一种基于FPGA的频域卷积代替时域互相关的加速方法与流程
一种基于fpga的频域卷积代替时域互相关的加速方法
技术领域
1.本发明涉及数字信号处理领域,具体涉及一种基于fpga的频域卷积代替时域互相关的加速算法。
背景技术:
2.互相关算法在下位机中很容易实现,但随着点数增多,计算效率大大降低。虽然在频域上做共轭卷积可以代替时域上的互相关计算,在点数较多时也能提高计算速度,但在涉及到频域取窗等问题时需要多次使用fft与ifft。在下位机上实现时,每一次fft与ifft都伴随着一定精度的损失,累加后可能会影响最终的结果。
3.现有技术中,cn108089839a公开了一种基于fpga实现互相关运算的方法,其有以下两个主要特征:1、利用fpga硬件资源丰富,易于实现并行计算的特点,采用硬件电路实现两路信号的互相关运算;2、该方法比传统的从fpga的ram地址取出单一数据进行乘累加运算具有更高的速度和效率,可以充分利用fpga并行运算的特点,降低运算时间。但上述方法需要大量的乘法运算,占用大量的乘法器资源,会造成系统较大的时延,效率较为低下。为此,急需一种能够节约乘法器资源并能优化时序的方法,提高算法的性能。
4.cn112597432 a公开了基于fft算法的复序列互相关在fpga上的加速实现方法及系统,将两组数组在时域上的互相关计算等效于其对应的频谱在频域上的共轭相乘。而后者在硬件上实现所需的计算量远远小于前者,因此可以大大优化在硬件上实现的性能。该方法在软件上可行,在硬件上的实现过程还需要改进。由于在其设计的数学公式h(t)=f1(t)*f2(-t),h(ω)=f1(ω)
×
conj(f2(ω))上,互相关运算对于没有信号的部分都默认进行了补零,因此在硬件上也要做出变化。
技术实现要素:
5.本发明的目的在于提供一种基于fpga的频域卷积代替时域互相关的加速算法,用以解决现有互相关的实现占用大量的乘法运算,造成系统较大的时延以及转换到硬件实现上不完全等效的问题。
6.为实现上述目的,本发明的技术方案为:
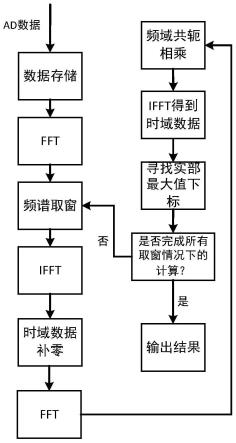
7.一种基于fpga的频域卷积代替时域互相关的加速方法,其特征在于,包括以下步骤:
8.(1).fft运算步骤:在fpga器件内利用fft算法分别将待互相关的两组信号数组从时域转换到频域,并保存;
9.(2).频域取窗步骤:根据实际需求对频域进行取窗,完成滤波的过程;
10.(3).ifft运算步骤:利用ifft算法将取窗后的频域数组转换到时域;
11.(4).时域序列补零步骤:在第一组时域数据前加上等数量的0,在第二组时域数据后加上等数量的0,以此来保证在硬件上实现时计算的正确性;
12.(5).fft运算步骤:利用fft算法将两组补零后的数组从时域转换到频域;
13.(6).共轭相乘步骤:对转换到频域的数组进行共轭相乘;
14.(7).ifft运算步骤:将共轭相乘后的频域数组转换到时域;
15.(8).寻找实部最大值步骤:找到数组中实部最大值的下标进行输出;
16.(9).重复步骤(2)-(8)的过程,直到得到所有需要取窗的结果后结束。
17.优选的,步骤(1)中,两组信号数组长度相等且为2的整数次幂。
18.优选的,步骤(2)中,取窗包括对于频域信号的低通滤波、高通滤波、带通滤波中的一种或多种。
19.本发明相对于现有技术,具有如下有益效果:
20.本发明相对于现有传统的直接时域开展相关运算来说,大大减少了乘法运算量,减少了逻辑资源的使用量,做到低延时、高效率,对fpga硬件来说,大大减少了对乘法器资源的占用,优化了fpga时序,节约了硬件资源,解决了现有互相关运算过程中乘法运算量过大的问题,能够让fpga系统的硬件发挥出最佳性能。
