基于多尺度类间的肿瘤及周围器官的分割方法
1.本发明涉及一种图像处理技术,特别涉及一种基于多尺度类间的肿瘤及周围器官的分割方法。
背景技术:
2.不同于正常器官的分割,肿瘤的自动分割更具有挑战性。影响肿瘤分割的因素主要有以下几点:第一,样本之间差异度大。具体体现在不同病人的肿瘤形状、大小以及病灶位置各有不同;第二,在mri中存在肿瘤内部灰度不均匀,且肿瘤与其周围的正常器官或组织之间的灰度差异非常小等问题;第三,类别不平衡。肿瘤等体素数量相比周围正常组织的体素数量少一个甚至多个数量级。因此,肿瘤与其周围组织的分割相对正常器官的分割更具有挑战性。
技术实现要素:
3.为了提高图像中肿瘤分割精度,提出了一种基于多尺度类间的肿瘤及周围器官的分割方法,建立一种跨尺度注意力u-net模型实现直肠癌肿瘤及直肠的准确分割。
4.本发明的技术方案为:一种基于多尺度类间的肿瘤及周围器官的分割方法,mri图像送入预处理,对图像进行强度归一化以及直方图均衡化,把整个图像分成数量的小块像素进行非线性拉伸,使局部的灰度直方图均匀分布;将预处理过后的图像作为输入图像缩放输入至定位网络,定位出目标区域,然后在输入图像中裁剪出以目标为中心的图像,增大前景像素的占比,之后将所裁剪出的目标区域输入分割网络模型中进一步分割获得完整分割结果。
5.进一步,所述分割网络模型为基于多尺度特征信息的注意力分割网络模型csa-u-net,在由卷积层、下采样的最大池化层、上采样的反卷积层以及relu非线性激活函数组成的u-net基础上,增加注意力门控模块和多尺度的特征信息损失计算,在u-net的跳跃连接中加入注意力门控模块,将解码器中较粗尺度l-1层的卷积特征作为门控信号来选择编码器l层中特征图的空间区域,即在全局范围计算注意力系数以识别显著图像区域,并修剪特征响应以仅保留与特定任务相关的激活;然后再将经过筛选的特征图与相应l层解码器精细密集预测特征图拼接融合,以更好地辅助解码器进行目标定位与恢复;利用多尺度信息,在解码阶段导出不同尺度的特征图进行预测,即在计算损失函数的过程中嵌入不同尺度的空间语义信息,以更好地监督模型的训练。
6.进一步,所述csa-u-net的训练方法:注意力门控模块从下采样逐级获得高维特征,注意力门控模块输出的所有多尺度均会通过上采样得到与输入图像大小相同的分割概率图,然后插入不同尺度空间语义信号后与手工标注图通过损失函数计算偏差差的大小,将这些损失值相加在一起从而进行反向传播,更新网络权重。
7.进一步,所述损失函数采用交叉熵损失函数与基于wasserstein距离的类间损失函数的结合,公式如下:
[0008][0009][0010]
其中n为像素总数,类别集合l={ll=0,1,...,k},类别集合中元素个数为|l|;i表示第i个体素,l表示第l个类别,0表示背景类别,p表示预测向量,g表示所有体素的真实独热向量,gi表示第i个体素的真实one-hot向量,表示第i个体素第l个类别的真实值,w()表示wasserstein距离计算;θ是控制参数,不同类别的体素总量的倒数作为权重,用于衡量不同类别的贡献,即体素总量越多,权重越小,该权重使得在类别不平衡的情况下,体素占比小的类别会被模型更加关注,且背景体素并不会参与到最终的计算当中,因为其权重为0。
[0011]
进一步,所述嵌入不同尺度的空间语义信息时,采用三阶样条插值法将所有体素重新采样为统一大小。
[0012]
进一步,所述csa-u-net的训练采用优化算法adabound进行迭代优化,权重不断更新,损失值逐渐下降,最终训练完成目标任务的分割网络模型。
[0013]
进一步,所述在每次训练迭代中包括随机旋转,剪切,缩放和翻转操作的随机变换以增强数据。
[0014]
