一种基于人工智能的自助核酸采集方法及装置与流程
1.本发明涉及图像处理技术领域,尤其涉及一种基于人工智能的自助核酸采集方法及装置。
背景技术:
2.核酸检测采样目前主要采用的是口腔咽拭子采样。采集方式主要为人工采集和机械辅助采集两种,在人工采集的过程中,医护人员需要与患者近距离接触,患者咳嗽、用力呼吸等都会产生大量飞沫或气溶胶,会极大增加医护人员在采样过程中交叉感染风险,工作风险和工作压力巨大,且耗费大量的人力物力财力,医护人员和被采集民众因繁重的采集工作容易产生对立情绪;而机械辅助采集的过程中,如出现机械故障,极易出现伤害被采样者口腔的情况,又因每个被采集者的口腔深度不同,身高不同,年龄不同,左右扁桃腺和后咽壁的生长角度不同等等,极易出现触碰不到口腔采集关键点,从而出现采集样本无效的情况,导致采集成功率低,且民众对机械采集操作容易出现恐惧心理,民众接受度有限,机械辅助采集一般为机械臂设计,机械臂设计成本高,不利于大范围的推广应用。
技术实现要素:
3.(一)要解决的技术问题
4.基于上述问题,本发明提供一种基于人工智能的自助核酸采集方法及装置,针对人工采集和机械辅助采集的弊端,通过被检人员根据提示自助采样,并通过图像识别确保自助采样的有效性,解决机械辅助采集成功率低、易造成伤害,医护人员工作风险和工作量大的问题。
5.(二)技术方案
6.基于上述的技术问题,本发明提供一种基于人工智能的自助核酸采集方法,包括:
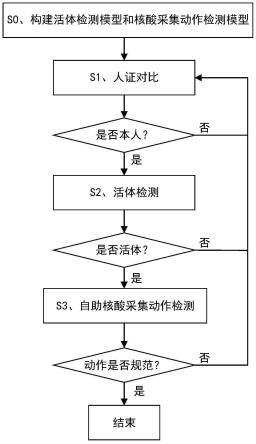
7.s0、构建活体检测模型和核酸采集动作检测模型,所述活体检测模型通过将标注人脸特征点的人脸照片集输入选择的人工智能算法训练得到,输出人脸特征点的坐标;所述核酸采集动作检测模型通过将标注好的带咽拭子的口腔图片集输入选择的人工智能算法训练得到,所述标注的对象为边界框、中心点中的一种和/或分类标签,输出标注的边界框、中心点中的一种的坐标和/或分类标签;
8.s1、人证对比:判断对比用户人脸和用户身份证信息是否是同一人,若是,则进入步骤s2,否则结束;
9.s2、活体检测:判断用户是否是对应的生命体,若是,则进入步骤s3,否则返回步骤s1;
10.s3、自助核酸采集动作检测:用户在规定时间内根据屏幕提示完成咽拭子的目标擦拭位置和目标擦拭次数,获取口腔图像,持续根据坐标计算方法或模型识别方法在所述咽拭子触碰到某一个目标擦拭位置且存在擦拭动作时,记录一次触碰到的所述目标擦拭位置的擦拭成功次数,直到所有目标擦拭位置的擦拭成功次数满足所述目标擦拭次数时,核
酸采集动作合格,结束采集。
11.进一步的,所述步骤s1包括:
12.s11、读取身份证信息,包括姓名,身份证号和身份证件照;
13.s12、对所述身份证件照进行人脸检测,通过特征提取得到n维特征向量,记为features_1;
14.s13、通过视觉采集装置实时捕获用户的人脸,调取视频流;
15.s14、对所述视频流的当前帧进行人脸检测,通过特征提取得到n维特征向量,记为features_2;
16.s15、计算所述features_1与features_2的相似度,判断所述相似度是否达到设定阈值r,若是,则进入步骤s2,否则,进入步骤s16;
17.s16、判断当前帧数是否小于等于设置的帧数阈值q,若是,则帧数加一,返回步骤s14,否则,返回步骤s11。
18.进一步的,所述步骤s2包括:
19.s21、加载所述活体检测模型,开启视觉采集装置,j=1;
20.s22、提示用户进行随机的第j个活体检测动作,记录动作时间;
21.s23、判断所述动作时间是否超时,若是,则返回步骤s11,否则,进入步骤s24;
22.s24、捕获连续m帧数据,m≥2,通过所述活体检测模型得到连续两帧图像的人脸特征点坐标,记录眨眼次数,并计算当前活体检测动作的变化幅度,记为f,判断f是否符合对应的阈值,若是,则当前活体检测动作达标,j=j+1,进入步骤s25;否则,j不变,返回步骤s22;
23.s25、判断j是否大于3,若是,则进入步骤s26;否则,返回步骤s22;
24.s26、判断所述眨眼次数是否达到阈值dz,若是,则表示用户是活体,活体检测成功;否则返回步骤s11。
25.进一步的,所述眨眼次数的记录方法包括:眨眼次数初始为零,计算连续两帧图像中眨眼动作的变化幅度,记为f,判断f是否符合对应的阈值d,若是,则眨眼次数加一,否则眨眼次数不变。
26.进一步的,所述眨眼动作的判断条件为:连续两帧图像中眼睛的纵横比是否小于对应的阈值d;所述活体检测动作从七个活体检测动作中随机选择,所述七个活体检测动作包括抬头、低头、向左看、向右看、张嘴、点头和摇头,所述抬头的达标条件为:连续两帧图像欧拉角中的俯仰角变化的差值大于对应的阈值;所述低头的达标条件为:连续两帧图像欧拉角中的俯仰角变化的差值小于对应的阈值;所述向左看的达标条件为:连续两帧图像欧拉角中的偏航角变化的差值小于对应的阈值;所述向右看的达标条件为:连续两帧图像欧拉角中的偏航角变化的差值大于对应的阈值;所述张嘴的达标条件为:连续两帧图像上下外嘴唇或上下内嘴唇的长宽比变化大于对应的阈值;所述点头的达标条件为:连续两帧图像鼻子沿竖轴的比值变化大于对应的阈值;所述摇头的达标条件为:连续两帧图像鼻子沿横轴的比值变化大于对应的阈值。
27.进一步的,所述步骤s3包括以下步骤:
28.s31、加载模型及参数,开启视觉采集装置;
29.s32、屏幕提示咽拭子的目标擦拭位置和目标擦拭次数,记录操作时间;所述目标
擦拭位置的擦拭成功次数初始为零,所述目标擦拭位置包括左扁桃腺、右扁桃腺和/或咽后壁;
30.s33、判断所述操作时间是否超时,若是,则返回步骤s11,否则,进入步骤s34;
31.s34、根据坐标计算方法或模型识别方法判断所述咽拭子是否触碰到某一个目标擦拭位置并存在擦拭动作,若是,则触碰到的所述目标擦拭位置对应的擦拭成功次数加一,进入步骤s35;否则,屏幕提示未完成情况,返回步骤s33;
