一种视觉退化条件下的低光照图形增强方法
1.本发明涉及图像数据处理技术领域,尤其是,本发明涉及一种视觉退化条件下的低光照图形增强方法。
背景技术:
2.在光线不足和视觉条件恶化(如极端微光、雾、雾)不符合相机设置的黑暗场景中,实现良好的拍摄效果是一个巨大的挑战,在这些恶劣条件下,摄像头从黎明到黄昏的工作状态面临着严重的差异性的问题。
3.在过去二十年中,计算机视觉界见证了在各种环境条件下改善微光图像质量的巨大进步,现在对于低光照条件下的拍照图像进行增强的方法有很多,一些方法需要精心设计的大规模数据集,而另一些方法则依赖成对的训练数据,捕获图像对和选择大规模数据阻碍了实际应用。同时,还有人提出了基于学习的背光图像恢复(lbr)和多视点高动态范围成像方法,将输入图像分为前照区域和背光区域,这是一个计算复杂的过程。以及传统的基于retinex的方法,如robust retinex model(rrm) deep retinex将图像分割为反射和光照,但产生不一致的反射。这些方法的后续,如kind和dark to bright view (d2bv-net),都依赖于图像对。此后,几乎所有的方法都遵循主要趋势,依赖于图像对、先验和仔细选择的数据。
4.上述这些图像增强方式都存在以下问题,考虑到真实的低光照图像增强方法必须具有鲁棒性、快速性、计算效率,并且能够在不依赖输入数据的情况下工作,以上方法的模型容量在很大程度上依赖于训练数据、合成图像和伽马校正等的类型,收集此类数据是一项不切实际且繁琐的任务,除了计算复杂性外,还增加了对输入训练数据的依赖性,总之,这些方法都是以牺牲速度、内存和数据类型为代价,侧重于提高质量,在现实上适用性较低。
5.因此为了解决上述问题,设计一种合理的视觉退化条件下的低光照图形增强方法对我们来说是很有必要的。
技术实现要素:
6.本发明的目的在于提供一种可行度高,通过从输入图像中分离出高频反射分量,并利用其最大通道来改善网络延迟并最小化计算复杂度,达到了以最小的延迟和计算复杂度,改善退化视觉条件下的视觉质量的目的,不依赖于配对、先验或大规模仔细的数据设计,在各种现实使用方面具有优越性和适用性的视觉退化条件下的低光照图形增强方法。
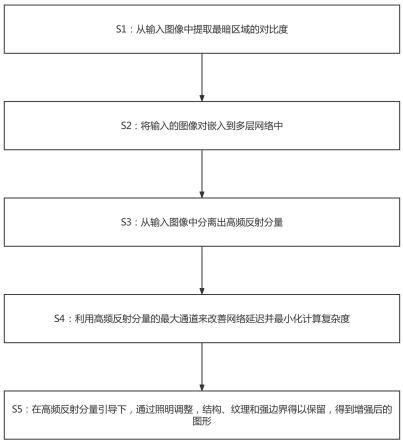
7.为达到上述目的,本发明采用如下技术方案得以实现的:一种视觉退化条件下的低光照图形增强方法,包括以下步骤:s1:从输入图像中提取最暗区域的对比度;s2:获取输入图像的立体图像对,将立体图像对嵌入到多层网络中,多层网络由卷积层初始化输入图像的特征,然后应用具有卷积层的校正线性单元,将特征串联起来得到
输入图像的特征点集;s3:从输入图像中分离出高频反射分量;s4:利用高频反射分量的最大通道来改善网络延迟并最小化计算复杂度;s5:在高频反射分量引导下,通过照明调整对输入图像的特征点进行校正,并对结构、纹理和强边界进行保留,得到增强后的图形。
8.作为本发明的优选,执行步骤s1时,对输入图像应用全局光透射“a”,其中,“a”是输入图片i(x)的明亮通道中最暗像素的0.1%的估计值。
9.作为本发明的优选,执行步骤s3时,使用校正线性单元应用单个卷积层,最后应用tanh激活函数来绑定反射和光照特征。
10.作为本发明的优选,执行步骤s5时,在高频反射分量引导下,对以输入图像特征点为中心的面片中的亮度强度进行定义,输入至r、g、b通道,块大小为3
×
3,对输入图像的特征点进行校正。
11.作为本发明的优选,执行步骤s2时,多层网络采用深入黑暗策略,在深入黑暗的多层网络(例如d2d网络)的帮助下,输入图像被分为反射和光照分量,依靠不适应图像分解来独立处理结构和纹理扭曲;执行步骤s3时,允许限制反射的最大通道,视为高频反射分量;执行步骤s4时,通过高频反射分量实现自适应光照引导,实现视觉平滑度的平衡,利用高频反射分量的最大通道进行损耗调整,将显著限制饱和,以改善极端黑暗和退化视觉条件下的视觉平滑度和对比度。
12.作为本发明的优选,执行步骤s2时,深入黑暗的多层网络包含若干个拆分操作。
13.作为本发明的优选,执行步骤s2时,深入黑暗的多层网络包含若干组卷积层和校正线性单元,进行特征提取并且串联起来。
14.作为本发明的优选,执行步骤s2时,计算深入黑暗的多层网络的损失函数,改善不适应图像分解的网络延迟和平滑度。
