一种变电站施工现场的三维重建方法及系统与流程
1.本发明涉及三维建模技术领域,尤其是一种变电站施工现场的三维重建方法及系统。
背景技术:
2.无人机巡检现在是变电站施工进度检查的可行选择,利用无人机和计算机视觉进行现场三维重构,并进行进度管理,可以降低成本、加快检查速度,方便管理人员进行决策判断。
3.变电站施工现场的精益管理最终目标是使用无人机捕获的图像,并运用算法生成施工现场所有建筑物高质量的三维模型。为了最大限度地提高模型的质量需要基于无人机拍摄的变电站现场视频,设计相应的三维重建算法来获取变电站现场高质量的三维模型。
4.其中处理重复的、交错形的条状结构,是现有三维重建算法的难点,目前该结构中提取的特征点容易产生误匹配,进而导致三维重建出的模型效果不好。
技术实现要素:
5.本发明提供了一种变电站施工现场的三维重建方法及系统,用于解决现有变电站施工现场的三维建模效果不好的问题。
6.为实现上述目的,本发明采用下述技术方案:
7.本发明第一方面提供了一种变电站施工现场的三维重建方法,所述方法包括以下步骤:
8.获取变电站施工现场的图像;
9.提取每帧图像的orb特征点,并根据训练好的词袋树模型提取图像中钢筋结构对应的多边形区域,剔除所述多边形区域内部的特征点,计算当前图像的特征表示;
10.对相邻的两帧图像进行特征匹配,根据配对的特征点定位两帧图像的拍摄相机,得到相机位姿;
11.构建关键帧集合,当所述关键帧集合中图像数量达到预设阈值时,对集合中关键帧的共视特征点进行局部光束平差法,优化相机位姿;
12.根据优化后的相机位姿,利用投射投影关系,将关键帧图像像素生成点云,将所述点云融合,形成变电站施工现场的三维模型。
13.进一步地,变电站施工现场图像的获取具体为:
14.将无人机拍摄的现场视频打散成单帧的图像。
15.进一步地,所述词袋树模型的训练具体为:
16.获取无人机拍摄的现场视频,将所述现场视频打散成单帧的图片;
17.设置训练配置,基于配置训练基于orb(oriented fast and rotated brief,特征提取算法)特征点的词袋树模型,训练过程中采用u-net网络进行图片训练,并对施工中的钢筋结构部分进行分割,得到对应的多边形区域。
18.进一步地,所述两帧图像的拍摄相机通过光束平差法进行定位。
19.进一步地,所述构建关键帧集合的过程具体为:
20.将第一帧图像加入所述关键帧集合,将后面每一帧图像的特征表示与第一帧的特征表示进行对比,并计算汉明距离,若所述汉明距离超过预设阈值,则当前图像作为候选帧,否则将当前图像加入关键帧集合;
21.计算所述候选帧的多边形区域面积,若多边形区域面积与当前图像面积的比值超过比值阈值,则当前候选帧不加入关键帧集合,否则将当前候选帧加入关键帧集合。
22.进一步地,所述方法还包括步骤:
23.当检测到回环后,对回环内的所有关键帧的共视特征点做全局光束平差法,优化相机位姿和共视特征点。
24.进一步地,所述将所述点云融合,形成变电站施工现场的三维模型的具体过程为:
25.将点云置于八叉树结构中,采用隐式函数表示法表示表面,对于同一体素网格下的点对应的隐式表面采用加权方式进行点云融合,得到变电站施工现场的三维模型。
26.本发明第二方面提供了一种变电站施工现场的三维重建系统,所述系统包括:
27.图像获取单元,用于获取变电站施工现场的图像;
28.图像处理单元,用于提取每帧图像的orb特征点,并根据训练好的词袋树模型提取图像中钢筋结构对应的多边形区域,剔除所述多边形区域内部的特征点,计算当前图像的特征表示;
29.定位单元,用于对相邻的两帧图像进行特征匹配,根据配对的特征点定位两帧图像的拍摄相机,得到相机位姿;
30.第一优化单元,用于构建关键帧集合,当所述关键帧集合中图像数量达到预设阈值时,对集合中关键帧的共视特征点进行局部光束平差法,优化相机位姿;
31.建模单元,根据优化后的相机位姿,利用投射投影关系,将关键帧图像像素生成点云,将所述点云融合,形成变电站施工现场的三维模型。
32.进一步地,所述系统还包括模型训练单元,所述模型训练单元获取无人机拍摄的现场视频,将所述现场视频打散成单帧的图片;基于预设配置训练基于orb特征点的词袋树模型,训练过程中采用u-net网络进行图片训练,并对施工中的钢筋结构部分进行分割,得到对应的多边形区域。
33.进一步地,所述系统还包括第二优化单元,所述第二优化单元在检测到回环后,对回环内的所有关键帧的共视特征点做全局光束平差法,优化相机位姿和共视特征点。
34.本发明第二方面的所述三维重建系统能够实现第一方面及第一方面的各实现方式中的方法,并取得相同的效果。
35.发明内容中提供的效果仅仅是实施例的效果,而不是发明所有的全部效果,上述技术方案中的一个技术方案具有如下优点或有益效果:
36.本发明基于深度神经网络训练词袋树模型,并将图像中钢筋等复杂交错的钢筋结构对应训练的多边形区域,剔除内部的特征点,进行图像的特征表示,便于图像特征的准确匹配,适用于变电站现场的三维重建方法,实现场景高精度三维重建。
附图说明
37.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