32.s35、判断所有目标擦拭位置的擦拭成功次数是否满足所述目标擦拭次数,若是,则核酸采集动作合格,结束采集;否则,屏幕提示未规范处,返回步骤s33。
33.进一步的,所述步骤s0中,所述核酸采集动作检测模型为咽拭子口腔目标检测模型、咽拭子口腔关键点检测模型、核酸采集动作分类模型或核酸采集动作多任务分类模型,构建方法均包括:拍照获取带咽拭子的口腔照片集,对各带咽拭子的口腔照片进行标注后预处理,然后输入到选择的人工智能算法中进行训练;
34.所述咽拭子口腔目标检测模型标注的对象为边界框,包括左侧扁桃腺、右侧扁桃腺、咽后壁和咽拭子的边界框,选择的人工智能算法包括yolov5、r-cnn、fast r-cnn、faster r-cnn、r-fcn、ssd、yolo、yolov2、yolov3和yolov4;
35.所述咽拭子口腔关键点检测模型标注的对象为中心点,包括左侧扁桃腺、右侧扁桃腺、扁桃体和咽拭子头的中心点,选择的人工智能算法包括resnet残差网络系列、hrnet高分辨率网络系列、cornernet系列、mtcnn和vgg系列;
36.所述核酸采集动作分类模型标注的对象为分类标签,包括:0:未触碰到目标擦拭位置,1:触碰到左扁桃体腺,2:触碰到右扁桃体腺,3:触碰到咽后壁的分类标签,选择的人工智能算法包括resnet系列和vgg系列;
37.所述核酸采集动作多任务分类模型采用多任务学习mtl,任务一与任务二并行,任务一为所述核酸采集动作分类模型,标注的对象和训练方法与所述核酸采集动作分类模型相同,任务二为所述咽拭子口腔目标检测模型或所述咽拭子口腔关键点检测模型,标注的对象和训练方法先与所述咽拭子口腔目标检测模型或咽拭子口腔关键点检测模型相同,再将输出的所述目标或关键点的坐标优化为分类标签,最后使用以下带权重因子的目标函数综合任务一和任务二的分类结果:
[0038][0039]
其中,第一项表示任务一的损失函数,λa表示任务一的重要性因子,第二项表示任务二的损失函数,λb表示任务二的重要性因子,la表示任务一的损失函数,lb表示任务二的损失函数,f(xi;wa)表示xi与任务一的权值矩阵wa相乘之后经过函数f(*),f(xi;wb)表示xi与任务二的权值矩阵wb相乘之后经过函数f(*),w
t
表示整个多任务的权值矩阵,φ(*)是正则项,xi表示输入的图片,表示任务一的标签,表示任务二的标签;
[0040]
所述预处理包括图像裁剪和筛选、几何归一化、灰度化和数据增强,所述数据增强包括图像增强和仿射变换。
[0041]
进一步的,所述步骤s34中,根据坐标计算方法判断所述咽拭子是否触碰到某一个目标擦拭位置并存在擦拭动作,包括:
[0042]
s34a1、根据所述咽拭子口腔目标检测模型、咽拭子口腔关键点检测模型或核酸采集动作多任务分类模型,识别并计算出当前帧中的咽拭子、左扁桃体腺、右扁桃体腺及咽后壁的中心坐标,判断是否识别成功,若是,则进入步骤s34a2;否则,屏幕提示未规范处,返回步骤s33;
[0043]
s34a2、获取所述咽拭子的中心坐标和各目标擦拭位置的坐标关系,判断咽拭子是否触碰到某一个目标擦拭位置,若是,则触碰到该目标擦拭位置,进入步骤s34a3;否则,未触碰到任一目标擦拭位置,屏幕提示未完成情况,返回步骤s33;
[0044]
s34a3、获取连续m帧中咽拭子与各目标擦拭位置的距离,计算每两帧中对应距离的差值,判断各距离差值中的最大值是否大于阈值dx,若是,则咽拭子有擦拭动作,步骤s34a2触碰的所述目标擦拭位置对应的擦拭成功次数加一,进入步骤s35;否则,咽拭子无擦拭动作,屏幕提示未完成情况,返回步骤s33。
[0045]
进一步的,当所述核酸采集动作检测模型为咽拭子口腔目标检测模型,或所述核酸采集动作多任务分类模型的任务二为咽拭子口腔目标检测模型时,
[0046]
所述步骤s34a1包括:先通过所述咽拭子口腔目标检测模型或任务二为咽拭子口腔目标检测模型的所述核酸采集动作多任务分类模型,获取各目标的边界框坐标,再通过各目标的边界框坐标计算得到每个目标即咽拭子、左扁桃体腺、右扁桃体腺和咽后壁的中心坐标;
[0047]
所述步骤s34a2包括:比较判断所述咽拭子的中心坐标是否在所述目标擦拭位置对应的边界框内,若是,则擦拭到该目标擦拭位置,否则,未擦拭到任一目标擦拭位置。
[0048]
进一步的,当所述核酸采集动作检测模型为咽拭子口腔关键点检测模型,或所述核酸采集动作多任务分类模型的任务二为咽拭子口腔关键点检测模型时,
[0049]
所述步骤s34a1包括:直接通过所述咽拭子口腔关键点检测模型或任务二为咽拭子口腔关键点检测模型的所述核酸采集动作多任务分类模型,得到咽拭子、左扁桃体腺、右扁桃体腺和咽后壁的中心坐标,咽拭子的中心坐标即所述咽拭子头的中心点坐标,咽后壁的中心坐标即所述扁桃体的中心点坐标;
[0050]
所述步骤s34a2包括:先分别计算所述左扁桃腺的中心坐标、右扁桃腺的中心坐标、咽后壁的中心坐标到咽拭子的中心坐标之间的距离,分别记为ρ1、ρ2、ρ3;再取min{ρ1,ρ2,ρ3}与距离阈值dy进行比对,当min{ρ1,ρ2,ρ3}》dy时,表示未擦拭到任一目标擦拭位置;当min{ρ1,ρ2,ρ3}≤dy时,表示擦拭到min{ρ1,ρ2,ρ3}对应的目标擦拭位置。
[0051]
进一步的,所述步骤s34中,根据模型识别方法判断所述咽拭子是否触碰到某一个目标擦拭位置并存在擦拭动作,包括:
[0052]
s34b1、根据所述核酸采集动作分类模型或所述核酸采集动作多任务分类模型识别核酸采集动作的分类结果,判断是否识别成功,若是,则进入步骤s34b2;否则,屏幕提示未完成情况,返回步骤s33;所述分类结果即所述分类标签;定义0为假,1、2、3为真;
[0053]
s34b2、判断是否“当前帧u的分类结果为真,且上一帧u-1的分类结果为假”,若是,则进入步骤s34b3,否则,令u=u+1,判断当前帧数是否达到帧数阈值,若是,则屏幕提示未完成情况,返回步骤s33;否则重新进入步骤s34b2;
[0054]