15.作为本发明的优选,执行步骤s4时,使用adam-optimizer算法进行训练网络。
16.本发明一种视觉退化条件下的低光照图形增强方法有益效果在于:可行度高,通过从输入图像中分离出高频反射分量,并利用其最大通道来改善网络延迟并最小化计算复杂度,达到了以最小的延迟和计算复杂度,改善退化视觉条件下的视觉质量的目的,不依赖于配对、先验或大规模仔细的数据设计,在各种现实使用方面具有优越性和适用性。
附图说明
17.图1为本发明一种视觉退化条件下的低光照图形增强方法的流程示意图。
具体实施方式
18.以下是本发明的具体实施例,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
19.现在将参照附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的模块和结构的相对布置不限制本发明的范围。
20.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明
及其应用或使用的任何限制。
21.对于相关领域普通技术人员已知的技术、方法及系统可能不作详细讨论,但在适当情况下,技术、方法及系统应当被视为授权说明书的一部分。
22.实施例一:如图1所示,仅仅为本发明的其中一个的实施例,一种视觉退化条件下的低光照图形增强方法,包括以下步骤:s1:从输入图像中提取最暗区域的对比度;对输入图像应用全局光透射“a”;如公式(1)所示:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中“a”是输入图片i(x)的明亮通道中最暗像素的0.1%的估计值;r
x
为输入图像的反射分量,t
x
为输入图像的光照分量(注意,由于公式中的编辑规则,公式中的r
(x)
实际就是r
x
;同理的,公式中的t
(x)
实际就是t
x
)。
23.s2:将输入的图像对嵌入到多层网络中,其中多层网络由一组卷积层(大小最好为3
×
3)初始化入图像的特征,然后应用具有一组卷积层(3
×
3)的校正线性单元(relu),将特征串联起来;s3:从输入图像中分离出高频反射分量;使用校正线性单元应用单个卷积层,最后应用tanh激活函数来绑定反射和光照特征;如公式(2)所示。
24.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)s4:利用高频反射分量的最大通道来改善网络延迟并最小化计算复杂度;在这里,表示最大通道式子如下:。
25.s5:在高频反射分量引导下,通过照明调整,结构、纹理和强边界得以保留,得到增强后的图形。
26.在这里对于高频反射分量,以输入图像特征点x为中心的面片ω(x)中的亮度强度进行定义,输入至r、g、b通道,其中面片ω(x)的块大小为3
×
3像素,对输入图像的特征点进行校正,亮度强度定义如下:
ꢀꢀꢀꢀ
(3)退化视觉条件下的图像共享所有8位图像的t,可以估计为:
ꢀꢀꢀꢀꢀꢀ
(4)基于上述过程,再提出了两个权重函数来约束不适应图像分解等式(2):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)其中ζ= 1,反射增强参数和照明传播参数将分解更新为乘积,分别改善了不适应图像分解的网络延迟和平滑度。
27.将两个权重函数约束下的反射分量r
x
和光照分量t
x
代入计算,最后求得的所有特
征点的亮度强度定义,就可以校正得到增强后的图像。这样最后得到增强后的图形,不仅可以以较小的延迟和计算复杂度,改善退化视觉条件下的视觉质量,结构、纹理和强边界得以保留。
28.本发明一种视觉退化条件下的低光照图形增强方法可行度高,通过从输入图像中分离出高频反射分量,并利用其最大通道来改善网络延迟并最小化计算复杂度,达到了以最小的延迟和计算复杂度,改善退化视觉条件下的视觉质量的目的,不依赖于配对、先验或大规模仔细的数据设计,在各种现实使用方面具有优越性和适用性。
29.实施例二:仍如图1所示,仅仅为本发明的其中一个的实施例,在实施例一的基础上,本发明一种视觉退化条件下的低光照图形增强方法中,在执行步骤s2时,为了使得多层网络对图像对进行更好的特征提取,最好是将多层网络采用深入黑暗策略,即使用深入黑暗的多层网络(例如d2d网络)。
