一种基于Dempster-Shafer框架的分类方法与流程
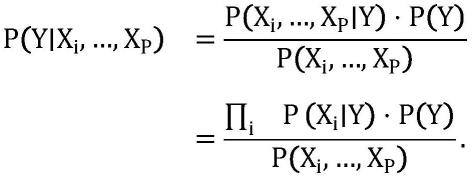
一种基于dempster-shafer框架的分类方法
技术领域
1.本发明属于基于dempster-shafer框架的加权模糊个体生成和群体判别分类相关技术领域,具体涉及一种基于dempster-shafer框架的分类方法。
背景技术:
2.在d-s理论中,识别框架被定义为不相容基本命题的完整集合,每个框架的子集称为命题。d-s理论是多源信息的组合规则,具有综合多个传感器的基本结果作为输出的功能。
技术实现要素:
3.本发明的目的在于提供一种基于dempster-shafer框架的分类方法。
4.为实现上述目的,本发明提供如下技术方案:
5.一种基于dempster-shafer框架的分类方法,判别分类方法包括辨别框架、质量函数、证据理论的组合规则、后验概率、模糊集合论、两个bba之间的bjs差异、ppt、ppt的单例形式、识别属性框架、成员计算、单个生成概率、培训样本分布、测试样品的分布、bjs散度判别、群体辨别概率、加权积分机制和构造bpa。
6.优选的,所述辨别框架流程如下:
7.让θ表示一个相互排斥的集合,该集合可以包含无限个元素,如θ={θ1,θ2,
…
,θj,
…
,θn},其中θj是辨别框架θ的要素或事件,n是元素个数,j=1,2,
…
,n,由θ的所有子集组成的集合称为质量函数,定义如下
[0008][0009]
表示空集;{θi,θj}指示θi或者θj事件发生,对于一个系统,无论它处于任何状态,我们都可以使用2
θ
中的元素来表示它;
[0010]
优选的,所述质量函数流程如下:
[0011]
设m是从集合2
θ
在θ下[0,1]的质量函数映射,焦点元素a表示标识框架θ的任何子集,m定义为
[0012][0013]
基本概率分布函数表示由证据建立的信任的初始分布,事件a的基本概率分配函数记录为m(a),用于表示证据对a的信任程度,m(a)通常也称为质量函数,它是根据检测获得的数据构建的,或者是由人们根据经验给出的;
[0014]
优选的,所述证据理论的组合规则流程如下:
[0015]
设e1和e2是识别θ框架下的两个证据,这两个证据对应的bpas是m1和m2。ai和bi是
焦点元素。desmpter的组合规则定义为
[0016][0017]
其中
[0018]
k值表示证据来源之间的冲突程度,在大多数情况下,对于不同的证据,由于数据来源不同,将获得两个或多个不同的bpa,此时,为了计算信任函数和似然函数,需要将两个或多个bpa合成为一个bpa;
[0019]
优选的,所述后验概率流程如下:
[0020]
设xi(i=1,2,...,p)为p独立特征,x表示p维特征向量。y∈c={c1,c2,...,cn}是与x状态相同的分类标记。然后后验概率p(y|xi),i=1
…
p,y∈{c1,c2,...,cn}可定义如下:
[0021][0022]
在本研究中,我们使用个体生成模型和群体生成模型来构建模型。这种方法为平衡个体差异和整体差异提供了一种可操作的方法,模糊集理论被用作描述隶属度的准则。
[0023]
优选的,所述模糊集合论流程如下:
[0024]
设ci(i=1,2,...,n)为类,dst的基本概率定义为:
[0025][0026]
fst是精确集的扩展。与精确集相比,fst提供了一个判断归属和不归属概念的标准,与标准贝叶斯理论相比,fst为处理实际应用中的不确定性和复杂性提供了另一个灵活的不确定性建模框架,由于现实世界的样本是模糊的,这些因素有时无法用经典概率论建模,因此可能没有严格定义,此时,fst具有使用优势,
[0027]
bjs散度理论是kl散度理论的推广,主要度量两个概率的相似性,解决了kl理论中结果不对称的问题,bjs发散具有良好的对称性和边界,此外,bjs分歧在证据理论中的应用更为恰当,虽然当两个分布距离较远时,点的梯度为0,但我们研究中遇到的问题大多是关于高相似性的决策,因此使用bjs散度具有一定的优势;
[0028]
优选的,所述两个bba之间的bjs差异流程如下:
[0029]
假设ai是识别框架m的元素之一,假设在同一识别框架ω下有两个bbasm1和m2,m1和m2之间的bjs偏差定义为:
[0030]
[0031]
其中并且s(m1,m2)=∑
i m1(ai)=1(i=1,2,...,m;j=1,2),∑
i mj(ai)=1(i=1,2,...,m;j=1,2),
[0032]
转换后,bjs可以表示为
[0033][0034]
其中h(mj)=-∑
i mj(ai)logmj(ai)(i=1,2,...,m;j=1,2)
[0035]
bjs散度在形式上与js散度相似,但bjs散度用质量函数代替了概率分布函数,当置信函数的所有假设都分配给单个元素时,这使得bba成为概率分布,此时,bjs散度退化为js散度;
[0036]
优选的,所述识别属性框架流程如下:
[0037]
设c是一个识别框架,包括n个互斥假设θ=c={c1,c2,...,cn},信息源的分布值2
θ
考虑到组合元件的基准编号{ci,cj},i≠j不大于2的标识框架表示如下:
[0038]
ω={{c1},...,{cn},{c1,c2},...,{ci,cj},
…
,{c
n-1
,cn}}.
