一种基于大规模网络的数据分类方法和装置
1.本发明涉及数据检测分类等技术领域,尤其涉及一种基于大规模网络的数据分类方法和装置。
背景技术:
2.web服务规模越来越大,通常在不同的容器、虚拟机或物理机上运行数千甚至几十万个系统实例。这些系统实例的可靠性对web服务至关重要,系统实例上发生的异常行为可能会降低web服务的可用性,影响用户体验,甚至导致巨大的经济损失。现实中的监控指标数据通常被记录下来形成多变量时间序列(multivariate time series,mts)。一系列基于深度学习的方法可以准确地学习海量mts数据中复杂的模式以用于mts异常检测工作。
3.然而,大规模web服务中存在大量的系统实例(例如,阿里巴巴和字节跳动拥有数百万个系统实例),为每个系统实例训练mts异常检测模型将消耗大量计算资源;另一方面,不同系统实例的mts数据中复杂的数据模式可能有较大差别,为所有系统实例训练一个异常检测模型对于不同的系统实例会降低异常检测工作的准确性。因此,在大规模web服务中部署这些mts异常检测方法是一个相当具有挑战性的问题。
4.现有的方法有copulas、mc2pca、fcfw和ticc均可以对mts数据进行聚类;ctf可以先对数据进行聚类然后进行异常检测。copulas考虑了单个mts中两个变量之间的关系,通过比较两个mts之间的距离进行基于密度的非参数估计;mc2pca为每个簇构建公共投影轴,通过计算在相应公共投影轴上的重建误差将数据分配到不同的簇;fcfw基于两种距离计算方法——dtw和sbd,通过比较两个mts之间的距离生成聚类结果;ticc关注mts中的子序列,提出一种基于模型的聚类方法,ticc算法中的每个簇都由一个描述了该簇中典型子序列中不同观测值之间的相互依赖性相关性网络定义。ctf是一个为omnianomaly设计的框架,旨在提高训练效率。
5.copulas受到维数爆炸的影响,计算成本很高;mc2pca只考虑了簇内的相似性没有考虑簇间的相似性,可能会导致簇的数量过多;fcfw采用的dtw和sbd两种算法的时间复杂度都非常高,无法应用于大规模数据;ticc同时对mts数据进行分割和聚类,非常消耗时间和计算空间,同样无法应用于大规模数据。同时,以上四种算法均针对理想的平滑数据设计,并未考虑真实场景下收集的数据存在噪声和异常数据,这些噪音和异常会很大程度的影响聚类效果。整体来讲,现有聚类方法无法对规模巨大(系统实例数量、指标数量、时间点数)且包含噪音和异常的数据进行高效且精确的聚类。ctf仅能与特定的异常检测算法结合使用,而不能与其他异常检测算法一起使用,具有较大局限性。
技术实现要素:
6.本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
7.为此,本发明的目的在于提出一种基于大规模网络的数据分类方法,利用一维卷积自动编码器(1dcae)将高维数据嵌入低维数据提取mts的主要特征嵌入到低维数据中,可
以有效减少聚类开销,而且消除了噪声和异常的影响。此外,采用了一种高效且有效的策略来选择周期性和代表性特征,防止某些特征干扰mts聚类效果。本发明是一种高效、鲁棒的方案,能够实现对系统实例mts的正常模式进行精确且高效聚类,并有效降低异常检测模型的训练开销。
8.本发明的另一个目的在于提出一种基于大规模网络的数据分类装置。
9.为达上述目的,本发明一方面提出了一种基于大规模网络的数据分类方法,包括:
10.获取待检测数据;其中,所述待检测数据包括系统级指标和用户级指标;对所述待检测数据的多变量时间序列进行平滑和归一化的数据预处理得到预处理数据;将所述预处理数据输入通过离线聚类训练好的一维卷积自动编码器进行数据压缩处理,并使用所述离线聚类得到的特征索引执行特征选择,根据所述特征选择的结果进行距离计算,以进行在线数据分类;基于所述在线数据分类,输出所述待检测数据的在线分类结果。
11.另外,根据本发明上述实施例的基于大规模网络的数据分类方法还可以具有以下附加的技术特征:
12.进一步地,在本发明的一个实施例中,所述系统级指标包括:cpu利用率、内存利用率、磁盘i/o和网络吞吐量中的多种;所述用户级指标包括:平均响应时间、错误率和页面浏览次数中的多种。
13.进一步地,在本发明的一个实施例中,对所述一维卷积自动编码器进行训练,包括:离线对所述待检测数据的多变量时间序列进行所述数据预处理得到所述预处理数据;利用所述预处理数据训练一维卷积自动编码器并压缩所述预处理数据的每个变量上的时间点数量,得到第一隐藏表示;在所述第一隐藏表示上执行所述特征选择获得特征索引,基于所述特征索引通过聚类方式进行离线聚类得到簇中心。