s34b3、判断是否“当前帧u的分类结果为真,且下一帧u+1的分类结果为假”,若是,则进行了一次有效擦拭动作,所述真对应的目标擦拭位置的擦拭成功次数加一,令u=u+2,
进入步骤s35;否则,令u=u+1,判断当前帧数是否达到帧数阈值,若是,则屏幕提示未完成情况,返回步骤s33;否则重新进入步骤s34b3。
[0055]
本发明也公开了一种基于人工智能的自助核酸采集装置,包括控制模块,以及分别与所述控制模块连接的身份证读卡器、视觉采集装置、屏幕和存储模块,所述身份证读卡器用于读取身份证信息,所述视觉采集装置用于捕获用户的人脸和口腔图像,所述存储模块用于存储构建好的所述活体检测模型和核酸采集动作检测模型及其参数,以及采集的视频流,所述控制模块运行所述的基于人工智能的自助核酸采集方法。
[0056]
(三)有益效果
[0057]
本发明的上述技术方案具有如下优点:
[0058]
(1)本发明提供了的核酸采集方法和装置,由采集者自助操作采集动作,通过图像智能识别技术进行人证对比和活体检测的双重身份确认,确保是真实本人进行的采集,并通过图像智能识别技术对核酸采样的关键位置进行判断,确保自助核酸采集动作的规范性,从而有利于保证采集样本的有效性;
[0059]
(2)本发明构建了带咽拭子的口腔图像数据集,对核酸采样的关键位置的判断中,利用人工智能算法建模,由此进行的图像智能识别技术精度高,包括坐标计算方法和模型识别方法,都满足咽拭子触碰到各目标擦拭位置和咽拭子是动态具有擦拭动作的双重条件,提高了核酸采集动作规范性的识别准确度;对活体检测的判断中,除了对随机抽取的活体检测动作进行判断,也记录有效眨眼次数,进一步确保是生命体正在进行自助操作,提高了活体检测的准确度;能适用于不同地区的核酸检测标准,具有较好的推广意义;
[0060]
(3)本发明的坐标计算方法分别采用了目标检测方法和关键点检测方法两种不同的建模方法,对应选择不同的特征,由此进行的识别方法也存在不同;本发明的模型识别方法对图像识别的运用更多,核酸采集动作分类模型直接根据标注的分类标签进行识别,核酸采集动作多任务分类模型运用多任务学习,有利于增强识别准确度,并通过带权重因子的目标函数,进一步提高识别的准确度,且在构建数据集时就根据坐标计算进行了触碰分类,从而使得用户应用时,减少了计算量,准确度高且计算速度更快;
[0061]
(4)本发明相比于普通的机械辅助采集,除了提高了采集样本的有效性以外,由采集者自助操作采集动作,避免了伤害被采样者口腔的机械事故,且民众不会出现对机械采集操作的恐惧心理;未采用机械臂,装置结构简单,大幅降低了设备成本,有利于大范围的推广应用;
[0062]
(5)本发明相比于人工采集,能24小时不间断工作,提高采集效率,避免了采集工作的人群集中和拥堵,大幅度减轻人工采集工作量,节约大量的人力物力财力,避免了医护人员交叉感染的风险,极大的减轻医护人员的工作风险和工作压力,同时避免了医护人员和被采集民众因繁重的采集工作带来的对立情绪。
附图说明
[0063]
通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:
[0064]
图1为本发明实施例的一种基于人工智能的自助核酸采集方法的流程图;
[0065]
图2为本发明实施例的咽拭子口腔分类检测模型的图像数据集标注示意图;
[0066]
图3为本发明实施例的咽拭子口腔关键点检测模型的图像数据集标注示意图;
[0067]
图4为本发明实施例的人证对比的流程图;
[0068]
图5为本发明实施例的活体检测的流程图;
[0069]
图6为本发明实施例的采用坐标计算方法的核酸采集动作检测的流程图;
[0070]
图7为本发明实施例的采用模型识别方法的核酸采集动作检测的流程图。
具体实施方式
[0071]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0072]
本发明公开了一种基于人工智能的自助核酸采集方法,如图1所示,包括以下步骤:
[0073]
s0、构建活体检测模型和核酸采集动作检测模型,所述活体检测模型通过将标注人脸特征点的人脸照片集输入选择的人工智能算法训练得到,输出人脸特征点的坐标;所述核酸采集动作检测模型通过将标注好的带咽拭子的口腔图片集输入选择的人工智能算法训练得到,输出选择的对象;所述核酸采集动作检测模型为咽拭子口腔目标检测模型、咽拭子口腔关键点检测模型、核酸采集动作分类模型或核酸采集动作多任务分类模型;具体的:
[0074]
s0a、活体检测模型的构建方法为:
[0075]
1)拍照获取人脸照片集;
[0076]
2)使用labelimg(或labelme、labelbox、rectlabel、cvat、liblabel、annomage)标注人脸照片集中人脸的68个特征点,获得数据集;
[0077]
3)再利用卷积神经网络如resnet-50算法(或resnet系列、tcdcn、cornernet系列、hrnet(高分辨率网络)系列、openpose、mtcnn、vgg系列)在数据集上训练,得到活体检测模型及其模型参数。
[0078]
s0b、咽拭子口腔目标检测模型的构建方法为:
[0079]
1)拍照获取带咽拭子的口腔照片集;
[0080]
2)对各带咽拭子的口腔照片进行目标对象的标注,目标对象包括左侧扁桃腺、右侧扁桃腺、咽后壁和咽拭子的边界框,得到含四个目标标签的咽拭子口腔图像数据集,标注工具可选用labelimg(或labelme、labelbox、rectlabel、cvat、liblabel、annomage),如图2所示;
[0081]
3)预处理后通过迁移学习,将所述含四个目标标签的咽拭子口腔图像数据集输入到选择的神经网络算法中进行训练,得到咽拭子口腔目标检测模型及其模型参数,可以用到的神经网络有yolov5、r-cnn、fast r-cnn、faster r-cnn、r-fcn、ssd、yolo、yolov2、yolov3、yolov4等,这里采用yolov5算法,模型的输出为上述四个目标对象的边界框坐标。