[0039]
由于某些属性相似,高斯分布图上的表示重叠,因此提出了复合假设来表示此类情况。
[0040]
优选的,所述成员计算流程如下:
[0041]
设为每个对象x的不同类别的隶属度,为该类别的方差,ε为样本平均值,成员数计算如下:
[0042][0043]
根据隶属度计算的生成概率分为单一隶属度的生成概率和复合隶属度的生成概率,单一隶属度的生成概率用该类别的隶属度表示,复合隶属度的生成概率用两类隶属度范数的t组合的最小值计算;
[0044]
优选的,所述单个生成概率流程如下:
[0045]
设为组合成员,待测样本记录为生成概率用表示,如下所示:
[0046]
[0047]
优选的,所述培训样本分布流程如下:
[0048]
设有n组训练样本,n是m的倍数,ε
p
(ci)和σ
p
(ci)依次表示第j组样本的ci属性的样本均值和方差,训练集分布定义为
[0049][0050]
其中,
[0051][0052][0053]
训练集样本的分布特征符合高斯分布,假设我们需要测试数据库中的第k个样本,根据时间序列模型,用m个元素构造测试集文本分类标准根据每组m进行分类,并定义为
[0054]
优选的,所述测试样品的分布流程如下:
[0055]
设测试集包含n个元素,εq({ci}),σq({ci})依次表示样本的均值和方差,这决定了j个样本集的ci质量,以及训练集分布定义为
[0056][0057]
训练集样本的分布特征符合高斯分布,该方法使用bjs散度来度量训练集和测试集之间的差异;
[0058]
优选的,所述bjs散度判别流程如下:
[0059]
单属性bjs散度判别表示为:
[0060][0061]
多属性bjs散度判别定义如下:
[0062][0063]
其中,
[0064][0065]
优选的,所述群体辨别概率流程如下:
[0066]
设表示单个属性下的群判别概率,相应的综合属性群判别概率用表示如下:
[0067][0068][0069]
优选的,所述加权积分机制流程如下:
[0070]
设γ表示加权积分结果,启发式算法由α和β因子表示,定义如下
[0071][0072]
请注意,对于不同的属性类别,学习因子(α,β)是不同的;
[0073]
优选的,所述构造bpa流程如下:
[0074]
设mk为最终的bpa,这也是加权归一化后的表达式,如下所示:
[0075][0076]
其中,
[0077][0078]
注意,由于γ本身不等于1、它不是一个明确的bpa,因此,标准化因素γ被提议协助γ在最后一代bpa中。
[0079]
与现有技术相比,本发明提供了一种基于dempster-shafer框架的分类方法,具备以下有益效果:
[0080]
本发明提出的wfig-dsf利用bjs散度理论和数据特征来确定证据的属性并捕获类间不确定性,脑电数据的应用不仅控制了数据集整体的分布特征,而且还关注了个体代表性数据的特征,因此,该方法有效地度量了证据之间的不确定性,减少了分类器之间的有害冲突。该方法能够很好地捕获高冲突信息,保持分类器之间的重要互补性,提高了分类器融合的性能,此外,本文基于uci机器学习库中的12个数据集对wfig-dsf进行了评估,并将其与现有的其他分类方法进行了比较,最后得出结论,该方法具有广泛的应用价值,经过uci数据准确性测试,该方法的准确性在统计上优于11种方法的性能,决策结果更加可靠、稳
健,模型有效、合理,此外,引入bjs散度的方法对数据变化也具有很高的敏感性,为实际应用提供了方便,预计wfig-dsf在数据融合应用中尤其突出,它关注来自不同传感器源的数据,并考虑测试样本本身和训练样本分布之间的差异,以便做出更好的决策。
具体实施方式
[0081]
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0082]
本发明提供一种技术方案:
[0083]
一种基于dempster-shafer框架的分类方法,判别分类方法包括辨别框架、质量函数、证据理论的组合规则、后验概率、模糊集合论、两个bba之间的bjs差异、ppt、ppt的单例形式、识别属性框架、成员计算、单个生成概率、培训样本分布、测试样品的分布、bjs散度判别、群体辨别概率、加权积分机制和构造bpa。
