基于AIS数据的船舶异常状态检测方法
基于ais数据的船舶异常状态检测方法
技术领域
1.本发明属于船舶异常状态检测技术领域,尤其涉及基于ais数据的船舶异常状态检测方法。
背景技术:
2.传统海运安全主要依靠船员和安全管理人员的经验操作,并辅助以雷达、电子海图、超声、视频等技术做出安全预判。这种安全保障方式对操作人员的依赖度太高,人员失误或操作经验不足可能造成严重安全事故,研究表明,80%海事事故由人为因素造成,可见,海运安全必须降低对人力经验的依赖,研究船舶异常状态检测并自动做出预判可在一定程度上减少人工干预。国际海事组织为了保障船舶安全航行,要求所有300总吨及以上的国际航行船舶,500总吨及以上的非国际航行船舶,以及所有客船都必须配备一台ais系统,ais系统可以方便海事监管部门和船舶进行信息交互,掌握船舶行状态。随着 ais数据的不断积累,现已形成非常庞大的数据集。ais系统的完善为船舶轨迹大数据挖掘和异常检测奠定了坚实的基础。
3.传统ais系统创建的船舶和岸基之间的信息交换网络因为通信距离的局限性而无法覆盖到距离海岸较远的船舶,并且ais系统数据传输受船舶分布状态的影响较大。因此卫星ais技术应用而生,卫星 ais自动识别系统主要由卫星、船上转发器设备、卫星地面站、数据处理与分发系统组成。据不完全统计,目前在轨的卫星数量约有250 颗左右,卫星ais系统为实时船舶数据监控提供了可能,通过挖掘历史ais数据信息,结合实时卫星ais数据判断当前船舶的行为是否会有安全风险,并实时做出预防,避免意外事故发生是保障船舶安全航行的重要研究方向。
4.近年来,ais数据的价值被不断挖掘,依托ais数据已经诞生了很多研究成果,如船舶航迹规划、船舶轨迹预测、船舶避障、行为识别。船舶异常状态检测主要对船舶航行数据信息进行分析,判断船舶行驶状态是否正常,进而对船舶安全做出判断。本发明在ais数据快速积累和人工智能应用技术高速发展的背景下提出,借助卫星ais系统来研究船舶异常状态实时检测。通过智能算法来检测船舶轨迹异常可降低人工带来的失误,在保障船舶安全航行方面具有重要的现实意义。
技术实现要素:
5.本发明的目的在于提出基于ais数据的船舶异常状态检测方法,实时监测船舶航行状态,自动发现异常并及时做出预警,可有效降低安全监管对人力的依赖,在保障船舶安全航行和海运贸易繁荣发展方面具有重要意义。
6.为实现上述目的,本发明提供了基于ais数据的船舶异常状态检测方法,包括以下步骤:
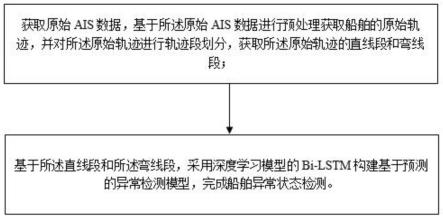
7.获取原始ais数据,基于所述原始ais数据进行预处理获取船舶的原始轨迹,并对所述原始轨迹进行轨迹段划分,获取所述原始轨迹的直线段和弯线段;
8.基于所述直线段和所述弯线段,采用深度学习模型的bi-lstm构建基于预测的异常检测模型,完成船舶异常状态检测。
9.可选的,所述预处理包括:对所述原始ais数据进行数据清理、插值处理和轨迹提取;
10.所述数据清理将对所述原始ais数据进行异常信息删除,获取轨迹数据信息;
11.所述插值处理根据时间差对缺失轨迹点进行插值;
12.所述轨迹提取对所述单个航船的航行轨迹进行船舶单条轨迹提取。
13.可选的,所述船舶单条轨迹提取方法包括:
14.(1)对tra轨迹按照时间戳排序;
15.(2)遍历查找ais数据中的船舶状态为1的轨迹点pi;
16.(3)从pi开始遍历寻找航行状态为0的轨迹点直到遇到下一个航行状态为1的轨迹点pj,将从pi到pj的轨迹点所组成的轨迹作为一单向轨迹进行保存,并为其插入唯一的轨迹标识traid。
17.(4)从pj开始遍历轨迹点,重复步骤(3)过程,直到所有的单向轨迹提取完成。
18.可选的,所述轨迹段划分包括dp算法、聚类算法和核密度估计;
19.所述dp算法将所述船舶轨迹进行压缩处理,获取压缩阈值,采用道格拉斯-普克算法将转弯轨迹点保留的比较密集;
