一种基于深度卷积神经网络的文本矫正方法
1.本发明属于视觉识别技术领域,涉及一种基于深度卷积神经网络的文本矫正方法。
背景技术:
2.随着网络技术和视频通讯的普及,越来越多的学生开始在网上学习,有些老师要求学生把课后作业拍照上传。学校的老师普遍采用网络教学,课后作业也一律拍照上传。但是,由于学生拍照的情况五花八门,比如手机水平、手机倾斜、书本旋转倾斜等,导致拍照的文本形态各异。原本是长方形的作业纸,被拍成了梯形、平行四边形等,老师在批改作业的时候,阅读比较困难。在此背景下,我们希望能够对学生的作业,进行检测和矫正,并进行增强,来方便老师阅读。
3.传统的计算机视觉算法,对直线的检测有很多。比如霍夫直线加测、lsd直线检测、canny lines直线检测等。这些算法,基本都是在边缘图像上进行直线检测的。常见的边缘检测算法算子如:canny算子、拉普拉斯算子。这些传统算法得到的边缘图像,在背景不是很理想的情况下,鲁棒性比较差。比如霍夫直线检测,在文本背景复杂的情况,会又很多误检测的直线;lsd只能检测长直线,文本(纸张)有时候会有卷边等非长直线的情况,会漏检;canny lines也是会发生卷边漏检的情况。综上所述,这些传统的算法只能在特定的场景下使用。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种基于深度卷积神经网络的文本矫正方法,从而能够解决传统计算机视觉解决不了的文本检测问题。
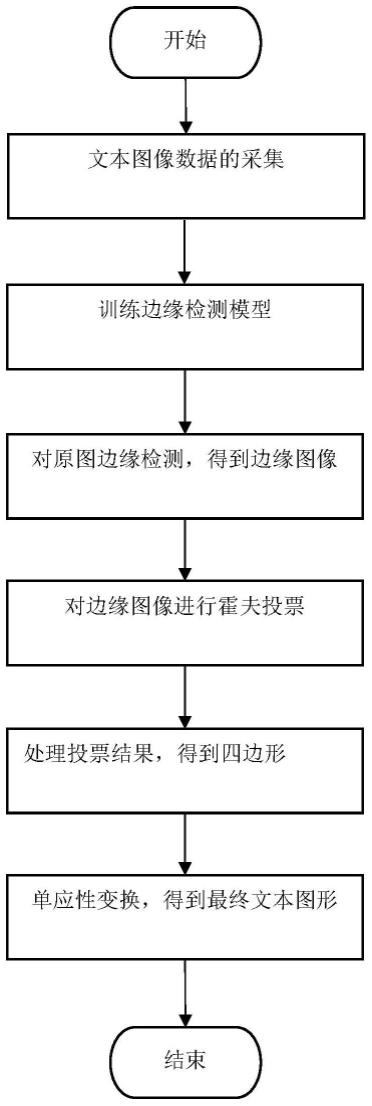
5.技术方案:本发明公开了一种基于深度卷积神经网络的文本矫正方法,其核心在于通过采集各种各样的文本图像,并对图像进行添加一些遮挡物,对预处理过的文本训练神经网络模型,得到边缘图像,进而对边缘图像进行霍夫投票算法的处理,得到合理的文本四条边。然后对这四条边进行单应性变换,即可得到矫正后的文本。具体包含以下步骤:
6.步骤1:采集文本图像数据,并对数据进行预处理;
7.步骤2:构建神经网络模型,并使用采集的数据进行训练;
8.步骤3:训练完成后,将原图像输入网络模型,得到边缘图像;
9.步骤4:对步骤3得到的边缘图像,进行霍夫投票;
10.步骤5:处理步骤4中的霍夫投票结果,得到四边形;
11.步骤6:根据将步骤5中的四边形的四个角点,对原图像进行单应性变换,得到矫正后的文本。
12.进一步地,步骤1包轮数据采集与处理步骤,包括如下步骤:
13.在网络上爬取相应的文本图片,并对爬取到的图片进行筛选,去除其中与文本不对应的图片,并准备桌面物品作为文本图片的噪声,以随机的位置,和文本图片进行结合;
14.步骤1-1,从全部文本图像中,选取部分图像,随机地添加些遮挡物,如鼠标、数据线、笔等常见的桌面物品,对原图中的文本进行随机部位的遮挡;
15.步骤1-2,将经过步骤2-1后的数据集中的图像,缩放成256*256;
16.步骤1-3,对256*256的图像做归一化处理。
17.进一步地,步骤2包括神经网络模型的训练步骤,包括如下步骤:
18.步骤2-1,构造神经网络模型;
19.步骤2-2,初始化神经网络模型,采用预训练好的网络参数;
20.步骤2-3,用步骤2中预处理后的正方形图像数据对神经网络模型进行训练,并保存训练好的模型。