21.本发明相对于现有的fft算法的复序列互相关在fpga上的加速实现方法,不仅增加了在频谱上取窗的预处理环节,而且通过在原有数据上进行补零的方法,保证了在硬件上操作的正确性,从而真正实现了算法的准确移植。
22.本发明适用于所有需要使用硬件实现互相关计算的数据信号处理的场合,大大提升了系统的性能,使fpga既使用了更少的资源,还实现了更低的算法所需的时钟周期。
附图说明
23.图1本发明提出的加速方法流程示意图。
24.图2为时域序列补零步骤的具体实现示意图。
25.图3为fpga中部署的模块框图。
具体实施方式
26.以下实施例用于说明本发明,但不用来限制本发明的范围。
27.如图1所示,本实例所述的一种基于fpga的频域卷积代替时域互相关的加速方法,包括以下步骤:
28.fft运算步骤:利用fft算法分别将两组信号数组从时域转换到频域,并保存数据以便后面多次使用。
29.频域取窗步骤:根据实际的需求对频域进行取窗操作,完成滤波的过程。
30.ifft运算步骤:利用ifft算法将取窗后的频域数组转换到时域。
31.时域序列补零步骤:在第一组时域数据前加上等数量的0,在第二组时域数据后加上等数量的0,以此来保证在硬件上实现时计算的正确性。
32.fft运算步骤:利用fft算法将两组补零后的数组从时域转换到频域。
33.共轭相乘步骤:对转换到频域的数组进行共轭相乘。
34.ifft运算步骤:将共轭相乘后的频域数组转换到时域。
35.寻找实部最大值步骤:找到数组中实部最大值的下标进行输出。
36.重复频域取窗步骤至寻找实部最大值步骤的过程,直到得到所有需要取窗的结果后结束。
37.下面以具体实例对本发明的实现过程作具体说明。
38.假设a(n)与b(n)为采集到的两组ad数据,长度均为8192。
39.对两组数分别进行fft运算,得到a(n)与b(n)。假设取窗后保留数据为a[1],a[2],a[3],a[4],a[5],a[8187],a[8188],a[8189],a[8190],a[8191]与b[1],b[2],b[3],b[4],a[5],b[8187],b[8188],b[8189],b[8190],b[8191],,其余均置0。
[0040]
对取窗后的两组数进行ifft运算,得到的两组数记为c(n)与d(n),长度均为8192。
[0041]
对c(n)与d(n)进行补零,具体方法如图2所示,在第一组时域数据前加上等数量的0,在第二组时域数据后加上等数量的0,补零后得到的数组记为e(n)与f(n),长度均为16384。
[0042]
对数组e(n)与f(n)分别进行fft运算,得到e(n)与f(n)。
[0043]
将e(n)与f(n)对应的元素进行共轭相乘,得到g(n),长度为16384。
[0044]
对数组g(n)进行ifft运算,得到在时域的数组g(n),长度为16384。
[0045]
找出g(n)实部最大值所在的下标,并通过串口发送到上位机。
[0046]
重复上述过程的过程,直到得到所有需要取窗的结果后结束。
[0047]
以本实例为例,对于fft运算步骤、共轭相乘步骤、ifft运算步骤,如采用时域互相关的计算方法,需要的时间复杂度为o(n2),而采用本发明所用方法,需要的时间复杂度为o(n*logn),在n(本例中为8192)较大的情况下其效率提升是显而易见的。可见,本发明能够大大减少乘法运算次数,加快运算时间并减少资源的使用量,真正做到低延时、高效率。而且在多点数的情况下,相对于时域互相关更能体现出其算法优越性。
[0048]
以上列举的仅是本发明的具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1