20.所述聚类算法将所述船舶轨迹的转弯点进行聚类处理,获取最大半径和最小点数量,将压缩后轨迹划分出转弯段和直线段;
21.所述核密度估计根据压缩后的轨迹估计出未压缩轨迹的转弯段和直线段。
22.可选的,采用高斯核密度函数进行核密度估计,提取转弯轨迹段和直线轨迹段,计算如下:
[0023][0024]
式中:μ为轨迹数据均值,σ为轨迹数据的标准差。
[0025]
可选的,对输入数据进行均值方差归一化处理,通过处理,数据会映射到标准正态分布n(0,1)的固定区间,更有利于模型进行参数训练;
[0026][0027]
式中:x
scale
为归一化之后的值,μ为数据的平均值,s为数据的标准差。
[0028]
预测模型归属于回归问题,选择的损失函数为均方根误差(mase),其表达式为式,
[0029][0030]
可选的,对归一化后的数据进行反归一化处理,获取定量误差;
[0031][0032]
可选的,采用bi-lstm构建基于预测的异常检测模型包括:
[0033][0034]
式中,u
→
和w
→
是前向lstm的权重矩阵,b
→
是前向lstm的偏倚向量;
[0035][0036]
式中,u
←
和w
←
是反向lstm的权重矩阵,b
←
是反向lstm的偏倚向量;
[0037][0038]
本发明技术效果:本发明公开了基于ais数据的船舶异常状态检测方法,实时监测船舶航行状态,自动发现异常并及时做出预警,可有效降低安全监管对人力的依赖,在保障船舶安全航行和海运贸易繁荣发展方面具有重要意义;本发明使用卫星通信和4g通信将船舶的 ais数据发送到服务器,服务器来判断当前船舶是否行驶在正常状态下,并将判断结果传送给监管人员和船员,如果为异常状态会将会触发异常报警系统,提醒船员和监管人员及时做出防控。
附图说明
[0039]
构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
[0040]
图1为本发明实施例基于ais数据的船舶异常状态检测方法的流程示意图。
具体实施方式
[0041]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
[0042]
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
[0043]
如图1所示,本实施例中提供基于ais数据的船舶异常状态检测方法,包括以下步骤:
[0044]
获取原始ais数据,基于所述原始ais数据进行预处理获取船舶的原始轨迹,并对所述原始轨迹进行轨迹段划分,获取所述原始轨迹的直线段和弯线段;
[0045]
基于所述直线段和所述弯线段,采用深度学习模型的bi-lstm构建基于预测的异常检测模型,完成船舶异常状态检测。
[0046]
数据清理
[0047]
下载得到的开源ais数据包括了美国沿海水域的所有记录,本发明提取了苏必利尔湖内经苏圣玛丽到其他港口的三个月轨迹数据作为研究对象。通过谷歌地图的拾取坐标系统确定研究区域的经纬度范围,然后以此范围从ais数据中提取出原始轨迹。但该原始ais数据中因为通信问题或后期数据处理失误存在一些明显错误数据,这些错误数据会对后文异常检测研究造成未知影响,因此本发明首先对这些明显错误数据进行删除,主要包括:
[0048]
(1)位置超出经纬度范围的数据。包括纬度范围不在-90
°
到+90
°
之间的数据以及
经度范围不在-180
°
到+180
°
之间的数据;
[0049]
(2)速度小于0的数据;
[0050]
(3)轨迹点时间差大于3600s的数据。虽然后文会对数据进行插值处理,但是,当数据丢失过多的时候,插值算法无法进行轨迹补全,所以,本发明将数据丢失过多的数据标记为异常,进行删除;
[0051]
(4)重复的数据。重复数据是指ais前后数据完全一样的数据。
[0052]
(5)删除ais数据中无用信息数据,如船舶长度、宽度、吃水深度、船舶名称等数据。