14.进一步地,在本发明的一个实施例中,所述使用所述离线聚类得到的特征索引执行特征选择,根据所述特征选择的结果进行距离计算,以进行在线数据分类,包括:使用离线聚类训练好的一维卷积自动编码器压缩所述预处理数据的每个变量上的时间点数量,得到第二隐藏表示;使用所述特征索引在所述第二隐藏表示上执行特征选择获得第三隐藏表示;计算所述第三隐藏表示与所述簇中心之间的距离,并选择距离最短的簇中心对应的簇作为所述在线数据分类的类别。
15.进一步地,在本发明的一个实施例中,所述数据预处理,包括:
16.使用线性插值方式对多变量时间序列mts进行填充删除或缺失的值,通过滑动窗口滑动平均算法提取mts曲线的基线对所述mts曲线进行平滑,并在所有数据中采用归一化,将每个数据点缩放到[0,1]范围内,所述归一化的公式为:
[0017][0018]
进一步地,在本发明的一个实施例中,述特征选择,包括:删除非周期性特征、构建冗余特征矩阵和删除冗余特征。
[0019]
进一步地,在本发明的一个实施例中,所述删除非周期性特征,包括:使用yin提取周期性信息,删除非周期性特征后得到保留的特征;其中,yin(z
sm
)》0表示特征z
sm
存在周期性,yin(z
sm
)=0表示特征z
sm
没有周期性模式;所述构建冗余特征矩阵,包括:构建得到冗余
特征矩阵r∈[0,1]m′×m′
,并使用归一化互相关函数计算两个特征之间是否存在冗余;其中,m’表示删除非周期性特征后保留的特征数量,r
ij
》0表示特征i和特征j之间存在冗余,r
ij
=0特征i和特征j之间不存在冗余;所述删除冗余特征,包括:定义一组未分配的特征f,f包含所有m’特征的索引,将预设的特征选择规则从第一规则到第四规则顺序迭代应用于f,直到将所有特征分配给选择特征集sf或删除特征集df,将sf中的所有选定特征拼接成为z”,做为所述聚类或所述分类的输入。
[0020]
进一步地,在本发明的一个实施例中,采用层次聚类的方式对z”进行聚类,初始化每条数据为一个簇,迭代计算簇间距离,并将所述簇间距离低于距离阈值的簇进行合并,直到所有所述簇间距离都大于所述距离阈值。
[0021]
进一步地,在本发明的一个实施例中,所述簇间距离为欧几里得距离:
[0022][0023]
其中,|*|表示集合的大小,m”是sf中索引的数量。
[0024]
本发明实施例的基于大规模网络的数据分类方法,采用了高效且有效的策略来选择周期性和代表性特征,防止某些特征干扰mts聚类效果。并且本发明的方法是一种具有高效、鲁棒的方案,能够实现对系统实例mts的正常模式进行精确且高效聚类,并有效降低异常检测模型的训练开销。
[0025]
为达到上述目的,本发明另一方面提出了一种基于大规模网络的数据分类装置,包括:
[0026]
数据获取模块,用于获取待检测数据;其中,所述待检测数据包括系统级指标和用户级指标;
[0027]
数据处理模块,用于对所述待检测数据的多变量时间序列进行平滑和归一化的数据预处理得到预处理数据;
[0028]
数据分类模块,用于将所述预处理数据输入通过离线聚类训练好的一维卷积自动编码器进行数据压缩处理,并使用所述离线聚类得到的特征索引执行特征选择,根据所述特征选择的结果进行距离计算,以进行在线数据分类;
[0029]
结果输出模块,用于基于所述在线数据分类,输出所述待检测数据的在线分类结果。
[0030]
本发明实施例的基于大规模网络的数据分类装置,采用了高效且有效的策略来选择周期性和代表性特征,防止某些特征干扰mts聚类效果。并且本发明的方法是一种具有高效、鲁棒的方案,能够实现对系统实例mts的正常模式进行精确且高效聚类,并有效降低异常检测模型的训练开销。
[0031]
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
[0032]
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
[0033]
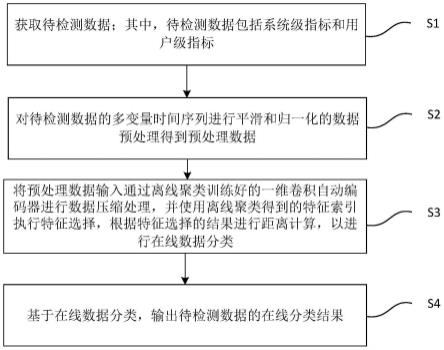
图1为根据本发明实施例的基于大规模网络的数据分类方法的流程图;
[0034]
图2为根据本发明实施例的聚类部分设计整体结构图;
[0035]
图3为根据本发明实施例的异常检测部分整体示意图;
