、有遮挡的图像作表情识别时准确率低等问题。采用两阶段自愈网络模型训练得到表情识别模型,在利用表情识别模型进行表情识别时修改数据集中错误的标签从而提高对户外场景下表情的识别适应能力,进而大大提高表情识别的可靠性和有效性。
附图说明
[0042]
图1是本发明实施例提供的一种表情识别方法的流程示意图;
[0043]
图2是应用本发明实施例输出待识别人脸图像对应的表情类型的示意图;
[0044]
图3是本发明实施例提供的深度卷积神经网络模型中的流程示意图;
[0045]
图4是本发明实施例提供的一种基于两阶段自愈网络的表情识别系统应用场景示意图;
[0046]
图5是本发明实施例提供的一种基于两阶段自愈网络的表情识别模型的算法流程图;
[0047]
图6是本发明实施例提供的一种服务器的结构示意图。
具体实施方式
[0048]
下面结合附图和实施例对本发明做进一步说明,一种基于两阶段自愈网络的表情识别系统及方法。
[0049]
一种基于两阶段自愈网络的表情识别系统包括输入模块、输出模块、预处理模块、训练模块;
[0050]
所述输入模块用于获取待识别人脸图像,输出人脸中间图像数据标准化的待识别人脸样本图像到预处理模块;
[0051]
所述预处理模块通过表情识别模型从待识别人脸图像中提取出人脸特征,所述人脸特征为模型算法识别的数字矩阵,输出预处理后的表情识别模型到训练模块;
[0052]
其中,所述表情识别模型是通过使用多个人脸样本图像进行深度学习训练,并在训练过程中调整所述表情识别模型的模型参数而获得的,所述表情识别模型的模型参数指向人脸样本图像中人脸各区域的权重值,每个人脸样本图像具有一种表情类型;
[0053]
所述训练模块包括服务器;服务器的结构示意图如图6所示;训练预处理后的表情识别模型,把训练后的表情识别模型输出到输出模块;
[0054]
服务器包括处理器、存储介质和存储器;存储器中存储至少一段程序,该程序由处理器加载并执行以实现表情识别;存储器包括存储程序区和存储数据区;其中存储程序区存储功能所需的应用程序;存储数据区存储设备使用所创建的数据;所述存储介质中存储至少一段程序,该程序由处理器加载并执行以实现表情识别;
[0055]
存储介质为一种计算机可读存储介质是硬盘或光盘等。
[0056]
服务器外接电源630和输入样本数据集610,数据存储在存储介质6214中,存储介质6214包括多个模块,每个模块包括对服务器中的一系列指令操作。处理器621设置为与存储介质6214通信,在服务器620上执行存储介质6214中的一系列指令操作。服务器620还能包括有线或无线网络接口622,输入输出接口623,操作系统6211,例如windows servertm,mac os xtm,unixtm,linuxtm等。
[0057]
所述输出模块根据输入的人脸图像,通过训练模块输入的表情识别模型输出对应的表情与性别信息;
[0058]
一种基于两阶段自愈网络的表情识别方法,通过一种基于两阶段自愈网络的表情识别系统实现,一种表情识别方法的流程示意图如图1所示,具体步骤如下:
[0059]
步骤1:利用人脸检测器dilb对被识别人的图像的人脸进行锁定,获取只包含人脸的中间图像,对所述中间图像进行归一化处理使输入人脸中间图像数据标准化,将表情图像都裁剪为224*224像素,得到待识别人脸样本图像;通过人脸识别算法即深度神经网络模型获取待识别人脸样本图像的人脸特征;
[0060]
所述人脸特征为在深度学习中,输入图片得到的一组输出的数据。
[0061]
在实际应用中,一般社交场景下会定义的7种表情类型包括高兴、自然、难过、惊讶、厌恶、生气和害怕。而在现实生活场景下,害怕和厌恶这类表情很少出现。同时,因为对表情类型的判断也存在一定的主观性,不同标注者对一些表情类型也可能存在不同的理解,从而造成表情数据集的标签错误。
[0062]
