一种基于深度学习行为熵的抑郁症识别系统的制作方法
1.本发明利用深度学习定义的行为熵来表征抑郁度,具体涉及一种基于深度学习行为熵的抑郁症识别系统。
背景技术:
2.临床上对抑郁症的诊断主要通过患者健康问卷抑郁量表(the patient health questionnaire depression scores,qds)、汉密顿抑郁量表(hamilton depression scale,hamd)、抑郁自评量表(self-rating depression scale,sds)、焦虑自评量表(self-rating anxiety scale,sas)以及医生的问答进行综合判断.
3.一、汉密顿抑郁量表大部分项目采用0~4分的5级评分法。各级的标准为:i(0)无;(1)轻度;(2)中度;(3)重度;(4)极重度。少数项目采用0~2分的3级评分法,l其分级的标准为:i(0)无;(1)轻~中度;(2)重度。总分超过24分为严重抑郁,超过17分为轻或中度抑郁,小于7分无抑郁症状。
4.二、抑郁自评量表由20个项目组成,采用1-4分的四级评分法(没有或偶尔,有时,经常,总是如此),其中,第2、5、6、11、12、14、16、17、18和20等十项是为反向评分题,第1、3、4、7、8、9、10、13、15、19等十项是为正向评分题。评分指数在50以下者无抑郁;50-59为轻微至轻度抑郁;60-69为中至重度抑郁;70以上为重度抑郁。
5.三、焦虑自评量表与抑郁自评量表相仿,由20个条目组成,采用1-4分的四级评分法(没有或偶尔,有时,经常,总是如此),其中,第5、9、13、17和19等五项是为反向评分题,第1、2、3、4、6、7、8、10、11、12、14、15、16、18和20等十五项是为正向评分题。评分指数在50以下者无焦虑;50-59为轻微至轻度焦虑;60-69为中至重度焦虑;70以上为重度焦虑。
6.汉密顿抑郁量表由经过培训的两名评定者对患者进行汉密顿联合检查.一般采用交谈与观察的方式,检查结束后,两名评定者分别独立评分,在治疗前后进行评分,可以评价病情的严重程度及治疗效果。这种方法对评定者的要求比较高,他们需要经过严格培训,而且容易出现患者的细节情绪观察不到位以及抑郁程度判断不均衡等情况。
技术实现要素:
7.针对现有技术存在的不足,本发明的目的在于提供一种基于深度学习行为熵的抑郁症识别系统。
8.为实现上述目的,本发明提供了如下技术方案:
9.一种基于深度学习行为熵的抑郁症识别系统,其包括:
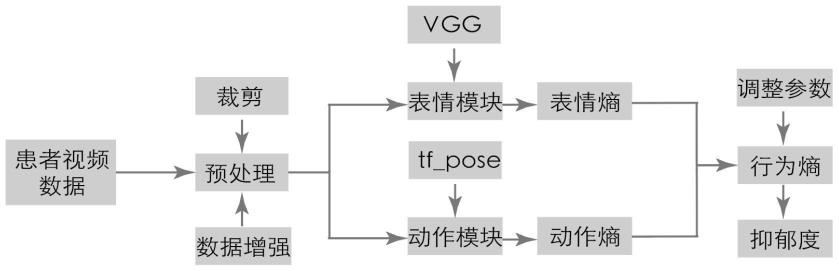
10.至少一个影像数据获取单元,用于识别待测者的面部表情及肢体动作;
11.表情模块,根据影像数据获取单元获取的面部表情,提取待测者的面部表情特征,并获得对应的七种表情出现的概率;
12.动作模块,根据影像数据获取单元获取的肢体动作,提取待测者的在图像中的位点位置信息;
13.行为熵模型,根据表情模块及动作模块获取的信息,输出代表抑郁度的行为熵指标,
14.其构建方式如下:
15.首先,利用表情模块获得的七种表情出现的概率计算出表情熵
16.其中h(x)表示表情熵,p(xi)表示第i种表情出现的概率;
17.其次利用动作模块获取的待测者的位点位置信息,并通过相邻两幅图片的位置移动距离d,得到动作熵
18.其中g(y)表示动作熵,d(yj)表示第j个位点的位置移动距离,
19.最后利用λ线性拟合表情熵及动作熵,得到行为熵
20.f(x,y)=λh(x)+(1-λ)g(y),其中f(x,y)表示行为熵,λ表示配比参数。
21.所述影像数据获取单元包括用于对获取的视频进行分帧操作的图片提取模块。