21.步骤2-1中神经网络模型具体内容如下:该模型采用rcf,基于vgg 16网络架构,该模型包含五个层级的特征提取架构,具体结构为:输入为大小为256*256*3的图像;第1层级为包括2个卷积层,卷积核的大小是3*3,卷积核的数量是64;第2层级为包括2个卷积层,卷积核的大小是3*3,卷积核的数量是128;第3层级为包括3个卷积层,卷积核的大小是3*3,卷积核的数量是256;第4层级为包括3个卷积层,卷积核的大小是3*3,卷积核的数量是512;第5层级为包括3个卷积层,卷积核的大小是3*3,卷积核的数量是512。每个层级的卷积层,连接一个卷积层,卷积核的大小是 1*1,卷积核的数量为21。对于每一层级,将所有的1*1卷积的结果,再连接一个的卷积,卷积核的大小是1*1,卷积核的数量为1,然后再进行一次反卷积,到原始图片的大小,作为该层级的中间输出。最后将5个层级的所有中间输出,进行concat操作,对该结果进行最后一个卷积操作,卷积核的大小是1*1,卷积核的数量为1,得到最终结果。
22.进一步地,步骤4中的霍夫投票步骤,具体包括:
23.步骤4-1,建立参数空间。霍夫投票的关键是建立参数空间,即霍夫空间。直线在极坐标系下,由参数θ和参数ρ共同决定。参数θ的范围为(0,π),均分为m个单元,参数ρ的范围为(-l,l)均分为n个单元参数空间一共 m*n个单元,其中l为图片对角线的长度;
24.步骤4-2,建立一个同等大小m*n的投票表格,将之前得到的边缘图像,提取出其中的边缘像素点,可以提取的像素点的个数记为s,对每一个像素点,求其在霍夫空间的m个离散点;
25.步骤4-3,收集所有的边缘像素点对应的所有的霍夫空间的离散点,一共有 s*m个。将所有的这些离散点进行在投票表中进行投票,得票数较多的即可作为候选直线。
26.进一步地,步骤5中,将步骤4中得到的投票结果进行处理。具体包括:
27.步骤5-1,将上述得票较多的候选直线,使用聚类的方法,根据θ和ρ,分成4大类直线簇;
28.步骤5-2,对每个直线簇linesi,选出得票数最多的那条直线topi;
29.步骤5-3,对每个直线簇linesi,继续搜寻可能的候选直线,但这些直线的得票数必须达到一定的阈值。此处,设定每一类的候选直线不能超过3条。
30.进一步地,步骤6中,根据将步骤5中的四边形轮廓的四个角点,对角点坐标进行还原,得到在原图中的4个坐标点。根据4对坐标点,对原图像进行单应性变换,得到矫正后的文本。
31.本发明的有益效果在于:
32.1)本发明的方法解决了传统计算机视觉解决不了的文本检测问题,降低了文本检测的错误率。尤其是边缘的检测这一部分,可以有效过滤掉文本边缘之外的“伪边缘”。
33.2)通过采集各种各样的文本图像,并对图像进行添加一些遮挡物,进行标注训练,从而能够增强文本的边缘识别准确度,使算法更加鲁棒。
34.3)本算法采取了霍夫投票的算法,进行直线的检测,解决了因长直线不连续导致的直线检测置信度不高的问题,增强了对间断的直线的检测效果。
附图说明
35.下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
36.图1为基于深度卷积神经网络的文本矫正方法的流程图;
37.图2为本发明中使用的rcf神经网络的示意图;
38.图3从左至右依次为原图、边缘检测的灰度图、文本的检测边界、矫正后的文本。
具体实施方式
39.下面结合附图及实施例对本发明做进一步说明。
40.下面将结合本发明实施例的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,均属于本发明的保护范围。
41.实施例1
42.本发明公开了一种基于深度卷积神经网络的文本矫正方法,其核心在于通过采集各种各样的文本图像,并对图像进行添加一些遮挡物,对预处理过的文本训练神经网络模型,得到边缘图像,进而对边缘图像进行霍夫投票算法的处理,得到合理的文本四条边。然后对这四条边进行单应性变换,即可得到矫正后的文本。
43.具体包含以下步骤:
44.步骤1:采集文本图像数据,并对数据进行预处理;
45.步骤2:构建神经网络模型,并使用采集的数据进行训练;