[0082]
s0c、咽拭子口腔关键点检测模型的构建方法为:
[0083]
1)拍照获取带咽拭子的口腔图片;
[0084]
2)对处理后的带咽拭子的口腔图片进行关键点对象标注,关键点对象包括左侧扁桃腺、右侧扁桃腺、扁桃体和咽拭子头的中心,(这里由于扁桃体的特征比较明显并且二维的位置与咽后壁的位置是一致的,所以用扁桃体来代替咽后壁的位置),如图3所示,得到含
四个关键点标签的咽拭子口腔图像数据集,标注工具可选用vott(或cvat,labelme,labelimg,via-vgg image annotator,pixel annotation tool,vatic等),标记的坐标存储起来作为标签:左扁桃腺x坐标、左扁桃腺y坐标、右扁桃腺x坐标、右扁桃腺y坐标、扁桃体x坐标、扁桃体y坐标、咽拭子头中心x坐标;
[0085]
3)预处理后通过迁移学习,将所述含四个关键点标签的咽拭子口腔图像数据集输入到选择的神经网络算法中进行训练,得到口腔咽拭子关键点检测模型及其模型参数,可以用到的神经网络有:resnet(残差网络)系列,hrnet(高分辨率网络)系列,mtcnn,vgg系列,cornernet系列等,这里选择resnet-18做迁移学习,resnet-18基于vgg19进行改进的现有算法,模型的输出为上述四个关键点对象的坐标。
[0086]
s0d、构建核酸采集动作分类模型:
[0087]
1)拍照获取带咽拭子的口腔照片集;
[0088]
2)对各带咽拭子的口腔照片进行分类标签的对象标注,对象分类标签包括:0:未触碰到目标擦拭位置,1:触碰到左扁桃体腺,2:触碰到右扁桃体腺,3:触碰到咽后壁,得到含四种分类标签对象的咽拭子口腔图像数据集;比如照片中触碰到右扁桃体腺则标注为2;
[0089]
3)预处理后通过迁移学习,将所述含四种分类标签的咽拭子口腔图像数据集输入到选择的深度学习模型中进行训练,以80%为训练集,10%为验证集,10%为测试集,得到核酸采集动作分类模型及其模型参数,可以用到的深度学习模型有resnet(残差网络)系列、vgg系列等,这里选择vgg-19做迁移学习,模型的输出为四种分类结果:0:未触碰到目标擦拭位置,1:触碰到左扁桃体腺,2:触碰到右扁桃体腺,3:触碰到咽后壁。
[0090]
s0e、构建核酸采集动作多任务分类模型:
[0091]
1)拍照获取带咽拭子的口腔照片集;
[0092]
2)将核酸采集动作分类模型当作任务一,将咽拭子口腔目标检测模型或咽拭子口腔关键点检测模型当作任务二:
[0093]
任务一的标注、预处理和训练与步骤s0c中构建核酸采集动作分类模型的相同;任务二的标注、预处理和训练与步骤s0b1中构建咽拭子口腔目标检测模型相同,或与步骤s0b2中构建咽拭子口腔关键点检测模型相同,再对每张图片的目标边界框坐标或关键点的坐标计算得到咽拭子、左扁桃体腺、右扁桃体腺及咽后壁的中心坐标,判断出咽拭子是否触碰到左扁桃体腺、右扁桃体腺和咽后壁中某一个目标擦拭位置(具体计算方法类似于下文中的s34a1a和s34a2a,s34a1b和s34a2b),从而优化分类结果:0:未触碰到目标擦拭位置,1:触碰到左扁桃体腺,2:触碰到右扁桃体腺,3:触碰到咽后壁;最后使用以下带权重因子的目标函数综合任务一和任务二的分类结果:
[0094][0095]
其中,第一项表示任务一,即核酸采集动作分类的损失函数,λa表示任务一的重要性因子,第二项表示任务二,即目标分类检测的损失函数,λb表示任务二的重要性因子,la表示任务一的损失函数,lb表示任务二的损失函数,f(xi;wa)表示xi与任务一的权值矩阵wa相乘之后经过函数f(*),f(xi;wb)表示xi与任务二的权值矩阵wb相乘之后经过函数f(*),φ(*)是正则项,w
t
表示整个多任务的权值矩阵,xi表示输入的图片,表示任务一的标签,
表示任务二的标签,标签包括分类标签,中心点坐标标签,目标边界框标签。
[0096]
该模型的输出为包括四种分类结果:0:未触碰到目标擦拭位置,1:触碰到左扁桃体腺,2:触碰到右扁桃体腺,3:触碰到咽后壁,以及上述四个目标的边界框坐标或上述四个关键点的坐标。
[0097]
多任务学习(mtl):给定m个学习任务,其中所有或一部分任务是相关但并不完全一样的,多任务学习的目标是通过使用这m个任务中包含的知识来帮助提升各个任务的性能,因此,任务二可以增强任务一的分类准确度;而且在传统的mtl中,各任务的重要程度一致,其目标函数如下:
[0098][0099]
其中,表示与权值矩阵w
t
相乘之后经过函数f(*),l(*)表示损失函数,φ(*)是正则项。
[0100]
不同的任务的学习难易程度不同,若采用相同的损失权重,会导致学习任务难以收敛。因此本方案通过上述带权重因子的目标函数综合任务一和任务二的模型,进一步提高模型的精确度。
[0101]
在利用采集来的数据进行模型训练之前,为了减少干扰,提高核酸动作检测的精准度,需要对采集来的原始数据进行图像预处理。图像预处理的主要目的消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性。所述预处理方法包括:图像裁剪和筛选、几何归一化、灰度化和数据增强,具体如下:
[0102]
(1)图像裁剪和筛选:
[0103]
在采集过程中,因为是人为操作,有一些照片里面可能存在除口腔外的其他面部部分,这时候需要手动进行图像的裁剪,只保留口腔部分,目的是为了减少口腔外部分图像的噪音对模型精度的影响。在裁剪过程中,还发现有一些照片中的咽拭子被遮挡或口腔内部过暗以至于无法分清特征点等情况,这时候需要将这些照片从数据集中移出。
[0104]
(2)几何归一化:对图像进行几何归一化的目的是把图像变换为统一的尺度,为接下来的图片标注奠定基础。将图像统一缩放到a*a(根据经验a可以取128,256,512等)。
[0105]