22.所述影像数据获取单元还设有图像预处理模块。
23.所述图像预处理模块的工作步骤如下:
24.b1、对图片进行目标区域裁剪操作,获取人脸及人体区域数据;
25.b2、对b1中获取的输入数据进行数据增强;
26.b3、将增强后的人脸图像转换成灰度图像。
27.所述表情模块包括多个卷积子模块。
28.所述表情模块包括:
29.数据库,其用于输入数据集,并获取数据集的特征信息,其包括训练集、验证集及测试集;
30.学习模型,根据所述特征信息,调用设定的标准模型框架,对输入数据集进行无监督学习;
31.验证模型,利用验证集对学习模型进行进度验证;
32.输出模型,用于当所述学习模型的精度达到设定阈值时,输出该学习模型,并将所述学习模型与数据集的特征信息进行关联。
33.所述动作模型包括:
34.输入模块,用于输入用于识别的图形数据;
35.识别模型,通过建立的训练模型,对输入的图形数据进行人体识别,其中人体识别包括标志点定位及肢体识别;
36.动作解析模块,用于根据识别模型识别的信息,进行振幅及相邻图片的数据比对。
37.本发明的有益效果:通过获取待测者的面部表情及肢体动作,进而得到表情熵及动作熵,并获得代表抑郁度的行为熵,利用深度学习的方式提高行为熵的获取准确性,进而可以达到更高的抑郁度自动识别的效果,对医生提供诊断的参考。可以大大减少繁琐的患者抑郁症诊断的耗时,并且达到更优秀的抑郁症识别效果。省去了前期过多复杂的医学量
表以及医患访谈,节省诊疗时间,可以应用在精神医生欠缺的地方医院,有效提高诊断的准确性。
附图说明
38.图1为本发明的整体方案设计流程图。
39.图2为本发明的表情模块的流程图。
40.图3为本发明的动作模块的流程图。
41.图4为本发明的人体18个位点图。
42.图5为患者治疗前后七维表情状态变化示意图。
43.图6为患者治疗前后肢体动作幅度变化示意图。
44.图7为患者治疗过程中抑郁自评值变化示意图。
45.图8为患者治疗过程中,本系统的行为熵抑郁度变化示意图。
具体实施方式
46.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
47.需要说明,本发明实施例中所有方向性指示(诸如上、下、左、右、前、后
……
)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
48.在本发明中,除非另有明确的规定和限定,术语“连接”、“固定”等应做广义理解,例如,“固定”可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
49.本发明提供一种基于深度学习行为熵的抑郁症识别系统,其包括:
50.至少一个影像数据获取单元,用于识别待测者的面部表情及肢体动作,其采用摄像机或摄像头之类的,可以直接获取待测者一段时间内的视频影像数据;
51.所述影像数据获取单元包括用于对获取的视频进行分帧操作的图片提取模块。首先需要对获取的视频影像数据进行分帧操作并获取图片,因为视频影像数据中每秒钟包含60帧以上的图片,如果每一帧都提取出来将大大降低我们的处理效率。同时对于相邻两帧之间变化幅度不大,表情动作基本趋于一致。如果提取的两帧时间间隔过大,将丢失局部信息,因此,在本技术中,我们将提取的两帧之间的时间间隔设置为1秒。我们针对一次来访过程中的多段视频统一分帧成一次治疗数据。
52.同时所述影像数据获取单元还设有图像预处理模块。其包括人脸区域框选、人体区域框选、数据增强、灰度转换等。
53.所述图像预处理模块的工作步骤如下:
54.b1、对图片进行目标区域裁剪操作,获取人脸及人体区域数据,保证送入到表情和
动作模型只包含人脸和人体区域,避免模型对冗余信息的处理;