[0036]
图4为根据本发明实施例的1d-cae模型示结构示意图;
[0037]
图5为根据本发明实施例的特征选择过程示意图;
[0038]
图6为根据本发明实施例的基于大规模网络的数据分类装置的结构示意图。
具体实施方式
[0039]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
[0040]
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
[0041]
下面参照附图描述根据本发明实施例提出的基于大规模网络的数据分类方法及装置。
[0042]
图1是本发明一个实施例的基于大规模网络的数据分类方法的流程图。
[0043]
如图1所示,该方法包括但不限于以下步骤:
[0044]
s1,获取待检测数据;其中,待检测数据包括系统级指标和用户级指标;
[0045]
s2,对待检测数据的多变量时间序列进行平滑和归一化的数据预处理得到预处理数据;
[0046]
s3,将预处理数据输入通过离线聚类训练好的一维卷积自动编码器进行数据压缩处理,并使用离线聚类得到的特征索引执行特征选择,根据特征选择的结果进行距离计算,以进行在线数据分类;
[0047]
s4,基于在线数据分类,输出待检测数据的在线分类结果。
[0048]
可以理解的是,为了主动检测系统实例的异常行为并及时缓解系统故障,web服务运营商在系统中会配置不同类型的系统级指标(例如cpu利用率、内存利用率、磁盘i/o、网络吞吐量)和用户级别的指标(例如平均响应时间、错误率、页面浏览次数),并在预定的时间间隔内持续收集监测数据。
[0049]
具体的,获取的监测数据用于后续的数据聚类和分类。
[0050]
如图2所示,本发明的聚类部分设计方案由离线聚类和在线分类两个主要部分组成,整体结构如图2所示,其中实线表示离线聚类,虚线表示在线分类。
[0051]
离线聚类分为四个流程阶段。第一阶段是数据预处理,首先对mts数据进行平滑和归一化处理;第二阶段训练1d-cae并压缩每个变量上的时间点数量,得到隐藏表示z;第三阶段在z上执行特征选择,从而减少每条数据中的变量数以获得z’;最后一个阶段使用层次聚类的方法对数据进行聚类。
[0052]
在线分类同样分为四个阶段,第一阶段是与离线聚类第一阶段相同的数据预处理,对数据进行平滑和归一化处理;第二阶段使用离线聚类第二阶段训练得到的1d-cae编码器压缩每个变量上的时间点数量,得到隐藏表示z;第三阶段使用离线聚类第三阶段得到
的特征(变量)索引在z上执行特征选择获得z’;最后一个阶段计算z’与离线聚类第四阶段得到的簇中心之间的距离,并选择距离最短的簇中心对应的簇作为数据类别。
[0053]
进一步地,异常检测部分整体设计如图3所示:
[0054]
异常检测部分分为离线训练异常检测模型和在线检测数据异常两个部分。
[0055]
本发明统一使用x
smt
表示第s个系统实例的第m个变量第t时间点的数据;第s个系统实例xs是一个m
×
t的矩阵,其中系统实例中共有m个变量和t个时间点的监控数据。
[0056]
下面结合附图对发明实施例做详细阐述说明:
[0057]
数据预处理。mts中通常存在会显著影响数据的形状的噪音、异常和缺失值,必须尽量减少它们带来的负面影响。由于极值通常更有可能成为异常,本发明使用删除偏离平均值的前5%数据的方法处理极值;并且在真实生产情况下,数据收集过程中可能存在错误导致数据中存在一些缺失值,本发明使用线性插值来填充删除或缺失的值;为了处理噪声,本发明通过滑动窗口滑动平均算法提取mts曲线的基线来对mts曲线进行平滑。最后,为了处理不同数据存在的振幅差异,在所有数据中采用归一化,将每个数据点缩放到[0,1]范围内,具体归一化公式为:
[0058][0059]
离线聚类与在线分类均采用相同的数据预处理步骤。
[0060]
1d-cae压缩数据。为了减少过高的数据维度的对聚类效率的影响,如图4所示本发明使用1d-cae和重建损失函数进行模型训练可以有效降低数据维度,并捕捉数据的非线性特征。
[0061]