[0084]
所述辨别框架流程如下:
[0085]
让θ表示一个相互排斥的集合,该集合可以包含无限个元素,如θ={θ1,θ2,
…
,θj,
…
,θn},其中θj是辨别框架θ的要素或事件,n是元素个数,j=1,2,
…
,n,由θ的所有子集组成的集合称为质量函数,定义如下
[0086][0087]
表示空集;{θi,θj}指示θi或者θj事件发生,对于一个系统,无论它处于任何状态,我们都可以使用2
θ
中的元素来表示它;
[0088]
质量函数流程如下:
[0089]
设m是从集合2
θ
在θ下[0,1]的质量函数映射,焦点元素a表示标识框架θ的任何子集,m定义为
[0090][0091]
基本概率分布函数表示由证据建立的信任的初始分布,事件a的基本概率分配函数记录为m(a),用于表示证据对a的信任程度,m(a)通常也称为质量函数,它是根据检测获得的数据构建的,或者是由人们根据经验给出的;
[0092]
证据理论的组合规则流程如下:
[0093]
设e1和e2是识别θ框架下的两个证据,这两个证据对应的bpas是m1和m2。ai和bi是焦点元素。desmpter的组合规则定义为
[0094]
[0095]
其中
[0096]
k值表示证据来源之间的冲突程度,在大多数情况下,对于不同的证据,由于数据来源不同,将获得两个或多个不同的bpa,此时,为了计算信任函数和似然函数,需要将两个或多个bpa合成为一个bpa;
[0097]
后验概率流程如下:
[0098]
设xi(i=1,2,...,p)为p独立特征,x表示p维特征向量。y∈c={c1,c2,...,cn}是与x状态相同的分类标记。然后后验概率p(y|xi),i=1
…
p,y∈{c1,c2,...,cn}可定义如下:
[0099][0100]
在本研究中,我们使用个体生成模型和群体生成模型来构建模型。这种方法为平衡个体差异和整体差异提供了一种可操作的方法,模糊集理论被用作描述隶属度的准则。
[0101]
模糊集合论流程如下:
[0102]
设ci(i=1,2,...,n)为类,dst的基本概率定义为:
[0103][0104]
fst是精确集的扩展。与精确集相比,fst提供了一个判断归属和不归属概念的标准,与标准贝叶斯理论相比,fst为处理实际应用中的不确定性和复杂性提供了另一个灵活的不确定性建模框架,由于现实世界的样本是模糊的,这些因素有时无法用经典概率论建模,因此可能没有严格定义,此时,fst具有使用优势,
[0105]
bjs散度理论是kl散度理论的推广,主要度量两个概率的相似性,解决了kl理论中结果不对称的问题,bjs发散具有良好的对称性和边界,此外,bjs分歧在证据理论中的应用更为恰当,虽然当两个分布距离较远时,点的梯度为0,但我们研究中遇到的问题大多是关于高相似性的决策,因此使用bjs散度具有一定的优势;
[0106]
两个bba之间的bjs差异流程如下:
[0107]
假设ai是识别框架m的元素之一,假设在同一识别框架ω下有两个bbasm1和m2,m1和m2之间的bjs偏差定义为:
[0108][0109]
其中并且s(m1,m2)=∑
i m1(ai)=1(i=1,2,...,m;j=1,2),∑
i mj(ai)=1(i=1,2,...,m;j=1,2),
[0110]
转换后,bjs可以表示为
[0111][0112]
其中h(mj)=-∑
i mj(ai)logmj(ai)(i=1,2,...,m;j=1,2)
[0113]
bjs散度在形式上与js散度相似,但bjs散度用质量函数代替了概率分布函数,当置信函数的所有假设都分配给单个元素时,这使得bba成为概率分布,此时,bjs散度退化为js散度;
[0114]
识别属性框架流程如下:
[0115]
设c是一个识别框架,包括n个互斥假设θ=c={c1,c2,...,cn},信息源的分布值2
θ
考虑到组合元件的基准编号{ci,cj},i≠j不大于2的标识框架表示如下:
[0116]
ω={{c1},...,{cn},{c1,c2},...,{ci,cj},
…
,{c
n-1
,cn}}.