55.b2、对b1中获取的输入数据进行数据增强,数据增强方法可以采用随机剪裁、随机噪声、反转、扭曲、镜像等数据增强手段;
56.b3、将增强后的人脸图像转换成灰度图像。
57.表情模块,根据影像数据获取单元获取的面部表情,提取待测者的面部表情特征,并获得对应的七种表情出现的概率;表情模块也称为表情特征提取阶段,图2展示了表情模块的具体流程,该模块可以识别出患者面部七种表情的概率。它包含多个相同结构的卷积子模块:两次卷积操作加上一次池化操作。每进行一次卷积子模块,就会提取出图像中包含的一定信息,比如边界和颜色,卷积次数越多,就能抓取到图像的一些抽象特征,它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。
58.所述表情模块包括:
59.数据库,其用于输入数据集,并获取数据集的特征信息,其包括训练集、验证集及测试集;
60.学习模型,根据所述特征信息,调用设定的标准模型框架,对输入数据集进行无监督学习;
61.验证模型,利用验证集对学习模型进行进度验证;
62.输出模型,用于当所述学习模型的精度达到设定阈值时,输出该学习模型,并将所述学习模型与数据集的特征信息进行关联。
63.动作模块,根据影像数据获取单元获取的肢体动作,提取待测者的在图像中的位点位置信息;也称为肢体识别模块,图3展示了我们动作模块的具体流程,它的作用是识别人体各个位点在图像中额位置,并根据前后两次照片位点位置的变化信息计算出位点的移动距离。如图4所示,该模块输出每幅图片中人体的18个位点的位置信息,我们根据该位点变化信息计算动作特征。
64.所述动作模型包括:
65.输入模块,用于输入用于识别的图形数据;
66.识别模型,通过建立的训练模型,对输入的图形数据进行人体识别,其中人体识别包括标志点定位及肢体识别;
67.动作解析模块,用于根据识别模型识别的信息,进行振幅及相邻图片的数据比对。
68.行为熵模型,根据表情模块及动作模块获取的信息,输出代表抑郁度的行为熵指标,
69.其构建方式如下:
70.首先,利用表情模块获得的七种表情出现的概率计算出表情熵
71.其中h(x)表示表情熵,表示待测者的表情复杂度,该值越大说明该待测者的面部表情越丰富,p(xi)表示第i种表情出现的概率;
72.其次利用动作模块获取的待测者的位点位置信息,并通过相邻两幅图片的位置移动距离d,得到动作熵
73.其中g(y)表示动作熵,表示待测者肢体运动的复杂程度,d(yj)表示第j个位点的位置移动距离,
74.最后利用λ线性拟合表情熵及动作熵,得到行为熵
75.f(x,y)=λh(x)+(1-λ)g(y),其中f(x,y)表示行为熵,λ表示配比参数。在识别过程中,我们用皮尔森相似度确定配比参数λ的值。
76.具体实施例:
77.步骤一:数据预处理:
78.a.患者视频预处理:
79.进行深度学习前对图像进行简单的目标区域裁剪、亮度及对比度增强预处理过程。它的具体步骤如下:
80.a1.把患者视频进行分帧,一秒钟截取视频中的一幅图片。
81.a2.用人脸识别模型对图像中的人脸区域进行框选,处理成48*48的灰度图像输入。
82.a3.用肢体识别模型对人体区域进行框选,并进行数据增强处理。
83.上述步骤a1中,需要注意目标视频中有患者人体图像,如果出现噪声需要进行过滤。
84.上述步骤a2中,需要框选出不同光照、姿态下的人脸,然后进行灰度转换。我们使用的是基于tensorflow深度学习框架下的人脸识别方法。然后我们将图像进行几何归一化,通过双线内插值算法将图像统一重塑为48*48像素。
85.上述步骤a3中,扩增数据集可使用tensorflow深度学习框架中图像扩增函数来快速生成,包括旋转、反射变换、翻转变换、缩放变换、平移变换、尺度变换等。