一种用于肿瘤及周围器官的分割的分割网络模型,在由卷积层、下采样的最大池化层、上采样的反卷积层以及relu非线性激活函数组成的u-net基础上,增加注意力门控模块和多尺度的特征信息损失计算,在u-net的跳跃连接中加入注意力门控模块,将解码器中较粗尺度l-1层的卷积特征作为门控信号来选择编码器l层中特征图的空间区域,即在全局范围计算注意力系数以识别显著图像区域,并修剪特征响应以仅保留与特定任务相关的激活;然后再将经过筛选的特征图与相应l层解码器精细密集预测特征图拼接融合,以更好地辅助解码器进行目标定位与恢复;利用多尺度信息,在解码阶段导出不同尺度的特征图进行预测,即在计算损失函数的过程中嵌入不同尺度的空间语义信息,以更好地监督模型的训练。
[0015]
本发明的有益效果在于:本发明基于多尺度类间的肿瘤及周围器官的分割方法,可以更好地定位感兴趣区域;有效地融合局部上下文和全局上下文信息;损失函数中融入了类间关系,更好地利用推理时标签的概率向量;提升了体素占比较少的肿瘤类别的精度。
附图说明
[0016]
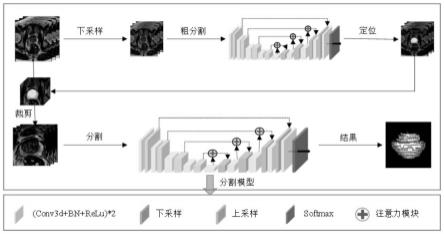
图1为本发明方法流程图;
[0017]
图2为本发明方法中分割网络模型架构图;
[0018]
图3为本发明注意力模块示意图;
[0019]
图4为本发明体素分割概率示例图;
[0020]
图5a为专家标注的分割结果示例图一;
[0021]
图5b为不同损失函数的分割结果示例图二;
[0022]
图5c为不同损失函数的分割结果示例图三;
[0023]
图5d为不同损失函数的分割结果示例图四;
[0024]
图5e为不同损失函数的分割结果示例图五;
[0025]
图5f为不同损失函数的分割结果示例图六。
具体实施方式
[0026]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0027]
在传统u-net基础上加入了注意力门控模块和多尺度的特征信息损失计算,来更好地定位roi,学习肿瘤的特征;同时提出了基于wasserstein距离的类间损失函数,在dice损失函数中加入了类间关系的先验知识以及类别权重,充分利用推理时标签的概率向量,提升了体素占比较少的肿瘤类别的精度。
[0028]
本发明的基于多尺度类间的肿瘤及周围器官的分割方法,包括以下步骤:
[0029]
步骤1、预处理图像:首先对于图像进行强度归一化以及直方图均衡化,把整个图像分成许多小块像素进行非线性拉伸,使局部的灰度直方图均匀分布。
[0030]
训练时的用于训练数据集:图像数据集来自复旦大学附属中山医院2019~2021年直肠癌患者矢状面t2wi影像学资料135例。除了预处理图像为了使网络能够正确学习空间语义,采用三阶样条插值法将所有体素重新采样为统一大小。采用最近邻插值法用于相应的分割标注。在每次训练迭代中主要包括随机旋转,剪切,缩放和翻转操作的随机变换以增强数据。
[0031]
步骤2,如图1所示方法流程图,将预处理过后的图像作为输入图像缩放输入至定位网络,定位出目标大致区域,然后在输入图像中裁剪出以目标为中心的图像,增大前景像素的占比,以解决类别的极度不平衡。之后将所裁剪出的目标区域输入分割网络模型中进一步分割获得完整分割结果。
[0032]
将整个直肠肿瘤3d图像缩小到192
×
128
×
32之后输入定位网络中,得到前列腺的粗分割从而得到其大致的位置,在原大小图像中裁剪出以前列腺为中心的区域,然后再次输入网络中进行精分割。
[0033]
步骤3,建立分割网络模型:输入裁剪后的目标图像及相应的手工标注对分割网络模型进行训练。训练及推理的网络是一个基于多尺度特征信息的注意力分割网络csa-u-net,如图2所示。u-net主要由卷积层、最大池化层(下采样)、反卷积层(上采样)以及relu非线性激活函数组成,采用负斜率0.01的leaky relu作为激活函数。在u-net的跳跃连接中我们加入了注意力门控模块(如图3所示),将解码器中较粗尺度(l-1)层的卷积特征作为门控信号来选择编码器l层中特征图的空间区域,即在全局范围计算注意力系数以识别显著图像区域,并修剪特征响应以仅保留与特定任务相关的激活。然后再将经过筛选的特征图与相应l层解码器精细密集预测特征图拼接融合,以更好地辅助解码器进行目标定位与恢复。为了更好地利用多尺度信息,在解码阶段导出不同尺度的特征图进行预测,即在计算损失函数的过程中嵌入了不同尺度的空间语义信息,以更好地监督模型的训练。