[0053]
插值处理
[0054]
因为ais数据中存在数据丢失和长时间间隔的数据缺省情况,如果直接用于后续算法模型,容易造成计算误差,不易于信息挖掘和模型训练,所以需对提取的轨迹数据的位置和速度进行插值处理。对于船舶轨迹tra={p1,p2…
,pn},数据缺省情况依靠时间差进行判断,如果轨迹点pi和pj的时间差大于180秒,则在轨迹点pi和pj之间存在缺省需要进行插值,进行插值之前要计算出插值点的个数,本发明以 90秒为单个轨迹点的时间间隔进行插值点个数计算,计算公式如为式。
[0055][0056]
应用于船舶轨迹插值,为衡量何种插值算法更适用于船舶轨迹,本发明随机选取10条无需插值的直线轨轨迹段和10条无需插值的转弯轨迹段,并人工剔除部分轨迹点以制造出时间间隔,分别使用上述三种插值算法进行插值,计算插值后的数据与人为剔除轨迹点之间的误差和,得到直线轨迹段的误差结果如表2-1所示,转弯轨迹段的误差结果如表2-2所示。
[0057]
表2-1
[0058][0059]
表2-2
[0060][0061]
对比可以发现直线行驶过程中,三种插值算法插值后的误差都比较小,但是在转
弯部分,拉格朗日插值算法的误差明显小于线性插值和均值插值。可见均值插值法和线性插值法应用于变化平稳的轨迹中具有较好效果,但当数据存在较为剧烈的变化时,插入值的误差较大。拉格朗日插值法的多项式计算可以更好的非线性插入数据,在直线轨迹段和转弯轨迹段处都有更好的表现,因此本发明采用拉格朗日插值算法。
[0062]
轨迹提取
[0063]
通过ais数据的mmsi标识可以提取到单个船舶的航行轨迹,但在三个月内,该船舶可能会多次经过研究水域,导致提取到的船舶轨迹并不是单一轨迹。为方便后文进行数据挖掘和算法模型的应用,需进一步提取船舶轨迹,船舶运行状态主要包括:航行、锚泊、失控、操作受限、吃水受限、靠泊、搁浅,船舶航行的轨迹数据应该从锚泊状态开始,经过航行状态和其他可能异常状态,然后在锚泊状态结束,船舶的这一特征可被用来提取船舶单向航行轨迹。
[0064]
假设某一条根据mmsi标识提取的船舶ais数据为:tra= {p1,p2...,pn},其中p包含了ais的时间、船舶经度、船舶纬度、对地航向、对地速度和船舶状态信息,则船舶单条轨迹提取的步骤如下:
[0065]
(1)对tra轨迹按照时间戳排序;
[0066]
(2)遍历查找船舶状态(status)为1的轨迹点pi;
[0067]
(3)从pi开始遍历寻找航行状态为0的轨迹点直到遇到下一个航行状态为1的轨迹点pj,将从pi到pj的轨迹点所组成的轨迹作为一单向轨迹进行保存,并为其插入唯一的轨迹标识traid。
[0068]
(4)从pj开始遍历轨迹点,重复步骤(3)过程,直到所有的单向轨迹提取完成。将mmsi等于316018031的轨迹依据traid提取,可得到四条轨迹。
[0069]
轨迹段划分
[0070]
本部分主要对提取的船舶轨迹进行轨迹段划分,因为以整体轨迹进行异常检测,容易忽略船舶的局部变化细节,从而导致船舶轨迹异常状态检测不够精确。目前轨迹多采用网格方式划分,但网格划分需要考虑网格大小,网格过小容易造成船舶信息碎片化,且数据分析计算复杂度高,网格过大又容易忽略轨迹的局部变化细节。本发明采用道格拉斯-普克算法处理船舶轨迹,使船舶轨迹的转弯部分轨迹点密集而直线部分轨迹点稀疏,然后使用dbscan聚类算法和核密度估计将轨迹的转弯段和直接段进行分割来划分轨迹段。
[0071]
dp算法
[0072]
dp算法是一种经典的数据精简算法,在船舶轨迹数据处理中常用于数据压缩,使庞大的船舶轨迹数据能够保存主要骨架,去除重复冗余数据,提高数据信息挖掘效率。本发明利用dp算法精简数据原理,使船舶轨迹形状更易于密度聚类。dp算法通过比较设定的阈值 threshold与点到首尾轨迹点相连接线段的最大距离dmax,来进行轨迹压缩,算法的主要执行过程:
[0073]
(1)假设船舶轨迹tra由一系列轨迹点pi组成,tra= {p1p2......p
11
p
12
},将轨迹的第一个点p1和最后一个轨迹点p
12
连成一条线,标记该线段为p1p
12
,并给出threshold值为p9到线段p1p
12
的距离,p4到p1p
12
的距离为dmax。
[0074]
(2)因为damx大于threshold,所以在p4点处将轨迹划分为两部分,重新连接起始点和结束点,分别为p1p4和p4p
12
,寻找新的dmax 分别为p2到p1p4的距离和p7到p4p
12
的距离
[0075]
(4)因为p2到p1p4距离的dmax小于threshold,所以只保留p1和p4点,而p7到p4p
12
的距离小于threshold,所以,从p7点处继续划分轨迹。
[0076]
(5)连接划分后轨迹的起始点和结束点,得到新的dmax,因为 p5到p4p7距离的dmax小于threshold,所以保留p7点,而p
10
到p7p
12
距离的dmax大于threshold,所以继续划分轨迹。
[0077]
(6)划分后的轨迹,新产生的dmax均小于threshold,所以保留首尾轨迹点,最后得到经过dp算法压缩后的轨迹。
[0078]
从dp算法执行过程可以看到,大于阈值threshold的轨迹点主要出现在转弯段处。这是因为转弯处轨迹点波动较大,算法执行时保留的轨迹点会比较多。直线行驶的轨迹点波动较小,大于threshold 的轨迹点比较少,算法执行时保留的轨迹点也会相应减少。所以算法会将转弯段处的轨迹点保留得比较稠密,将直线行驶得轨迹点剔除的比较稀疏。为衡量压缩后的轨迹与原始轨迹的误差,本发明将剔除的轨迹点提取出来,并计算每个点与其相邻保留点之间弦的距离作为剔除点的误差,
[0079]
dp算法应用于船舶轨迹压缩需要手动设置参数threshold值,该值的选取决定了转弯段的轨迹能不能被较好的保留,本发明采用了肘部法则,对比不同threshold值下,dp算法保留轨迹点的数量。从图中可以看出当threshold值选择为100左右时候,算法保留的轨迹点数量基本上处于一个稳定趋势,可作为最佳压缩阈值选择。
[0080]
从误差分析图和阈值确定图中可以看出,虽然dp算法能够将船舶轨迹进行压缩,为后续数据处理提高运算效率。但是如果阈值选择较大的时候,其误差也会突变增大。这种情况容易导致船舶轨迹的局部信息失真而无法准确检测异常轨迹状态。所以本发明使用道格拉斯
ꢀ‑
普克算法来提取转弯点,并不用来压缩轨迹,后文的轨迹异常状态检测依旧使用原始轨迹点。
[0081]
聚类算法实现
[0082]
为了将船舶轨迹的转弯段提取出来,本发明通过dbscan聚类算基于迹点的密度分布进行聚类,使用时需要给定两个参数:最大半径 (epsilon)和最小点数量(minpts)。将经过dp算法压缩后的船舶轨迹应用于dbscan聚类,算法执行的主要步骤如下:
[0083]
第一步:随机选择一个在epsilon内轨迹点数量大于minpts的轨迹点作为核心点,并为其epsilon内的所有轨迹点分配一个新的簇标签label;
[0084]
第二步:评估核心点epsilon领域内的其余轨迹点是否满足在 epsilon内至少含有minpts个轨迹点。如果满足minpts标准,该点将作为新的核心点,并将label分配给新核心点epsilon内的所有轨迹点,如果不满足,则将该轨迹点epsilon领域内所有未分配label 的点都作为边界点;
[0085]
第三步:算法以核心点不断扩展集群,直到集群内的轨迹点全部被边界点包围,当前label簇搜索完成;
[0086]
第四步:寻找新的核心点,进行新的簇标签label搜索;
[0087]
第五步:将没有聚集到类簇中的点划分为异常点簇。
[0088]
核密度估计
[0089]