38.图1是本发明所述方法实施例的流程示意图;
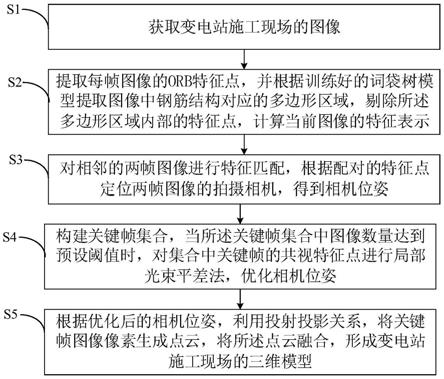
39.图2是本发明所述方法其一实现方式的流程示意图;
40.图3是本发明所述系统实施例的结构示意图。
具体实施方式
41.为能清楚说明本方案的技术特点,下面通过具体实施方式,并结合其附图,对本发明进行详细阐述。下文的公开提供了许多不同的实施例或例子用来实现本发明的不同结构。为了简化本发明的公开,下文中对特定例子的部件和设置进行描述。此外,本发明可以在不同例子中重复参考数字和/或字母。这种重复是为了简化和清楚的目的,其本身不指示所讨论各种实施例和/或设置之间的关系。应当注意,在附图中所图示的部件不一定按比例绘制。本发明省略了对公知组件和处理技术及工艺的描述以避免不必要地限制本发明。
42.如图1所示,本发明实施例提供了一种变电站施工现场的三维重建方法,所述方法包括以下步骤:
43.s1,获取变电站施工现场的图像;
44.s2,提取每帧图像的orb特征点,并根据训练好的词袋树模型提取图像中钢筋结构对应的多边形区域,剔除所述多边形区域内部的特征点,计算当前图像的特征表示;
45.s2,对相邻的两帧图像进行特征匹配,根据配对的特征点定位两帧图像的拍摄相机,得到相机位姿;
46.s4,构建关键帧集合,当所述关键帧集合中图像数量达到预设阈值时,对集合中关键帧的共视特征点进行局部光束平差法,优化相机位姿;
47.s5,根据优化后的相机位姿,利用投射投影关系,将关键帧图像像素生成点云,将所述点云融合,形成变电站施工现场的三维模型。
48.如图2所示,首选对词袋树模型进行训练,具体过程为:
49.收集变电站施工现场的无人机视频历史数据,将视频历史数据打散为一帧一帧的图片,采用6层、10分支的配置训练基于orb特征点的词袋树模型。其中收集的变电站施工现场图片中,包含重复的、交错形的条状结构,使用u-net网络对相关图片进行训练,对施工中的钢筋结构部分进行分割,获取其相应的多边形区域φ。
50.步骤s1中,获取无人机拍摄的现场视频,将视频打散成单帧的图像。
51.步骤s2中,对于每帧图像提取orb特征点,并使用训练出的网络提取多边形区域φ,剔除在多边形区域φ内部的特征点。基于词袋树的叶子节点,计算当前图像中剩余orb特征点与叶子节点的汉明距离,获得当前图像在词袋树模型中的特征表示。
52.步骤s3中,对前后两帧图像进行特征匹配,根据配对的特征点通过光束平差法对拍摄两幅图像的相机进行定位,获取相机位姿。
53.步骤s4中,所述构建关键帧集合的过程具体为:
54.将第一帧图像ψ加入所述关键帧集合,将后面每一帧图像的特征表示与第一帧的
特征表示进行对比,并计算汉明距离,若所述汉明距离超过预设阈值τ1,则当前图像作为候选帧k,否则将当前图像加入关键帧集合;
55.对于候选帧k,计算所述候选帧的多边形区域面积,若多边形区域面积与当前图像面积的比值超过比值阈值τ2,则当前候选帧不加入关键帧集合,否则将当前候选帧加入关键帧集合。避免重复的、交错形的条状结构对关键帧的影响。
56.关键帧集合中每更新20张,对关键帧集合中的20张关键帧的共视特征点做一次局部光束平差法优化相机位姿,以减小误差。
57.步骤s5中,将所述点云融合,对关键帧重叠的点云进行拼接,形成变电站施工现场的三维模型的具体过程为:
58.将点云置于八叉树结构中,采用隐式函数表示法表示表面,对于同一体素网格下的点对应的隐式表面采用加权方式进行点云融合,得到变电站施工现场的三维模型。
59.本发明实施例的其一实现方式中,所述方法还包括步骤:
60.当检测到回环后,对回环内的所有关键帧的共视特征点做全局光束平差法,优化相机位姿和共视特征点。
61.如图3所示,本发明实施例还提供了一种变电站施工现场的三维重建系统,所述系统包括图像获取单元1、图像处理单元2、定位单元3、第一优化单元4、地二优化单元5、建模单元6和模型训练单元7。
62.图像获取单元1用于获取变电站施工现场的图像;图像处理单元2用于提取每帧图像的orb特征点,并根据训练好的词袋树模型提取图像中钢筋结构对应的多边形区域,剔除所述多边形区域内部的特征点,计算当前图像的特征表示;定位单元3用于对相邻的两帧图像进行特征匹配,根据配对的特征点定位两帧图像的拍摄相机,得到相机位姿;第一优化单元2用于构建关键帧集合,当所述关键帧集合中图像数量达到预设阈值时,对集合中关键帧的共视特征点进行局部光束平差法,优化相机位姿;建模单元6根据优化后的相机位姿,利用投射投影关系,将关键帧图像像素生成点云,将所述点云融合,形成变电站施工现场的三维模型。
63.所述模型训练单元7获取无人机拍摄的现场视频,将所述现场视频打散成单帧的图片;基于预设配置训练基于orb特征点的词袋树模型,训练过程中采用u-net网络进行图片训练,并对施工中的钢筋结构部分进行分割,得到对应的多边形区域。
64.所述第二优化单元5在检测到回环后,对回环内的所有关键帧的共视特征点做全局光束平差法,优化相机位姿和共视特征点。
65.上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1