一种考虑动态舆情主题的高影响力用户发现方法
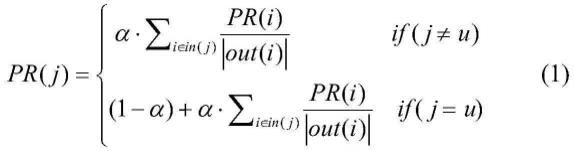
1.本发明涉及舆情中高影响力用户发现技术领域,具体涉及一种考虑动态舆情主题的高影响力用户发现方法。
背景技术:
2.随着社交媒体和移动应用的快速发展,如:百度贴吧、新浪微博、twitter、reddit等,在线社交媒体已经成为用户分享、发表观点、诉说诉求的重要工具,这些社交媒体有着惊人的速度、覆盖面和渗透力,民众所分享的信息被社交媒体广泛吸收,形成关于社会热点的各种舆情主题。
3.不同用户彼此间通过发帖、关注、转发等形式彼此影响,形成关于社会热点的各种舆情主题。舆情主题具有随着时间动态演变的特点,与此同时,在不同时期不同舆情主题中,用户之间的影响力存在差异,高影响力用户发表的内容对其他用户的影响更为显著。考虑动态舆情主题的高影响力用户发现能为政府决策提供重要信息,有助于政府及时了解民众不同时期所关心的热点话题及话题演变趋势,并通过高影响力用户进行更为有效的公众意见引导。
技术实现要素:
4.本发明为了克服现有技术存在的不足之处,提出了一种考虑动态舆情主题的高影响力用户发现方法,以期能有效探索不同时期下的舆情主题及每个舆情主题中的高影响力用户,有助于舆情主题发现和公众意见引导,从而为决策者提供重要信息,用于评估在过去特定时间内对于民众舆情引导效果,帮助决策者在不同方面引导公众意见。
5.本发明为达到上述发明目的,采用如下技术方案:
6.本发明一种考虑动态舆情主题的高影响力用户发现方法的特点是按如下步骤进行:
7.步骤1、构建不同时期的用户在线关系网络其中,g
t
表示第t个时期下的用户在线关系网络;t表示时期数;
8.步骤1.1、获取t个时期的u个用户分别发表的t
×u×nt,u
篇文档中的文本信息,并构成文本集合d,去除所述文本集合d中所有标点符号并进行分词操作后,再去除停用词和低频词,从而得到预处理后的包含t
×u×nt,u
篇文档的文本集合d';其中,预处理后的第t个时期第u个用户发表的n
t,u
篇文档记为篇文档记为表示第t个时期第u个用户发表的第nu篇文档,n
t,u
表示第t个时期第u个用户发表的文档数,将第nu篇文档中的词集合记为其中,表示第t个时期第u个用户发表的第nu篇文档中第m个单词,表示第t个时期第u个用户发表的第nu篇文档中的词个数;
9.步骤1.2、根据用户与文档之间的关系所构成的用户-文档二部图,采用随机游走方法获取第t个时期的用户在线关系网络g
t
;
10.步骤1.3、获取所述第t个时期的用户在线关系网络g
t
中与第u个用户最近邻的n个邻居用户;
11.步骤2、指定预处理后的文本集合d'中的主题个数为k;
12.步骤3、设计动态有参贝叶斯模型,并通过分析用户在不同时期的用户在线关系网络中的文本信息与用户链接信息,从而生成文本对应的舆情主题;
13.步骤3.1、初始化t=1;
14.步骤3.1.1、分别按照式(1)和式(2)生成第t时期下用户在线关系网络g
t
中背景主题词分布的超参数和第k个主题词分布的超参数
[0015][0016][0017]
式(1)中,β是狄利克雷分布的超参数,表示第t-1个时期属于背景主题的所有单词数量;
[0018]
式(2)中,表示第t-1个时期属于第k个主题的所有单词数量;k=1,2,3,
…
,k;
[0019]
步骤3.1.2、根据当前时期t下的u
t
个用户、预处理后的文本集合d
t
′
、用户间链接关系y
t
,利用有参贝叶斯模型生成如式(3)所示的第t时期下k个主题的背景主题词分布如式(4)所示的主题词分布如式(5)所示的用户的主题偏好分布
[0020][0021]
式(3)中,表示当前第t个时期下第v个单词在相应背景主题下所有词所占权重,v是预处理后的文本集合d
′
中所有不重复词的总数;
[0022][0023]
式(4)中,表示当前第t个时期下第v个单词在第k个主题下所有词所占比重;
[0024][0025]
式(5)中,表示当前第t个时期下第u个用户对第k个主题的关注度;
[0026]
步骤3.1.3、根据背景主题词分布及主题词分布利用式(6)得到第v个单词的主题分配情况
[0027][0028]
式(6)中,表示当前第t个时期下第v个单词与第k个主题的分配情况,表示