核密度估计是一种非参数估计,该方法可以不通过任何先验知识,以轨迹点出现的频率去估计概率密度函数。通常,统计数据点出现的频率会选用直方图,但是直方图会因
为不同的带宽选择造成差异较大的视觉效果,为新轨迹点的估计带来困难,所以本发明使用核密度估计来解决这一问题,其原理就是将频率分布直方图的带宽h设置为接近于无限小来估计概率密度,该过程需要定义一个核密度估计函数,本发明选用高斯核密度函数进行核密度估计。
[0090][0091]
式中:μ为轨迹数据均值,σ为轨迹数据的标准差。
[0092]
h也称为窗口宽度,当窗口长度的选择较小时,数据的细节会被过度放大,而当窗口长度选择较大时,数据的细节就会被平滑过度,本实验主要以dbscan聚类的转弯点去估计未进行dp算法压缩的轨迹,属于数据逼近方式,此类核密度估计窗口宽度h的最佳参数选择公式所示。
[0093][0094]
长短期记忆网络lstm
[0095]
长短期记忆网络lstm是一种特定形式的rnn。因为rnn将前一个数据的输入和当前的数据输入建立了联系,所以rnn相较于普通神经网络可以更好的处理序列数据。相较于普通神经网络,rnn在输入层和隐藏层之间加入了上一次隐藏层的输出权重矩阵w,rnn前向传播会将w应用于计算,计算公式为。
[0096]st
=f(ux
t
+ws
t-1
)
[0097]
式中:u是x
t
的权重矩阵,x
t
是t时刻的输入,w是s
t-1
权重矩阵,s
t-1
是t-1时刻隐藏层的输出。
[0098]
两个权重矩阵共同决定了t时刻的输出状态s
t
,而在下一次循环也就是t+1时刻,s
t
又会作为t+1时刻的参数状态参与运算,如此循环,直到输出最后的输出状态。rnn反向传播也是为了更新权重值,训练网络,其基本原理和普通神经网络相似,首先利用损失函数计算误差项,然后利用梯度下降法更新权重,得到最佳的权重矩阵w和偏倚向量b。rnn循环神经网络因为存在记忆功能,所以每次反向传播进行梯度下降时,都会将之前隐藏层计算出来的权重矩阵作为参数进行运算,这样的计算方式可以加长数据之间的联系,保证前后信息的联通。但是在处理较长的序列数据时容易发生梯度消失和梯度爆炸
[63]
,导致训练梯度不能在较长的序列中一直传递下去。为解决梯度消失和梯度爆炸的问题,lstm长短期记忆网络应用而生。
[0099]
sigmod为激活函数完成运算,计算公式为:
[0100]ft
=σ(wf·
[h
t-1
,x
t
]+bf)
[0101]
然后lstm经过输入门决定是否要加入新的信息到c
t-1
状态,主要通过sigmod层决定更新值,tanh层创造出一个包含新信息的向量
[0102]it
=σ(wi·
[h
t-1
,x
t
]+bi)
[0103][0104]
计算得到f
t
、i
t
和后,将c
t-1
状态更新为c
t
状态,由式(4-6) 完成:
[0105][0106]
最后,通过图中绿色部分的输出门来得到h
t
状态,输出门也是由两部分组成,计算公式如下。
[0107]ot
=σ(wo·
[h
t-1
,x
t
]+bo)
[0108]ht
=o
t
·
tanh(c
t
)
[0109]
lstm的设计主要解决了长期序列的信息相关性,相较于rnn可以解决梯度消失和梯度爆炸问题,可以在长序列中表现的更加优秀。船舶轨迹数据是一种带时间戳的长序列,且前一个轨迹点与后一个轨迹点有较强的关联,所以,使用lstm建立预测模型进行异常检测具有较高的优势。
[0110]
gru神经网络
[0111]
gru是2014年提出的神经网络模型,其内部相较于lstm少了一个门控状态,主要由重置门r
t
和更新门z
t
组成,x
t
是t时刻的输入,h
t
是t时刻的输出状态,重置门r
t
决定t-1时刻的输出状态h
t-1
和x
t
的组合输出,反映了当前层对前一时刻信息的保留程度。
[0112]rt
=σ(ur·
x
t
+wr·ht-1
+br)
[0113]
使用r
t
重置h
t-1