30.这样,在深入黑暗的多层网络(d2d网络)的帮助下,输入图像i
x
被分为反射r
x
和光照t
x
分量,依靠不适应图像分解来独立处理结构和纹理扭曲。它允许限制反射的最大通道,将其视为高频反射分量,以改善延迟,通过高频反射分量实现自适应光照引导,实现视觉平滑度的平衡。随后利用前高频反射分量的最大通道进行损耗调整,将显著限制饱和,以改善极端黑暗和退化视觉条件下的视觉平滑度和对比度。
31.那么采用深入黑暗策略下,在执行步骤s2时,深入黑暗的多层网络包含若干个拆分操作,深入黑暗的多层网络可以拆分多组卷积。一组卷积层(3
×
3)初始化了输入图像的特征提取。接下来,应用具有一组卷积层(3
×
3)的校正线性单元(relu),并将特征串联起来。使用校正线性单元(relu)应用另一个卷积层堆栈,并应用另一个卷积层堆栈。接下来,使用校正线性单元(relu)应用单个卷积层,最后应用tanh激活函数来绑定反射和光照特征。一个带有卷积层和tanh激活函数的简单网络可以在建议策略的指导下产生显著的结果,并且能够以自我监督的方式运行。
32.并且,执行步骤s2时,深入黑暗的多层网络包含若干组卷积层和校正线性单元(relu),进行特征提取并且串联起来。
33.另外,为了使得深入黑暗策略下的多层网络计算更加精确,还需要计算深入黑暗的多层网络的损失函数:;其中用于图像形成损失,估计如下:;以及在中引入了一个可持续的权衡参数(即ψ =
ꢀ‑
10),用于可观测制导的直接控制,光明调整损失为l1范数,其中,,,反射增强参数和照明传播参数将分解更新为乘积,分别改善了不适应图像分解的网络延迟和平滑度。
34.最后,使用adam-optimizer和反向传播对上述深入黑暗的多层网络进行训练,学习速率为1e
−
3,其中批处理大小为16,块大小为50个epoch的128x128,当然可以只使用少量输入图像进行训练,无需仔细选择,实验数据为:使用480对图片的总训练时间几乎为1分钟。
35.实施例三、仍如图1所示,仅仅为本发明的其中一个的实施例,在上述任一实施例的基础上,本发明一种视觉退化条件下的低光照图形增强方法中,结合实验评估对本方法进一步描述:相比与其他低光照图像增强方法,从峰值信噪比(psnr)、结构相似性指数测度(ssim)以及学习的感知图像块相似性(lpips)等数据方面,与已有的图像增强方法包括高分辨率光学增幅(kind)、lbr、slime 、深度图像增强deep retinex、多分支弱光增强网络(mbllie)、glad-net、dilligent
ꢀ‑
gan、zero-dce、retinex启发的展开先前模型(ruas)、beyond brighting low light image(bblli)以及dark to bright view(d2bv)方法,在数据集uxov和lol上进行实验比较。
36.且从表1可以看出,本发明方法获得了峰值信噪比(psnr)和结构相似性指数测度(ssim)中最好的数值分数。
37.除此之外,从表2可以看出,我们还演示了竞争对手方法对数据集的依赖性,本发明方法的学习感知图像块相似性(lpips)值最低,即本发明提出的方法不依赖于配对、先验或大规模仔细的数据设计。
38.综上,本发明一种视觉退化条件下的低光照图形增强方法改善退化视觉条件下的视觉质量高,且不依赖于配对、先验或大规模仔细的数据设计,在各种现实使用方面具有优越性和适用性。
39.表1. uxov-dataset上的客观评价、psnr和ssim与各种方法的比较表 2. 对lol数据集图像的客观质量比较,以及各种最新方法的依赖性本发明一种视觉退化条件下的低光照图形增强方法可行度高,通过从输入图像中分离出高频反射分量,并利用其最大通道来改善网络延迟并最小化计算复杂度,达到了以最小的延迟和计算复杂度,改善退化视觉条件下的视觉质量的目的,不依赖于配对、先验或
大规模仔细的数据设计,在各种现实使用方面具有优越性和适用性。
40.本发明不局限于上述具体的实施方式,本发明可以有各种更改和变化。凡是依据本发明的技术实质对以上实施方式所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1