86.b.行为特征的获取:
87.行为特征包括:表情特征和动作特征。获取行为特征的具体步骤如下:
88.b1.将上述a2过程中获得的48*48像素的图片输入到我们的表情模块,根据模型的输出,获取图像对应的七种表情的概率。
89.b2.将上述a3过程中获得的人体图片输入到我们的肢体识别模型,根据模型的输出,获取图像对应的18个位点的位置信息。
90.上述步骤b1在对图像进行人脸表情识别,卷积操作的参数为:激活函数为“relu”,填充方式为“same”,初始化权重的方法为“he_normal”;池化操作采用最大池化方案。同时我们为了防止模型过拟合,我们加入了两个丢弃层,丢弃系数为0.4。然后我们的模型输出到全连接层,最后输出愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性七种表情的概率。我们输出患者在治疗前后的表情特征,如图5所示,上方红色阴影面积代表患者的欢乐情绪,下方阴影面积表示患者的抑郁情绪。
91.上述步骤b2的特征提取结果如图6所示,我们使用肢体识别模型识别出目标人物的18个关节点,是基于tensorflow深度学习框架实现的人体姿态识别,他本身比较轻巧,可以利用cpu进行实时的检测。
92.纵坐标代表相应位点的位置移动距离,空值(如左踝)表示该位点在图像中不存
在。
93.步骤二:行为熵模型的构建:
94.行为熵模型主要分为两大部分表情模块(表情识别)和动作模块(肢体识别),它的优势是可以同时抓取表情和动作特征,并且网络可以自己去学习不同深度特征的重要性,具有很好的鲁棒性。
95.c.表情模块(表情识别):
96.表情模块也称为表情识别阶段,包含多个相同结构的卷积子模块:两次卷积操作加上一次池化操作。每进行一次卷积子模块,就会提取出图像中包含的一定信息,比如边界和颜色,卷积次数越多,就能抓取到图像的一些抽象特征,它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。最后把输出表情特征拟合成表情熵。
97.上述步骤c中,选取“adam(adaptive moment estimation)”作为优化器,损失函数选取二元分类器—“binary_crossentropy”,用准确度作为衡量指标。使用的数据集为fer2013和ck+数据库。
98.在长达3个小时的70个周期的训练后,表情模块在验证集上的准确率达到了97.2%。
99.d.动作模块(肢体识别):
100.动作模块也称为肢体识别模块,它的作用是识别患者的肢体运动情况。被识别图像送入模块后被识别出18个位点的位置信息,我们根据前后两幅图片位置信息的变化算出位移。最后拟合成动作熵输出。
101.上述步骤d中的硬件平台为geforce gtx 1080ti高能性显卡的服务器,选用tensorflow深度学习框架训练完成后对患者视频数据进行测试输出。
102.步骤三:行为熵参数优化
103.为了优化我们行为熵系统的准确性,我们用患者的抑郁自评表数据和我们的行为熵抑郁度做皮尔森相关性测试。本系统方案的预测结果与传统方案的结果如图7和图8所示。当配比参数λ取0.98时,行为熵能有效拟合患者医疗数据。皮尔森相关性达到了0.89。
104.同时我们对于病人的多处治疗数据做分析,能够判断出患者的治疗情况,为病人的预后做科学知道。我们根据行为熵的指标变化判断患者的病情改善情况。
105.实施例不应视为对本发明的限制,但任何基于本发明的精神所作的改进,都应在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1