46.步骤3:训练完成后,将原图像输入网络模型,得到边缘图像;
47.步骤4:对步骤3得到的边缘图像,进行霍夫投票;
48.步骤5:处理步骤4中的霍夫投票结果,得到四边形;
49.步骤6:根据将步骤5中的四边形的四个角点,对原图像进行单应性变换,得到矫正后的文本。
50.其中,步骤1数据采集与处理,包括如下步骤:
51.步骤1-1,从全部文本图像中,选取部分图像,随机地添加些遮挡物,如鼠标、数据线、笔等常见的桌面物品,对原图中的文本进行随机部位的遮挡;
52.步骤1-2,将经过步骤2-1后的数据集中的图像,缩放成256*256;
53.步骤1-3,对256*256的图像做归一化处理。
54.其中,步骤2中的神经网络模型的训练包括如下步骤:
55.步骤2-1,构造神经网络模型;
56.步骤2-2,初始化神经网络模型,采用预训练好的网络参数;
57.步骤2-3,用步骤2中预处理后的正方形图像数据对神经网络模型进行训练,并保存训练好的模型。
58.步骤2-1中神经网络模型具体内容如下:如图2所示,该模型采用rcf,基于vgg 16网络架构。该模型包含五个层级的特征提取架构。具体结构为:输入为大小为 256*256*3的图像;第1层级为包括2个卷积层,卷积核的大小是3*3,卷积核的数量是64;第2层级为包括2个卷积层,卷积核的大小是3*3,卷积核的数量是128;第3 层级为包括3个卷积层,卷积核的大小是3*3,卷积核的数量是256;第4层级为包括 3个卷积层,卷积核的大小是3*3,卷积核的数量是512;第5层级为包括3个卷积层,卷积核的大小是3*3,卷积核的数量是512。每个层级的卷积层,连接一个卷积层,卷积核的大小是1*1,卷积核的数量为21。对于每一层级,将所有的1*1卷积的结果,再连接一个的卷积,卷积核的大小是1*1,卷积核的数量为1,然后再进行一次反卷积,到原始图片的大小,作为该层级的中间输出。最后将5个层级的所有中间输出,进行 concat操作,对该结果进行最后一个卷积操作,卷积核的大小是1*1,卷积核的数量为 1,得到最终输出。
59.其中,步骤4中的霍夫投票算法,具体包括:
60.步骤4-1,建立参数空间。参数θ的范围为(0,π),均分为m个单元。参数ρ的范围为(-l,l)均分为n个单元。因此参数空间一共m*n个单元。l为图片对角线的长度。
61.步骤4-2,建立一个同等大小m*n的投票表格。将之前得到的边缘图像,提取出其中的边缘像素点,可以提取的像素点的个数记为s,对每一个像素点,求其在霍夫空间的m个离散点。
62.步骤4-3,收集所有的边缘像素点对应的所有的霍夫空间的离散点,一共有s*m个。将所有的这些离散点进行在投票表中进行投票,得票数较多的即可作为候选直线。
63.步骤5中,将步骤4中得到的投票结果进行处理。具体包括:
64.步骤5-1下面我们将上述得票较多的候选直线,使用聚类的方法,根据θ和ρ,分成4大类直线簇;
65.步骤5-2对每个直线簇linesi,选出得票数最多的那条直线topi;
66.步骤5-3对每个直线簇linesi,继续搜寻可能的候选直线,但这些直线的得票数必须达到一定的阈值,比如能达到topi的0.5倍。此处,设定每一类的候选直线不能超过3条。
67.步骤6中,根据将步骤5中的四边形的四个角点,对角点坐标进行还原,得到在原图中的4个坐标点。根据4对坐标点,对原图像进行单应性变换,得到矫正后的文本。
68.如图3中根据本发明实现的结果,其中左一为待矫正文本图片;左二为边缘检测的灰度图像;左三为检测到的文本边界;左四为矫正结果。
69.本发明提供的具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1