当前第t个时期下第v个单词与背景主题的分配情况,如果第k个主题或背景主题中出现第v个单词,则令或否则,令或
[0029]
步骤3.1.4、利用所有词的主题分配情况统计并更新第t个时期属于背景主题的所有单词数量及第t个时期属于第k个主题的所有单词数量
[0030]
步骤3.1.5、将t+1赋值给t后,判断t》t是否成立,若成立,则表示生成所有时期的主题词分布背景主题词分布用户的主题分布否则,返回步骤3.1.1顺序执行;
[0031]
步骤4、发现不同时期的高影响力用户:
[0032]
步骤4.1、将任意第t个时期下的u
t
个用户聚类为k个用户集合其中,表示当前第t个时期下分到第k个类别下的用户集合,并由当前第t个时期下对第k个主题最感兴趣的用户组成;
[0033]
步骤4.2、根据式(7)计算用户集合中第u个用户的度中心性
[0034][0035]
式(7)中,u
′
表示用户集合中除第u个用户以外的其他用户的序号,y
u,u
′
为一个二元指示变量,表示第u个用户与第u
′
个用户的链接情况,如果两用户存在链接,则令y
u,u
′
=1,否则,令y
u,u
′
=0;
[0036]
步骤4.3、根据第k个类别下的用户集合中所有成员的度中心性,选取当前第t个时期下分到第k个类别下的用户集合的度中心性最高的第max个用户为高影响力用户,的度中心性最高的第max个用户为高影响力用户,表示用户集合中用户的数量。
[0037]
与已有技术相比,本发明有益效果体现在:
[0038]
1、本发明考虑了舆情主题是动态演变的特点,结合不同时期下用户在线关系网络中的信息,生成不同时期下的舆情主题,并利用相邻时期的舆情主题作为后一时期舆情主题发现的先验信息,克服了现有技术中忽略舆情主题是动态演变、忽略不同时期舆情主题之间存在联系等问题,更加符合实际情况,能够更准确地发现不同时期的舆情主题,并探索舆情主题的演变趋势;
[0039]
2、本发明能够探索发现不同时期下不同舆情主题中的高影响力用户,考虑了舆情主题是动态演变的,认为不同时期下用户在不同舆情主题中的影响力是不同的,从而克服了现有技术中认为高影响力用户是固定不变的问题,能够发现决策者关注时期和舆情主题中的高影响力用户,帮助对特定时期中关注主题进行公众意见引导。
附图说明
[0040]
图1为本发明提出的动态有参贝叶斯模型图。
具体实施方式
[0041]
本实施例中,一种考虑用户在线关系网络的舆情主题发现方法是按如下步骤进行:
[0042]
步骤1、构建不同时期的用户在线关系网络其中,g
t
表示第t个时期下的用户在线关系网络;t表示时期数;
[0043]
步骤1.1、获取t个时期的u个用户分别发表的t
×u×nt,u
篇文档中的文本信息,并构成文本集合d,去除所述文本集合d中所有标点符号并进行分词操作后,再去除停用词和低频词,从而得到预处理后的包含t
×u×nt,u
篇文档的文本集合d';其中,预处理后的第t个时期第u个用户发表的n
t,u
篇文档记为篇文档记为表示第t个时期第u个用户发表的第nu篇文档,n
t,u
表示第t个时期第u个用户发表的文档数,将第nu篇文档中的词集合记为其中,表示第t个时期第u个用户发表的第nu篇文档中第m个单词,表示第t个时期第u个用户发表的第nu篇文档中的词个数;
[0044]
步骤1.2、根据用户与文档之间的关系所构成的用户-文档二部图,采用随机游走方法获取第t个时期的用户在线关系网络g
t
;
[0045][0046]
式(1)为随机游走方法,其中,pr(j)表示节点j的访问概率,pr(i)表示节点i的访问概率,in(j)代表所有指向节点j的节点集合,out(i)代表节点i指向的节点集合。u表示根节点即目标用户,α表示继续访问的概率,从u对应的节点开始在用户-帖子二部图上进行随机游走,游走到任何一个节点时,有概率α决定是否继续游走,有概率(1-α)停止本次游走并从u重新开始游走,经过多轮游走之后,每个用户-文档二部图中的每个节点被访问的概率收敛并趋于稳定,收敛后的pr(j)值为每个结点关于目标节点u的相关性,从而根据用户间的相关性,构建在线关系网络g
t
。
[0047]
步骤1.3、获取所述第t个时期的用户在线关系网络g
t
中与第u个用户最近邻的n个邻居用户;
[0048]