户外场景下,表情识别系统(包括比如摄像头)可以用于拍摄户外中有关人员的图像或视频,表情识别系统也可以接收来自外部设备(比如蓝牙)发送的图像或视频。待识别人脸图像可以是静态图片或者动态图片。摄像头拍摄的内容通常为视频,那么待识别人脸图像则可以是从视频中截取的图片。
[0063]
对所述待识别图像进行人脸关键点检测,只获取包含人脸的中间图像,排除掉无关信息。
[0064]
待识别图像中通常除了人脸之外,还会包括其他的内容,例如衣服或者背景等,但是这些内容对于表情识别而言是毫无用处的,并且识别过程中所要处理的内容越多,反而还会使得识别速度较慢且造成识别困难,因此为了提高识别过程的效率,通过人脸检测(捕获),从拍摄的图像或者视频中筛选出包含人脸的中间图像。
[0065]
所述深度卷积神经网络模型中为残差网络resnet18,人脸样本图像输入
resnet18,通过resnet18提取出人脸特征。深度卷积神经网络模型中的流程示意图如图3所示;
[0066]
图5是本发明实施例提供的一种表情识别方法的算法流程示意图;
[0067]
步骤2:使用imagenet数据集对深度神经网络模型进行预训练,得到深度神经网络模型神经元之间的权重参数的初始值;
[0068]
imagenet是一项持续的研究工作,旨在为世界各地的研究人员提供易于访问的图像数据库。目前imagenet中总共有14197122幅图像,总共分为21841个类别(synsets)。
[0069]
步骤3:使用包含性别标签的公开表情数据集对深度神经网络模型进行训练,以步骤1获取的待识别人脸样本图像为输入,使用步骤2生成的深度神经网络模型参数的初始值,调整深度神经网络模型参数的当前值至深度卷积神经网络模型输出的性别类型与输入的待识别人脸样本图像的性别类型相匹配,从而获得性别识别结果;在训练完成后冻结深度神经网络模型中的模型参数的当前值;
[0070]
表情数据集为深度学习中,训练识别模型的大量的表情图片每张图片对应一个表情类型,表情类型指模型最后输出的结果,比如愤怒,高兴。
[0071]
步骤4:以步骤1得到的人脸特征为输入,对步骤3得到的冻结深度神经网络模型中的模型参数的当前值进行表情识别深度学习训练,通过调整所述冻结深度神经网络模型中的模型参数的当前值至深度卷积神经网络模型输出的表情类型与输入的人脸样本图像的表情类型相匹配,从而识别待识别人脸样本图像对应的表情类型;
[0072]
步骤4.1:以步骤1得到的人脸特征为输入,使用人脸特征对深度卷积神经网络模型随机生成区域引导特征,所述区域引导特征指向待识别人脸样本图像中未遮挡的人脸区域和与影响表情变化的人脸区域;
[0073]
步骤4.2:对区域引导特征进行归一化处理得到区域引导特征像素块的初始值;
[0074]
步骤4.3:对所述区域引导特征像素块的初始值与冻结深度神经网络模型参数的当前值作点乘计算,得到区域引导表情特征;
[0075]
步骤4.4:根据区域引导表情特征,计算深度卷积神经网络模型预测得到的目标值与人脸样本图像的实际标注值之间的损失值,根据损失值调整所述冻结深度神经网络模型中的模型参数的当前值至深度卷积神经网络模型输出的表情类型和输入的人脸样本图像的表情类型相匹配,从而识别待识别人脸图像对应的表情类型;
[0076]
其中,目标值是指深度卷积神经网络模型预测出来的表情类型;人脸样本图像的标注值指向所述人脸样本图像的表情类别;损失值是指目标值和标注值之间的差距;
[0077]
根据损失值调整模型参数的步骤为:
[0078]
首先,对于所述人脸样本图像,由所述深度卷积神经网络模型得到的目标值(训练结果),可以与所述人脸样本图像的标注值(正确答案)存在差异(损失值)。然后,根据目标损失值利用反向传播算法优化所述深度卷积神经网络模型。采用梯度下降法对所述深度卷积神经网络模型进行训练,设置学习率的初始值为0.0004,学习率的初始值为0.1,每隔2000次将所述学习率降低0.1。
[0079]
步骤4.4.1:比较深度卷积神经网络模型预测到的目标值与实际标注值之间的损失值,通过反向传播计算使得损失值减小;
[0080]