(3)灰度化:彩色图像是由三个不同的分量组成,当我们在对彩色图像进行处理时往往需要对三个通道依次进行处理,时间开销将会増大。因此为了提高处理速度,减少需要处理的数据量,我们往往将三通道的彩色图像变为单通道的灰度图像,也就是对图像进行灰度化处理。目前,最常用的有4种方法:单分量法、最大值法、平均值法、加权平均法。本实施例选用平均值法。
[0106]
(4)数据增强:数据增强主要是为了增加数据集的样本数量,减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景。本实施例的数据增强包括图像增强和仿射变换。
[0107]
1)图像增强
[0108]
图像增强的目的是改善图像的视觉效果,并依据某些特定的场合有意地强调图像中的整体特征或局部特征,扩大不同特征之间的差别,经过处理后的图像具有更高的识别
性和判读性。近几十年出现了众多的图像增强算法,其中应用比较广泛的有:直方图均衡算法、拉普拉斯增强算法、clahe算法、小波变换算法和retinex算法等。
[0109]
2)仿射变换
[0110]
仿射变换(affine transformation)是指在向量空间中进行一次线性变换(乘以一个矩阵)和一次平移(加上一个向量),变换到另一个向量空间的过程。图像的仿射变换有:平移(translation)、缩放(scale)、旋转(rotation)、翻转(flip)和错切(shear)。
[0111]
本方案对图片进行随机旋转、移动、缩放、边缘填充等仿射变换操作来增加样本数量,标注点的坐标也随之变化。
[0112]
构建好各模型后,基于人工智能的自助核酸采集的方法的操作流程如下所示:
[0113]
s1、人证对比:确保用户人脸和用户身份证信息是同一人,即读取用户身份证信息,捕获用户的人脸照片,q次计算二者的相似度,若某一帧的相似度能达到设定阈值,判定二者为同一个人,进入步骤s2,否则判定为不是同一个人,结束;如图4所示包括:
[0114]
s11、用身份证读卡器读取用户的身份证信息,包括姓名,身份证号和身份证件照;
[0115]
s12、对所述身份证件照进行人脸检测,通过特征提取得到n维特征向量,记为features_1;
[0116]
本实施例中,通过face_recognition算法模型将所述身份证件照的人脸特征提取出n=128维特征向量,
[0117]
feature_1=array([-0.16499846,0.09575517,0.04623203,0.03399656,-0.07989036,
············
,-0.01364356,0.08971558,0.01900284]);
[0118]
face_recognition是深度学习算法库dlib里的人脸识别算法模型,包含人脸检测、人脸关键点检测、人脸识别等接口。其使用世界上最简单的人脸识别工具,在python或命令行中识别和操作人脸。使用dlib最先进的人脸识别技术构建而成,并具有深度学习功能。该模型在lfw人脸数据库(labeled faces in the wild)基准中的准确率为99.38%。
[0119]
s13、通过摄像头实时捕获用户的人脸,调取摄像头的视频流;
[0120]
s14、对所述视频流的当前帧进行人脸检测,通过特征提取得到n维特征向量,记为features_2;
[0121]
计算前,features_1与features_2已进行了归一化操作。本实施例中,也通过face_recognition算法模型将当前帧中检测到的人脸特征提取出n=128维特征向量,
[0122]
feature_2=array([-0.153552,0.120262,0.0191236,0.026432,-0.104621,-0.0100934,
············
,0.0794868,-0.00760809,0.137932,0.0470171])。
[0123]
s15、计算所述features_1与features_2的相似度,判断所述相似度是否达到设定阈值r,若是,则二者是同一个人,进入步骤s2,否则,进入步骤s16;
[0124]
本实施例中相似度通过计算所述features_1与features_2的欧式距离来评价,相似度达到设定阈值r时,即欧式距离小于等于设定阈值r时,n维欧式距离的计算公式如下:
[0125][0126]
其中xi表示features_1中第i维的值,yi表示features_2中第i维的值,i≤n,设定的相似度阈值r根据实际数据统计得来,r一般取[0.3,0.6],本实施例中,计算得到的d(x,y)为features_1和features_2这两个向量的欧式距离为0.34,设定阈值r为0.4,人证对比成功;
[0127]
s16、判断当前帧数是否小于等于设置的帧数阈值q,若是,则帧数加一,返回步骤s14,进行下一帧的人脸检测,更新features_2,否则,二者不是同一个人,结束人证对比,返回步骤s11。
[0128]
捕获的人脸因妆容、年龄、角度的差异,当前帧计算得到的相似度不满足要求,但下一帧的相似度有可能满足要求,因此应在q次计算得到的相似度判断完成后,才能得出不是同一个人的结论,所述帧数阈值q通过实验统计获得。
[0129]
s2、活体检测:确保用户是对应的生命体,即用户在规定时间内根据提示依次完成随机的p个活体检测动作,p≥3,获取人脸图像,根据所述活体检测模型判断所述活体检测动作的变化幅度是否符合对应的阈值,判断连续帧中的眨眼次数是否符合对应的阈值,若都满足,则活体检测成功,进入步骤s3,否则返回步骤s1;如图5所示包括:
[0130]
s21、加载所述活体检测模型,开启摄像头,j=1;
[0131]
s22、提示用户进行随机的第j个活体检测动作,记录动作时间;
[0132]
s23、判断所述动作时间是否超时,若是,则返回步骤s11进行人证对比,否则,进入步骤s24;
[0133]
此处加入了超时检测,确保自助检测的有序进行。