[0034]
步骤4,分割网络模型训练:注意力门控模块从下采样逐级获得高维特征,注意力门控模块输出的所有多尺度均会通过上采样得到与输入图像大小相同的分割概率图,然后插入不同尺度空间语义信号后与手工标注图通过我们的损失函数计算偏差的大小,将这些损失值相加在一起从而进行反向传播,更新网络权重。我们的损失函数采用交叉熵(ce)损失函数与基于wasserstein距离的类间(ic)损失函数的结合,公式如下:
[0035][0036][0037]
其中n为像素总数,类别集合l={ll=0,1,...,k},类别集合中元素个数为|l|;i表示第i个体素,l表示第l个类别,0表示背景类别,p表示预测向量,g表示所有体素的真实独热(one-hot)向量,gi表示第i个体素的真实one-hot向量,表示第i个体素第l个类别的真实值,w()表示wasserstein距离计算。θ是控制参数,不同类别的体素总量的倒数作为权重,用于衡量不同类别的贡献,即体素总量越多,权重越小。该权重使得在类别不平衡的情况下,体素占比小的类别会被模型更加关注。且背景体素并不会参与到最终的计算当中,因为其权重为0。
[0038]
采用交叉熵(ce)损失函数与类间(ic)损失函数计算解码层所有的输出与标注的偏差之和。损失函数的计算以一个体素的损失值为例,如图4所示,图中左边部分是腹部mri图像以及直肠肿瘤分割掩码,深灰表示直肠,浅灰表示肿瘤,其余部分为背景。此时,l={0,1,2}表示类别空间,其中0表示背景,1表示直肠,2表示肿瘤。图中圆圈中的体素真实值是直肠类别,假设模型分类正确,预测直肠的概率为0.6。虽然该体素分类正确,但是如图4右边的三张柱状图所示,该体素属于其他类别的概率会有多种不同的情况出现。示例1、示例2和示例3列举了三种可能出现的典型预测概率分布:示例1中体素被分类为背景和肿瘤的概率分别为0.1和0.3,示例2分别为0.2和0.2,示例3分别为0.3和0.1。根据ce损失函数的原理,该体素在三种示例的预测概率分布的情况下,损失值均为0.74。而我们提出的ic损失函数则不同,其充分考虑了不同的预测概率分布之间的关系信息,并反映在损失函数中,用于指导模型学习。当自定义类别间的距离,直肠及肿瘤距离背景类别为1,直肠与肿瘤类间距离为0.8时,ic损失函数在这三种示例中得到的损失值分别为0.343,0.347,0.353。
[0039]
步骤5,重复迭代3、4步骤,采用优化算法adabound进行迭代优化,权重不断更新,损失值逐渐下降,最终训练完成目标任务的分割模型。
[0040]
步骤6,将测试图像依次输入定位网络进行粗分割及分割网络模型进行进一步分割,就可推理得到完整的分割结果。
[0041]
基于最基本的dice损失函数对比了基线u-net、加入ag模块的u-net(ag u-net)、加入多尺度特征信息的u-net(cs-u-net)以及融合多尺度特征信息的注意力u-net(csa-u-net)。评价指标为dice系数值,直肠和肿瘤基于不同模型的分割结果如表1所示(均值+方差)。同时基于分割结果最好的csa-u-net我们比较了dice、ce、dice+ce、ic及ic+ce损失函
数,直肠和肿瘤基于不同模型的分割结果如表2所示(均值+方差),其中一例的手动标注及上述这些损失函数的分割结果比较如图5a~5f所示。
[0042]
表1
[0043][0044]
表2
[0045][0046]
本实施例的实验结果表明,本发明方法对于肿瘤的分割精度更高;我们提出的跨尺度注意力u-net模型(csa-u-net)可以更好地定位感兴趣区域,且融合的多尺度监督有助于融入更多的语义信息;我们提出的类间损失函数,更好地利用推理时标签的概率向量,在dice损失函数中融入了类间关系,且加入了类别权重,以弥补dice损失函数只关注前景与背景类别的不足,提升了体素占比较少的肿瘤类别的精度
[0047]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1