[0117]
由于某些属性相似,高斯分布图上的表示重叠,因此提出了复合假设来表示此类情况。
[0118]
成员计算流程如下:
[0119]
设为每个对象x的不同类别的隶属度,为该类别的方差,ε为样本平均值,成员数计算如下:
[0120][0121]
根据隶属度计算的生成概率分为单一隶属度的生成概率和复合隶属度的生成概率,单一隶属度的生成概率用该类别的隶属度表示,复合隶属度的生成概率用两类隶属度范数的t组合的最小值计算;
[0122]
单个生成概率流程如下:
[0123]
设为组合成员,待测样本记录为生成概率用表示,如下所示:
[0124][0125]
培训样本分布流程如下:
[0126]
设有n组训练样本,n是m的倍数,ε
p
(ci)和σ
p
(ci)依次表示第j组样本的ci属性的样本均值和方差,训练集分布定义为
[0127][0128]
其中,
[0129][0130][0131]
训练集样本的分布特征符合高斯分布,假设我们需要测试数据库中的第k个样本,根据时间序列模型,用m个元素构造测试集文本分类标准根据每组m进行分类,并定义为
[0132]
测试样品的分布流程如下:
[0133]
设测试集包含n个元素,εq({ci}),σq({ci})依次表示样本的均值和方差,这决定了j个样本集的ci质量,以及训练集分布定义为
[0134][0135]
训练集样本的分布特征符合高斯分布,该方法使用bjs散度来度量训练集和测试集之间的差异;
[0136]
bjs散度判别流程如下:
[0137]
单属性bjs散度判别表示为:
[0138][0139]
多属性bjs散度判别定义如下:
[0140][0141]
其中,
[0142][0143]
群体辨别概率流程如下:
[0144]
设表示单个属性下的群判别概率,相应的综合属性群判别概率用表示如下:
[0145][0146]
加权积分机制流程如下:
[0147]
设γ表示加权积分结果,启发式算法由α和β因子表示,定义如下
[0148][0149]
请注意,对于不同的属性类别,学习因子(α,β)是不同的;
[0150]
所述构造bpa流程如下:
[0151]
设mk为最终的bpa,这也是加权归一化后的表达式,如下所示:
[0152][0153]
其中,
[0154][0155]
注意,由于γ本身不等于1、它不是一个明确的bpa,因此,标准化因素γ被提议协助γ在最后一代bpa中;
[0156]
根据d-s规则组合bpa
[0157]
在组合bpa时,我们使用d-s规则组合根据等式[eq14]生成的每个独立信息源的bpa,最终得到总体bpa。
[0158]
概率变换
[0159]
在获得总体bpa后,根据等式[eq11],将总体bpa转换为个体决策概率。
[0160]
终端决策
[0161]
通过ppt获得最终决策结果,并输出最可能的样本类别。
[0162]
uci数据集(https://archive-beta.ics.uci.edu)是一个经典的机器学习测试数据集,适用于模式识别和机器学习研究。我们使用uci数据集中的12种数据,即isir,heart,disease,wine,australian,climate,hepatitis,waveform,parkinsons,forest,ionosphere,spambase和sonar,与八种最先进的分类器和基于d-s理论的四种分类算法进行比较,得出该wfig-dsf的分类精度优于其他方法,八种分类器是朴素贝叶斯(nb)、最近均值分类器(nmc)、k近邻(k-nn)、决策树(reptree)、支持向量机(svm)、支持向量机和径向基函数(svm-rbf)、多层感知器(mlp)、径向基函数网络(rbfn)。基于d-s理论的分类算法分别
为k近邻d-s理论(knn dst)、基于正态分布的分类器(ndbc)、证据校正(evicalib)和加权模糊d-s框架(wfdsf)。
[0163]
在分类器融合中,不同分类器的分类结果往往高度冲突,有时甚至完全矛盾,这很可能导致不合理的融合结果,即错误。该融合方法能够很好地处理冲突情况,这是该方法的一个主要优点,当这些选定的数据集包含缺失信息时,在处理这种情况时,由于所提出的算法包含时间序列和bjs发散特征,这些缺失值可以用d-s理论中相应的变量进行拟合,具体而言,如果数据包含某个数据的缺失值,则该缺失值被视为不确定问题,并且该缺失值的信任度为0,即m(c)=1。此外,这一步骤导致群体概率的增加和个体概率的降低。除此缺失值外,还将定期收集其余属性,事实上,这是为了提高不同分类器的分类结果更接近准确度。通过对部分不准确度进行适当的拟合和建模,可以降低分类器之间的冲突程度。通过结合其他分类器的常规属性,利用与其他分类器的不兼容性来评估每个分类器的相对可靠性,最后,与其他分类器冲突程度较高的分类器提交的相对信度值较小。
[0164]
随着信息多元化进程的加剧,信息属性的分类问题被提上了议事日程。其中,使用机器学习和分类器的方法是数据融合中广泛使用的方法,提出了一种基于dempster-shafer框架的加权模糊个体生成和群体判别分类规则,将bpa作为多个分类器来支持不同的属性集,构造了一种新的目标分类识别方法,引入模糊贝叶斯和bjs散度理论对信息源进行聚合和分类,数据点进入聚类的概率由属性本身的特征与类别质心之间的距离决定,计算聚类的模糊隶属度进行分类。
[0165]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1