[0134]
s24、捕获连续2-3帧数据,通过所述活体检测模型得到连续两帧图像的人脸特征点坐标,记录眨眼次数,并计算当前活体检测动作的变化幅度,记为f,判断f是否符合对应的阈值,若是,则当前活体检测动作达标,j=j+1,进入步骤s25;否则仍重复当前动作,j不变,返回步骤s22;
[0135]
所述眨眼次数的记录方法包括:眨眼次数初始为零,计算连续两帧图像中眨眼动作的变化幅度,记为f,判断f是否符合对应的阈值d,若是,则眨眼次数加一,否则眨眼次数不变;其中,眨眼动作的判断条件为:连续两帧图像中眼睛的纵横比是否小于对应的阈值d,若是,则完成一次眨眼动作,眨眼次数加一,根据经验对应的阈值为0.2。
[0136]
s25、判断j是否大于3,若是,则随机的3个活体检测动作均已达标,进入步骤s26;否则,进行下一个活体检测动作的检测,返回步骤s22;
[0137]
s26、判断所述眨眼次数是否大于等于阈值dz,若是,则表示用户是活体,活体检测成功;否则,表示用户可能不是活体,返回步骤s11。
[0138]
通过活体检测动作的检测和眨眼次数的检测,双重确保是生命体正在进行自助操作,而不是图片、模型等,进一步确保身份确认的准确性。
[0139]
该活体检测在七个活体检测动作中随机选择三个进行检测,前一个动作检测达标
后才能进入下一个动作,否则重复当前动作,随机的三个动作均达标,且眨眼次数符合要求,以及未超时,则能充分证明用户为活体,活体检测通过,三个条件缺一则活体检测失败,返回人证对比环节。眨眼次数的阈值dz和超时判断的阈值均根据大量实验数据得到。所述七个活体检测动作包括抬头、低头、向左看、向右看、张嘴、点头和摇头,各活体检测动作的达标判断方法分别为:
[0140]
抬头:判断连续两帧图像欧拉角中的俯仰角变化的差值是否大于阈值,根据经验对应阈值为30
°
。
[0141]
低头:判断连续两帧图像欧拉角中的俯仰角变化的差值是否小于阈值,根据经验对应阈值为-30
°
。
[0142]
向左看:判断连续两帧图像欧拉角中的偏航角变化的差值是否小于阈值,根据经验对应阈值为-40
°
。
[0143]
向右看:判断连续两帧图像欧拉角中的偏航角变化的差值是否大于阈值,根据经验对应阈值为40
°
。
[0144]
张嘴:判断连续两帧图像上下外嘴唇的长宽比变化是否大于阈值,根据经验对应阈值为0.7,或上下内嘴唇的长宽比变化是否大于阈值,根据经验对应阈值为0.3。
[0145]
点头:判断连续两帧图像鼻子沿竖轴的比值变化是否大于阈值,根据经验对应阈值为0.03。
[0146]
摇头:判断连续两帧图像鼻子沿横轴的比值变化是否大于阈值,根据经验对应阈值为0.05。
[0147]
所述欧拉角是一种最直观的姿态描述方式,它的核心思想是一个坐标系到另一个坐标系的变换可以通过绕不同坐标轴的三次连续转动来实现,这三次的转动角度统一称为欧拉角。而欧拉角只是说明了两种坐标系之间的变换关系,实际上我们在姿态估计中使用的姿态角是欧拉角中的一种,是人为约定的一种。欧拉角的特定转动顺序为z-y-x,其中绕z轴转动的角度为偏航角(yaw),绕y轴转动的角度为俯仰角(pitch),绕x轴转动的角度为横滚角(roll)。
[0148]
s3、自助核酸采集动作检测:用户在规定时间内根据屏幕提示完成咽拭子的目标擦拭位置和目标擦拭次数,获取口腔图像,持续根据坐标计算方法或模型识别方法在所述咽拭子触碰到某一个目标擦拭位置且存在擦拭动作时,记录一次触碰到的所述目标擦拭位置的擦拭成功次数,直到所有目标擦拭位置的擦拭成功次数满足所述目标擦拭次数时,核酸采集动作合格,结束采集;如图6和图7所示包括:
[0149]
s31、加载模型及参数,开启摄像头,选择核酸采集动作标准,所述核酸采集动作标准包括咽拭子的目标擦拭位置和目标擦拭次数;
[0150]
由于目前各地的咽拭子核酸采集动作判断标准不一致,大致分为以下三种:
[0151]
标准一:左扁桃腺、右扁桃腺、咽后壁,三个点中任意一点(不限于一点),擦拭至少三次;
[0152]
标准二:左扁桃腺、右扁桃腺(无顺序要求),各擦拭至少三次;
[0153]
标准三:左扁桃腺、右扁桃腺、咽后壁,三个点(无顺序要求)各擦拭至少三次;
[0154]
因此三种标准分别作为核酸采集动作检测的要求不一样,根据选择或需要设定:
[0155]
采用标准一的核酸采集动作检测时,目标擦拭位置为左扁桃腺、右扁桃腺或咽后
壁,目标擦拭次数为左扁桃腺、右扁桃腺和咽后壁擦拭成功次数和大于等于3;
[0156]
采用标准二的核酸采集动作检测时,目标擦拭位置为左扁桃腺和右扁桃腺,目标擦拭次数为左扁桃腺的擦拭成功次数大于等于3且右扁桃腺的擦拭成功次数大于等于3;
[0157]
采用标准三的核酸采集动作检测时,目标擦拭位置为左扁桃腺和右扁桃腺和咽后壁,目标擦拭次数为左扁桃腺的擦拭成功次数大于等于3,右扁桃腺的擦拭成功次数大于等于3,且咽后壁的擦拭成功次数大于等于3。
[0158]
s32、屏幕提示咽拭子的目标擦拭位置和目标擦拭次数,记录操作时间;所述目标擦拭位置的擦拭成功次数初始为零,所述目标擦拭位置包括左扁桃腺、右扁桃腺和/或咽后壁;
[0159]
根据采用的核酸检测标准不同,所述目标擦拭位置和目标擦拭次数均不同,根据采用的核酸检测标准,设置目标擦拭位置和目标擦拭次数,即可适用于各标准的核酸检测。
[0160]
s33、判断所述操作时间是否超时,若是,则返回步骤s11进行人证对比,否则,进入步骤s34;
[0161]
所述操作时间的阈值根据经验为3分钟。
[0162]
s34、根据坐标计算方法或模型识别方法判断所述咽拭子是否触碰到某一个目标擦拭位置并存在擦拭动作,若是,则触碰到的所述目标擦拭位置对应的擦拭成功次数加一,进入步骤s35;否则,屏幕提示未完成情况,返回步骤s33;
[0163]
所述坐标计算方法如图6所示,包括以下步骤:
[0164]