可以理解的是,自动编码器(autoencoder,ae)包括两个基本单元:编码器和解码器。编码器将输入压缩为潜在空间表示,解码器使用潜在空间表示重构输入数据。ae可以通过最小化输入和输出之间的差异(重构损失)来优化模型参数。卷积自动编码器(convolutional autoencoder,cae)使用卷积神经网络(convolutional neural networks,cnn)编码器和解码器。本发明中1d-cae被用于特征提取和降维。卷积编码器可以学习输入数据的正常模式,忽略噪声和异常。本发明中的编码器,mts中的每个变量被输入到不同卷积神经网络中,可以获得m个相应的特征。卷积解码器由m个具有独立参数的一维反卷积神经网络构成。编码器输出为压缩得到的特征z,是一个m
×
t
′
的矩阵,t
′
为每个变量的维度;解码器的输出是原始数据的重建大小与输入数据x一致。下图展示了1d-cae模型示意图,当输入mts有三个变量时,1d-cae的编码器由三个卷积神经网络构成,解码器由三个一维反卷积神经网络构成。
[0062]
进一步地,离线聚类过程中使用均方误差作为损失函数,通过最小化输入数据x和输出数据之间的损失,持续更新1d-cae模型。最终保存1d-cae的编码器结构和参数并获得数据的z作为下一阶段输入。在线分类使用离线聚类保存的1d-cae的编码器获得数据的z作为下一阶段输入。
[0063]
特征选择。本发明实现了一种稳健的通用特征选择方法,以减少度量维中的特征数量,提高聚类性能。特征选择过程包括三个步骤:删除非周期性特征,构建冗余特征矩阵和删除冗余特征,示意图如图5所示:
[0064]
1)删除非周期性特征:
[0065]
首先使用yin提取周期性信息,yin(z
sm
)》0表示特征z
sm
存在周期性,而yin(z
sm
)=0表示特征z
sm
没有明显的周期性模式。在大多数系统实例中都为非周期性的特征对应的索引将被删除,具体为算法1所示。删除非周期性特征后得到保留的特征用z
′
表示。
[0066]
算法1
[0067][0068]
2)构建冗余特征矩阵:
[0069]
构建得到冗余特征矩阵r∈[0,1]m′×m′
(m’表示删除非周期性特征后保留的特征数量),其中r
ij
》0表示特征i和特征j之间存在冗余,r
ij
=0特征i和特征j之间不存在冗余。使用归一化互相关函数(normalized cross-correlation,ncc)计算两个特征之间是否存在冗余。具体构建方案如算法2所示。
[0070]
算法2
[0071]
[0072][0073]
3)删除冗余特征:
[0074]
本发明应用特征选择规则来利用冗余矩阵r中的冗余特征。首先定义一组未分配的特征f,f包含所有m’特征的索引,然后将以下特征选择规则从规则1到规则4顺序迭代应用于f,直到所有特征被分配给选择特征集sf或删除特征集df。最后,本发明将sf中的所有选定特征拼接成为z”,做为聚类或分类步骤的输入。
[0075]
规则1:如果ri与r中的其他行完全不相关,即ri仅包含零:
[0076]
(a)添加i到择特征集sf:sf=sf∪{i};
[0077]
(b)从f中删除i并且移除r中与i相关的项;
[0078]
规则2:如果ri与r中的其他行全部相关并且r中至少有一个不与其他特征全相关的特征(即r存在非对角线上值为0的情况):
[0079]
(a)添加i到删除特征集df:df=df∪{i};
[0080]
(b)从f中删除i并且移除r中与i相关的项;
[0081]
规则3:如果f中的所有特征相互关联(即r只包含非零的非对角值):
[0082]
(a)选择与sf中包含特征相关性最小的特征i;
[0083]
(b)添加i到择特征集sf:sf=sf∪{i};
[0084]
(c)从f中删除i并且移除r中与i相关的项;
[0085]
(d)将f中剩余特征移动到删除特征集df:df=df∪{i}并终止。
[0086]
规则4:如果规则2和规则3都不适用时:
[0087]
(a)选择与f中包含特征相关性最小的特征i;
[0088]
(b)定义是f中与i相关的特征,然后选择与sf中包含特征相关性最大的特征j∈s(i);
[0089]
(c)添加i到择特征集sf:sf=sf∪{i},添加j到删除特征集df:df=df∪{j};
[0090]
(d)从f中删除i,j并且移除r中与i,j相关的项;
[0091]
在规则3(a)、规则4(a)、规则4(b)中,利用如下公式选择特征:其中r是构建得到的冗余特征矩。
[0092]
离线聚类过程中执行特征选择,获取并保存选择特征集sf,并将选定特征拼接成为z”作为下一阶段输入。在线分类使用离线聚类保存的选择特征集sf获得数据的z”作为下一阶段输入。
[0093]
聚类和分类。离线聚类阶段本发明采用层次聚类的方案对z”进行聚类。首先初始化每条数据为一个簇,然后迭代计算簇间的欧几里得距离