状态的相关信息,计算公式如下。
[0114][0115]
更新门z
t
将伏态更新到当时刻的输出状态h
t
,
[0116]zt
=σ(uz·
x
t
+wz·ht-1
+bz)
[0117][0118]
bi-lstm神经网络
[0119]
bi-lstm神经网络由前向lstm和反向lstm结构组成,输入序列分别以正序和逆序输入至网络结构,输出值同时受到前一时刻和后一时刻输入值和隐藏层状态值的影响。结构的输出y由前向lstm和反向lstm共同决定,t时刻,前向lstm的隐藏状态通过下式计算得到。
[0120][0121]
式中,u
→
和w
→
是前向lstm的权重矩阵,b
→
是前向lstm的偏倚向量。
[0122]
t时刻,反向lstm的隐藏状态通过下式计算得到。
[0123][0124]
式中,u
←
和w
←
是反向lstm的权重矩阵,b
←
是反向lstm的偏倚向量。
[0125]
t时刻的输出状态y
t
计算得到。
[0126][0127]
式中,v
→
和v
←
是bi-lstm的权重矩阵,bo是bi-lstm的偏倚向量。
[0128]
为衡量lstm、gru和bi-lstm三种模型在轨迹预测中的性能,实验将模型结构的隐藏层设置在3-25层范围内,每层神经元的个数设置在1-50范围内,batch-size设置为20,经过多次实验表明,当gru模型的隐藏层设置为6层,隐藏层的神经元个数设置为9的时候,效果模型最佳。lstm模型的隐层层设置为6层,隐藏层的神经元个数设置为8的时候,效果模型
最佳。bi-lstm模型隐藏层设置为7层,隐藏层的神经元个数设置为11的时候,效果模型最佳。三种模型的输入层都使用relu激活函数,隐藏层使用tanh激活函数。实验随机选用一条转弯轨迹段数据,模型在tensorflow环境下搭建。
[0129]
随机选取200条转弯轨迹段进行模型预测,反归一化后提取预测轨迹数据和实际轨迹数据。从200条轨迹中随机选取5000个轨迹点按照转换为两个经纬度点之间的距离误差,统计误差散点图。随机选取500个轨迹,反归一化后与实际的速度值相减求定量误差。
[0130][0131]
预测轨迹对比中,红色点表示实际船舶航行轨迹点,黑色点表示预测轨迹点,bi-lstm的预测轨迹点相较于gru和lstm更接近实际轨迹点。随机选取的经纬度误差散点中,bi-lstm模型的误差最大值为 1400m,gru和lstm模型的误差最大值为2000m,bi-lstm模型误差大于200m的轨迹点明显小于gru模型和lstm模型。速度误差散点中, bi-lstm模型的预测速度误差波动范围集中在
±
0.2knot之间,最大误差接近0.4knot,gru模型和lstm的最大误差接近0.6knot,bi-lstm 模型预测速度误差大于0.2knot的轨迹点小于gru模型和lstm模型。经过误差分析,bi-lstm模型在速度和经纬度预测中都有更高的准确度。
[0132]
取苏必利尔湖三个月内所有船舶轨迹,经纬度范围为: 46.365315《lat《49.028699,-92.311943《lon《-84.548284。提取到轨迹后划分轨迹段,轨迹被划分为15组。
[0133]
bi-lstm模型预测两组轨迹的经纬度均方根误差分别为104m和 106m,速度误差为0.0275knot和0.0219knot。两组轨迹中,bi-lstm 的预测精度都高于lstm和gru,且在不同轨迹段中预测误差没有发生较大的波动,说明bi-lstm预测模型可以在不同轨迹段中保持一个较高的预测准确度,可使用于大范围的船舶轨迹段预测。
[0134]
实际应用中,实时提取新产生的船舶轨迹序列,按照经纬度范围选择预测模型,计算预测结果与新产生轨迹的误差,如果误差大于 1.5倍的预测速度,则开始预警。
[0135]
以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1