s34a1、根据所述咽拭子口腔目标检测模型、咽拭子口腔关键点检测模型或所述核酸采集动作多任务分类模型,识别并计算出当前帧中的咽拭子、左扁桃体腺、右扁桃体腺及咽后壁的中心坐标,判断是否识别成功,若是,则进入步骤s34a2;否则,屏幕提示未规范处,返回步骤s33;
[0165]
s34a2、获取所述咽拭子的中心坐标和各目标擦拭位置的坐标关系,判断咽拭子是否触碰到某一个目标擦拭位置,若是,则触碰到该目标擦拭位置,进入步骤s34a3;否则,未触碰到任一目标擦拭位置,屏幕提示未完成情况,返回步骤s33;
[0166]
由于所述当前帧中的咽拭子、左扁桃体腺、右扁桃体腺及咽后壁的中心坐标根据核酸采集动作检测模型选择的不同,步骤s34a1识别模型后计算得到坐标的方法不同,步骤s34a2由此计算的坐标关系的方法也不同,因此,步骤s34a1和s34a2分以下两种情况:
[0167]
(1)使用咽拭子口腔目标检测模型时:
[0168]
s34a1a、先通过所述咽拭子口腔目标检测模型或任务二为咽拭子口腔目标检测模型的所述核酸采集动作多任务分类模型,获取各目标的边界框坐标,即咽拭子、左扁桃体腺、右扁桃体腺或咽后壁的左上角及右下角的坐标,如表1所示,单位为像素,本实施例的图像的一个像素大约为0.078毫米;并通过各目标的边界框坐标计算得到每个目标的中心坐标,如表2所示,中心坐标(x,y)计算公式:
[0169]
x=(x
end-x
start
)/2
[0170]
y=(y
end-y
start
)/2
[0171]
其中(x
end
,y
end
)表示边界框右下角坐标,(x
start
,y
start
)表示边界框左上角坐标;
[0172]
表1咽拭子口腔目标检测模型得到的咽拭子、左扁桃体腺、右扁桃体腺或咽后壁的边界框坐标(单位:像素)
[0173] 左上角x坐标左上角y坐标右下角x坐标右下角y坐标咽拭子70.30707106.5621469113.6642124.781925左扁桃体腺67.93496100.847599.82682140.6486右扁桃体腺199.1924102.998868227.9214144.9514165咽后壁127.765192.51073857160.7113123.9751474
[0174]
表2咽拭子口腔目标检测模型得到的咽拭子、左扁桃体腺、右扁桃体腺或咽后壁的中心坐标(单位:像素)
[0175] x坐标y坐标咽拭子中心点91.98564115.672左扁桃体腺中心点83.88089120.748右扁桃体腺中心点213.5569123.9751咽后壁中心点144.2382108.2429
[0176]
s34a2a、根据s34a1a得到的坐标,比较判断咽拭子的中心坐标是否在所述目标擦拭位置对应的边界框内,若是,则擦拭到该目标擦拭位置,否则,未擦拭到任一目标擦拭位置。
[0177]
例如,咽拭子中心坐标记为(xs,ys),左扁桃体腺边界框坐标记为(x
start
,y
start
,x
end
,y
end
),当满足判别式x
start
≤xs≤x
end
,y
start
≤ys≤y
end
时,表示咽拭子触碰到左扁桃体腺。
[0178]
如根据表1和表2数据,将咽拭子中心坐标与左扁桃体腺边界框做比较,发现左扁桃体腺边界框左下角x坐标《咽拭子中心x坐标《左扁桃体腺边界框右下角x坐标,左扁桃体腺边界框左下角y坐标《咽拭子中心y坐标《左扁桃体腺边界框右下角y坐标,说明咽拭子在左扁桃体腺的边界框内,以此类推。
[0179]
(2)使用咽拭子口腔关键点检测模型时:
[0180]
s34a1b、直接通过所述咽拭子口腔关键点检测模型或任务二为咽拭子口腔关键点检测模型的所述核酸采集动作多任务分类模型得到咽拭子、左扁桃体腺、右扁桃体腺或咽后壁的中心坐标,咽拭子的中心坐标即所述咽拭子头的中心点坐标,咽后壁的中心坐标即所述扁桃体的中心点坐标。如表3所示:
[0181]
表3咽拭子口腔关键点检测模型得到的咽拭子、左扁桃体腺、右扁桃体腺或咽后壁的中心坐标(单位:像素)
[0182][0183][0184]
s34a2b、根据s34a1b得到的坐标,先分别计算左扁桃腺中心坐标(x1,y1)、右扁桃
腺中心坐标(x3,y3)、咽后壁中心坐标(x4,y4)到咽拭子中心坐标(x2,y2)之间的距离,分别记为ρ1、ρ2、ρ3,计算距离的公式可选用欧式距离、曼哈顿距离、切比雪夫距离、闵氏距离、标准化欧式距离、余弦相似度、马氏距离、汉明距离、巴氏距离、杰卡德相似度系数、相关系数与相关距离、信息熵,其中计算两点之间的距离最常用的为欧氏距离,计算公式如下:
[0185][0186]
再取min{ρ1,ρ2,ρ3}与事先设置好的距离阈值dy(这个阈值dy需要根据大量实际数据取均值得来)进行比对,分两种情况:
[0187]
当min{ρ1,ρ2,ρ3}》dy时,表示咽拭子头离左、右扁桃腺和咽后壁距离都很远,未触碰到任一目标擦拭位置;
[0188]
当min{ρ1,ρ2,ρ3}≤dy时,表示触碰到某一目标擦拭位置,且触碰到min{ρ1,ρ2,ρ3}对应的目标擦拭位置,又分三种情况:
[0189]
且当min{ρ1,ρ2,ρ3}=ρ1时,表示咽拭子头在触碰左扁桃腺;
[0190]
且当min{ρ1,ρ2,ρ3}=ρ2时,表示咽拭子头在触碰右扁桃腺;
[0191]
且当min{ρ1,ρ2,ρ3}=ρ3时,表示咽拭子头在触碰咽后壁。
[0192]
如根据表3数据,计算得到的ρ1=13.435338272630128,ρ2=149.4996088139364,ρ3=67.81337414581286,假设dy=30,发现ρ1《dy说明咽拭子头触碰到了做左扁桃腺,记录下此次触碰的位置(左扁桃腺)并且记录ρ1,ρ1,ρ3这三个值。
[0193]
s34a3、获取连续m帧中咽拭子与各目标擦拭位置的距离,计算每两帧中对应距离的差值,判断各距离差值中的最大值是否大于阈值dx,若是,则表示咽拭子是动态的,即咽拭子有擦拭动作,步骤s34a2a或s34a2b触碰的所述目标擦拭位置对应的擦拭成功次数加一,进入步骤s35;否则,表示咽拭子不是动态的,即咽拭子无擦拭动作,屏幕提示未完成情况,返回步骤s33;