|*|表示集合的大小,以及m”是sf中索引的数量也是保留的特征数量)和将簇间距离低于距离阈值的簇进行合并两个过程,直到所有簇之间的距离都大于距离阈值。离线聚类阶段保留所有的簇中心数据。
[0094]
在线分类阶段计算数据提取得到的特征与离线聚类阶段保留所有的簇中心数据之间的欧几里得距离,然后选择距离最近的簇中心对应的簇类别作为数据的类别。特别注意的是,如果距离最近的簇中心与数据之间的距离也大于距离阈值时,该数据不会被分类,而是报告给任务执行人员作为异常数据,这也加强了本发明的鲁棒性。
[0095]
异常检测。在异常检测离线训练部分,本发明为聚类得到的簇中心分别训练一个异常检测模型(可以是任意现有的异常检测模型),采用与所使用异常检测模型一致的训练方案进行训练。
[0096]
本发明收集实时在线数据,并使用聚类分类得到的数据类别对应的异常检测模型对在线数据进行异常检测。
[0097]
进一步地,在调查了数千个真实世界的系统实例后,本发明可以利用聚类发放将系统实例自动分组到不同的簇中,每个簇的系统实例都具有相似的模式。因此可以为每个簇而不是每个系统实例训练一个mts异常检测模型,由于簇的数量远小于系统实例,可以显著减少训练开销。
[0098]
作为一种实现方式,现有的传统k-means算法或者copulas、mc2pca、fcfw和ticc可以作为本发明的替代方案,但效果和效率均不如本发明理想。
[0099]
作为一种实现方式,本发明中使用的聚类方法为层次聚类,可使用dbscan进行替换;计算数据间距离时使用的欧几里得距离可使用曼哈顿距离、sbd等进行替换。
[0100]
进一步地,作为一种实现方式,任意计算机语言均可,对软、硬件环境无特殊需求。
[0101]
优选地,本发明实现采用计算机语言为python3.8,软件环境为tensorflow2.2,硬件环境为16c32t intel(r)xeon(r)gold 5218cpu@2.30ghz以及192gb的ram,可作为推荐使用。
[0102]
根据本发明实施例的基于大规模网络的数据分类方法,利用一维卷积自动编码器(1dcae)将高维数据嵌入低维数据提取mts的主要特征嵌入到低维数据中,可以有效减少聚类开销,而且消除了噪声和异常的影响。此外,采用了一种高效且有效的策略来选择周期性和代表性特征,防止某些特征干扰mts聚类效果。本发明是一种高效、鲁棒的方案,能够实现对系统实例mts的正常模式进行精确且高效聚类,并有效降低异常检测模型的训练开销。
[0103]
为了实现上述实施例,如图6所示,本实施例中还提供了基于大规模网络的数据分类装置10,该装置10包括:数据获取模块100、数据处理模块200、数据分类模块300和结果输出模块400。
[0104]
数据获取模块100,用于获取待检测数据;其中,待检测数据包括系统级指标和用户级指标;
[0105]
数据处理模块200,用于对待检测数据的多变量时间序列进行平滑和归一化的数据预处理得到预处理数据;
[0106]
数据分类模块300,用于将预处理数据输入通过离线聚类训练好的一维卷积自动
编码器进行数据压缩处理,并使用离线聚类得到的特征索引执行特征选择,根据特征选择的结果进行距离计算,以进行在线数据分类;
[0107]
结果输出模块400,用于基于在线数据分类,输出待检测数据的在线分类结果。
[0108]
根据本发明实施例的基于大规模网络的数据分类装置,利用一维卷积自动编码器(1dcae)将高维数据嵌入低维数据提取mts的主要特征嵌入到低维数据中,可以有效减少聚类开销,而且消除了噪声和异常的影响。此外,采用了一种高效且有效的策略来选择周期性和代表性特征,防止某些特征干扰mts聚类效果。本发明是一种高效、鲁棒的方案,能够实现对系统实例mts的正常模式进行精确且高效聚类,并有效降低异常检测模型的训练开销。
[0109]
需要说明的是,前述对基于大规模网络的数据分类方法实施例的解释说明也适用于该实施例的基于大规模网络的数据分类装置,此处不再赘述。
[0110]
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
[0111]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0112]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1