根据步骤1.2中收敛得到的pr(j)值,进行降序排列,获取前n个与用户最近邻的用户。
[0049]
例如:用户在经常在某个用户的帖子下发表内容时,证明两者越邻近。
[0050]
步骤2、指定预处理后的文本集合d'中的主题个数为k;
[0051]
步骤3、设计动态有参贝叶斯模型如图1所示,并通过分析用户在不同时期的用户在线关系网络中的文本信息与用户链接信息,从而生成文本对应的舆情主题;
[0052]
步骤3.1、初始化t=1;
[0053]
步骤3.1.1、分别按照式(1)和式(2)生成第t时期下背景主题词分布的超参数
和第k个主题词分布的超参数
[0054][0055][0056]
式(2)中,β是狄利克雷分布的超参数,表示第t-1个时期属于背景主题的所有单词数量;
[0057]
式(3)中,表示第t-1个时期属于第k个主题的所有单词数量;k=1,2,3,
…
,k;
[0058]
步骤3.1.2、根据当前时期t下的u
t
个用户、预处理后的文本集合d
t
′
、用户间链接关系y
t
,利用有参贝叶斯模型生成如式(4)所示的第t时期下k个主题的背景主题词分布如式(5)所示的主题词分布如式(6)所示的用户的主题偏好分布
[0059][0060]
式(4)中,表示当前第t个时期下第v个单词在相应背景主题下所有词所占权重,v是预处理后的文本集合d
′
中所有不重复词的总数;
[0061][0062]
式(5)中,表示当前第t个时期下第v个单词在第k个主题下所有词所占比重;
[0063][0064]
式(6)中,表示当前第t个时期下第u个用户对第k个主题的关注度;
[0065]
主题词分布和背景词分布的不同在于文档中选择词的不同原因,例如:社交网络中用户在讨论奥运会时,每个用户可能发表关于自乒乓球、羽毛球、篮球、田径不同组别的赛事的评论,每个组别都有自己的一组主题词分布。除了类似这些的特定主题词分布,其余词比如奥运会,冠军,比赛等词是一组通用的主题背景词分布生成的,由所有组共享。
[0066]
用户的主题偏好分布是由用户的兴趣决定的,例如:社交网络中用户在讨论奥运会时,对乒乓球感兴趣的用户发表内容中多涉及包含乒乓球主题。
[0067]
随着时期的变化,主题词分布、背景词分布、用户的主题偏好分布都在变化,例如:随着奥运会的举办,乒乓球主题词分布中占比较大的词可能由小组赛选手转变为决赛选手等;背景词分布中的占比较大词可能由开幕式、参赛人员等转变为闭幕式、金牌数等;用户的主题偏好分布也随着不同时期的兴趣转移产生变化。
[0068]
步骤3.1.3、根据背景主题词分布及主题词分布利用式(7)得到第v个单词的主题分配情况
[0069]
[0070]
式(7)中,表示当前第t个时期下第v个单词与第k个主题的分配情况,表示当前第t个时期下第v个单词与背景主题的分配情况,如果第k个主题或背景主题中出现第v个单词,则令或否则,令或
[0071]
步骤3.1.4、利用所有词的主题分配情况统计并更新第t个时期属于背景主题的所有单词数量及第t个时期属于第k个主题的所有单词数量
[0072]
步骤3.1.5、将t+1赋值给t后,判断t》t是否成立,若成立,则表示生成所有时期的主题词分布背景主题词分布用户的主题分布否则,返回步骤3.1.1顺序执行;
[0073]
步骤4、发现不同时期的高影响力用户:
[0074]
步骤4.1、将任意第t个时期下的u
t
个用户聚类为k个用户集合其中,表示当前第t个时期下分到第k个类别下的用户集合,并由当前第t个时期下对第k个主题最感兴趣的用户组成;
[0075]
步骤4.2、根据式(8)计算用户集合中第u个用户的度中心性
[0076][0077]
式(10)中,u
′
表示用户集合中除第u个用户以外的其他用户的序号,y
u,u
′
为一个二元指示变量,表示第u个用户与第u
′
个用户的链接情况,如果两用户存在链接,则令y
u,u
′
=1,否则,令y
u,u
′
=0;
[0078]
步骤4.3、根据第k个类别下的用户集合中所有成员的度中心性,选取当前第t个时期下分到第k个类别下的用户集合的度中心性最高的第max个用户为高影响力用户,的度中心性最高的第max个用户为高影响力用户,表示用户集合中用户的数量。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1