[0194]
若咽拭子与左扁桃体腺、右扁桃体腺、咽后壁的距离差值分别为d1、d2、d3,则判断max{d1,d2,d3}是否大于阈值dx即可,若目标擦拭位置没有咽后壁,则认为d3为零,咽后壁的擦拭成功次数始终为零。
[0195]
因口腔难以检测,获取的连续两帧图像中可能出现未检测成功的情况,因此获取连续m帧图像,m≥2,m通过实际情况统计得出。例如,计算当前帧中咽拭子中心点到左扁桃体腺中心点、右扁桃体腺中心点及咽后壁中心点的距离,并保存留着下一帧计算距离差值时使用:咽拭子中心点到左扁桃体腺中心点距离记为:x1=9.56;咽拭子中心点到右扁桃体腺中心点距离记为:x2=121.85;咽拭子中心点到咽后壁中心点距离记为:x3=52.77;
[0196]
从上一帧保存下来的距离数据为:咽拭子中心点到左扁桃体腺中心点距离记为:y1=60.09;咽拭子中心点到右扁桃体腺中心点距离记为:y2=50.56;咽拭子中心点到咽后壁中心点距离记为:y3=30.43;
[0197]
计算两帧之间的距离差值的绝对值:咽拭子与左扁桃体腺距离差值记为:d1=50.53;咽拭子与右扁桃体腺距离差值记为:d2=71.29;咽拭子与咽后壁距离差值记为:d3=22.34;
[0198]
这里距离差阈值设为dx=20,因为max{d1,d2,d3}》dx,所以判断为咽拭子有擦拭动作。这里成功检测动作数加1。
[0199]
所述模型识别方法也包括采用所述核酸采集动作分类模型或所述核酸采集动作
多任务分类模型两种情况,如图7所示,具体为:
[0200]
s34b1、根据所述核酸采集动作分类模型或所述核酸采集动作多任务分类模型识别核酸采集动作的分类结果,判断是否识别成功,若是,则进入步骤s34b2;否则,屏幕提示未完成情况,返回步骤s33;
[0201]
模型输出的分类结果包括四种:0:未触碰到目标擦拭位置,1:触碰到左扁桃体腺,2:触碰到右扁桃体腺,3:触碰到咽后壁;定义0为假,1、2、3为真。
[0202]
由于咽拭子的触碰位置不好掌控,且咽拭子是动态、来回移动的,一次有效的擦拭是先未触碰到,再触碰到,再移开,因此有效擦拭时的各帧分类结果应包含“假真假”、“假真真
···
真假”,识别的各帧的分类结果中必定先“假真”,再“真假”,两个假之间至少有一个真;若全是假,则必定未触碰到目标擦拭位置,若全是真、先真后全假或先假后全真,则咽拭子没动,没有擦拭动作;因此,具体步骤为:
[0203]
s34b2、判断是否“当前帧u的分类结果为真,且上一帧u-1的分类结果为假”,若是,则进入步骤s34b3,否则,令u=u+1,判断当前帧数是否达到帧数阈值,若是,则屏幕提示未完成情况,返回步骤s33;否则重新进入步骤s34b2;
[0204]
先寻找“假真”,若当前帧数达到帧数阈值也未找到,则一直是假,停止寻找,返回步骤s33,若当前帧数未达到帧数阈值,则向后移动一帧。
[0205]
s34b3、判断是否“当前帧u的分类结果为真,且下一帧u+1的分类结果为假”,若是,则进行了一次有效擦拭动作,所述真对应的目标擦拭位置的擦拭成功次数加一,令u=u+2,进入步骤s35;否则,令u=u+1,判断当前帧数是否达到帧数阈值,若是,则屏幕提示未完成情况,返回步骤s33;否则重新进入步骤s34b3;
[0206]
再寻找“真假”,若当前帧数达到帧数阈值也未找到,则前面全是假,后面全是真,未进行动作停止寻找;寻找到“真假”后,若令u=u+1,已知此时的当前帧u为假,循环到s34b2时判断结果必定不满足“当前帧u的分类结果为真”,需要再次令u=u+1后进行判断,为节省运算量,寻找到“真假”后,令u=u+2。
[0207]
因先寻找到“假真”,再寻找到“真假”,真说明已触碰到某一个目标擦拭位置,真前的假和真后的假,说明咽拭子是运动的,存在擦拭动作。
[0208]
s35、判断所有目标擦拭位置的擦拭成功次数是否满足所述目标擦拭次数,若是,则核酸采集动作合格,结束采集;否则,屏幕提示未完成情况,返回步骤s33。
[0209]
用户一直根据屏幕提示进行动作,视觉采集装置持续采集视频流,程序也在持续运行,若未超时,且未完成所述目标擦拭次数,则以当前帧若未满足所述目标擦拭次数的要求,提示未完成情况的同时,返回步骤s33,若还未超时,对更新后的当前帧重复s34的识别判断,继续识别循环。
[0210]
最后需要说明的是,上述的方法可以转换为软件程序指令,既可以使用包括处理器和存储器的装置来运行实现,也可以通过非暂态计算机可读存储介质中存储的计算机指令来实现。上述以软件功能单元的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能单元存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施例所述方法的部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种
可以存储程序代码的介质。
[0211]
本发明还公开了实施例为一种基于人工智能的自助核酸采集装置,包括控制模块,以及分别与所述控制模块连接的身份证读卡器、视觉采集装置、屏幕和存储模块,所述身份证读卡器用于读取身份证信息,所述视觉采集装置用于捕获用户的人脸和口腔图像,数量至少有一个;所述存储模块用于存储构建好的所述活体检测模型和核酸采集动作检测模型及其参数,以及采集的视频流,所述控制模块运行所述的基于人工智能的自助核酸采集方法。
[0212]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;虽然结合附图描述了本发明的实施方式,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下做出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1