步骤4.4.2:通过交叉熵函数与softmax函数计算多个待识别人脸样本图像的损失
值,并通过反向传播算法优化深度卷积神经网络模型,损失值具体为:
[0081][0082]
其中,n为样本的总个数,c为表情类别的总个数,μi为第i个样本分配到的注意力权重,xi为从每一张人脸样本图像所述提取的人脸特征,对应的yi为人脸样本图像的标注值,θ
t
为全连接层的参数,和为分类器参数,其中l遍历所有表情类型,e为自然常数,为第i个图片的输出值,从而得到某一类表情的概率;
[0083]
步骤5:经过步骤1到步骤4多轮训练之后,将调整参数后的深度卷积神经网络模型作为表情识别模型;一种基于两阶段自愈网络的表情识别模型的算法流程图如图5所示;此时判断数据集标签是否需要修正,若不需要修正则执行步骤7;数据集标签为人脸样本图像的实际标注值;
[0084]
判断是否需要修正:每个表情类型对应一个表情标签,在步骤4深度学习训练中,比较表情识别模型输出表情标签分配到的注意力权重的最高项与原数据集表情所分配的注意力权重,若表情标签分配到的注意力权重的最高项比表情原本标签所分配的注意力权重高出0.7则执行换标签操作并在下一轮训练中更改参数值,执行步骤5-6;如果表情标签分配权重的最高项比所述表情原本标签所分配权重小于等于0.7,则执行步骤7;
[0085]
所述表情标签分配权重为:
[0086]
γ
wr
=max{0,0.7-(μ
max-μ
min
)};
[0087][0088]
其中,μ
max
为高权重平均值,μ
min
低权重平均值,μi为第i个样本分配到的注意力权重,n为输入样本的总数,α为高权重占总数的比例,nα为高权重组的样本个数,(1-α)n为低权重组的样本个数,max函数通过比较数值大小从而输出最大值,γ
wr
则为权重正则化损失函数;
[0089]
步骤6:重新标记步骤5中低权重组的表情标签,生成一个伪标签,使其在下一轮迭代时获得更高的权重;标签的结果概率由深度卷积神经网络模型中的softmax函数执行,得到的结果达到最高概率的标签别作为预测类别,预测类别再与原始标签所对应的概率作比较,如果最高概率大于原始标签对应的概率加上一个固定值,则重新标记标签,所述计算预测表情标签结果概率的公式为:
[0090][0091]
其中μi为第i个样本分配到的注意力权重,p
max
为表情预测中最大预测概率,xi为所述提取的人脸特征,θ
t
为全连接层的参数,为分类器参数,e为自然常数,c为表情类别的
总个数,为第i个样本的输出值,argmax函数用来寻找具有最大评分的参量;
[0092]
步骤7:将调整深度卷积神经网络模型参数后对应的深度卷积神经网络模型作为表情识别模型,将待识别人脸图像输入到表情识别模型,输出表情类型与性别信息;所述softmax函数预测得到最大概率的表情标签输出为表情识别结果。应用本发明实施例输出待识别人脸图像对应的表情类型的示意图如图2所示;
[0093]
基于两阶段自愈网络的表情识别模型是通过使用大量开源表情数据集进行深度学习训练,并在训练过程中不断调整所述表情模型的参数,每个所述人脸样本图像只具有一种表情类型;
[0094]
一种基于两阶段自愈网络的表情识别系统应用场景示意图如图4所示。图片左侧中训练数据为人脸样本数据,每个所述人脸样本图像具有一种表情类型;
[0095]
相应的,最终训练出来的表情识别模型可以对待识别人脸图像进行准确的表情类型的识别。输入表情识别模型的是大小为224*224像素的待识别人脸图像,经所述表情识别模型输出的是开心的表情类型。
[0096]
如图4所示,展示所述表情识别模型输出识别人脸图像的识别结果,可以用于对顾客行为进行分析。顾客面部呈现的不同表情类型一定程度上反应了此刻顾客的内心感受,通过对识别表情可以更好的分析顾客对某类实体商品或虚拟服务的满意度,亦或者是在医疗上观测患者的情绪状态,从而判断恢复情况,精神状况。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1