基于YoloV4-Lite网络的视频图像火焰检测方法
基于yolov4-lite网络的视频图像火焰检测方法
技术领域
1.本发明涉及图像检测技术领域,尤其涉及一种基于yolov4-lite网络的视频图像火焰检测方法。
背景技术:
2.火灾作为威胁公众安全和社会发展的主要灾害之一,不仅让人类的物质财产遭到损失,而且还直接或间接的危害人民群众的生命。为了避免火灾带来的巨大损失,有人提出基于视频图像处理来实现火焰检测,从而提前实现火灾预警。
3.如中国专利202111104533.0所公开的一种基于yolov4网络的无人机火焰检测方法,可用于不同的环境、光照强度以及天气情况,可以保证较高的检测准确性和快速性,实现了速度和精度的平衡。
4.认真研究后发现,yolov4整个网络结构可以分为三个部分,如图1所示,第一部分为主干特征提取网络(cspdarknet53),其作用是对图片进行初步的特征提取。cspdarknet53由basicconv模块和resblock_body模块组成。其中basicconv结合了卷积层(conv2d)、二维归一化处理层(batchnormalization)、激活函数(mish)三个部分,将输入的(416,416,3)的图片通道数加深到64,宽高不变。resblock_body模块采用了cspnet结构,如图2所示。cspnet结构把原有的残差结构的堆叠部分进行拆分成左右两部分,主干部分保持原有的堆叠结构,另一部分存在一个大的残差结构,经过少量的处理与主干部分在最后直接连接。最后获得(52,52,256),(26,26,512),(13,13,1024)三个特征有效层。
5.第二部分为空间池化金字塔(spatial pyramid pooling,spp)和加强特征提取网络(path aggregation network,panet)。spp网络结构的主要作用是极大增大特征层感受野,显著区分出不同特征层间的特征,设计四个不同尺度的最大池化处理特征层,其三个最大池化核的大小分别为13*13、9*9、5*5。panet网络结构最显著的特征在于反复提取特征,不仅需要在传统的特征金字塔结构里从下往上的特征提取,还需要实现从上往下的特征提取,融合过程如图3所示。第三部分为预测网络,其功能是利用更有效的有效特征层获得预测结果。由不同的conv2d构成,获得三个输出层分别为(batch_size,52,52,75)、(batch_size,26,26,75)、(batch_size,13,13,75)。
6.在应用yolov4进行视频图像火焰检测时,申请人发现其具有的缺陷是:
7.cspdarknet53虽然检测准确度和速度有所提高,但是存在网络结构复杂,flops运算大等缺点,需要对卷积层进行大量的计算,十分耗费计算机资源。
技术实现要素:
8.基于上述缺陷,本发明提供一种基于yolov4-lite网络的视频图像火焰检测方法,通过对传统yolov4网络架构进行改进,使其利用更少的参数得到更多的图像特征,从而节约计算资源。
9.为实现上述目的,本发明所采用的具体技术方案如下:
10.一种基于yolov4-lite网络的视频图像火焰检测方法,其关键在于,包括步骤:
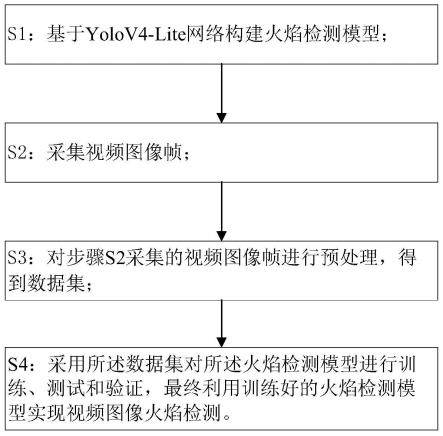
11.s1:基于yolov4-lite网络构建火焰检测模型;
12.将所述yolov4-lite网络的主干特征提取网络cspdarknet53替换为ghostnet网络,将所述yolov4-lite网络的加强特征提取网络panet的1x1和3x3的标准卷积替换为深度可分离卷积;同时在加强特征提取网络中加入了信道注意模块,所述信道注意模块由非线性自适应确定的一维卷积组成;
13.s2:采集视频图像帧;
14.s3:对步骤s2采集的视频图像帧进行预处理,得到数据集;
15.s4:采用所述数据集对所述火焰检测模型进行训练、测试和验证,最终利用训练好的火焰检测模型实现视频图像火焰检测。
16.可选地,步骤s2中采集视频图像帧包括利用爬虫技术从网络页面上爬取部分带有火焰图像的图片数据,经过数据清洗选择合适的图片进行标注,从而作为样本数据。
17.可选地,所述的预处理包括:采用9个不同尺寸的先验框对样本数据的图像进行标注,并利用k-means++聚类算法对预先标注的先验框的尺寸进行修正。
18.可选地,所述k-means++聚类算法具体步骤包括:
19.s31:输入数据集,随机从样本框区域选取一个初始聚类中心xj;
20.s32:计算每个样本框xi与初始聚类中心之间的最短距离d(xi);
21.s33:按照轮盘法选择一个新的点作为新的中心点,设定距离较大的点具有更大的选取概率;
22.s34:重复s31-s33直到每个簇中元素不在发生变化,输出聚类结果,得到的9个聚类中心结果乘以图片输入尺寸,作为原始的宽高。
23.可选地,所述信道注意模块根据通道维度c来确定卷积核大小k,具体为:
[0024][0025]
其中,|t|
odd
表示距离t最近的奇数,α和b为修正系数。
[0026]
可选地,所述深度可分离卷积由深度卷积和1*1逐点卷积组成,其中:所述深度卷积中每个卷积核的通道为1。
[0027]
可选地,步骤s2中使用labelimg软件对数据标注为pascal voc2007数据格式,标注类别分为无火焰和有火焰两种类别。
[0028]
本发明的显著效果是:
[0029]
本发明提供的一种基于yolov4-lite网络的视频图像火焰检测方法,在主干特征提取网络中使用ghostnet网络,保证减少网络参数的同时,准确率不会降低太多,在加强特征提取网络中使用深度可分离卷积替代1*1和3*3的传统卷积,进一步缩减网络的参数量,同时在加强特征提取网络部分加入信道注意模块,使神经网络可以更好的关注在被检测的物体上,达到网络性能和复杂度的平衡,最后通过使用k-means++聚类为模型生成更加合适的先验框,提升模型的检测准确度,改进后yolov4-lite网络模型,平均精度均值(map)减少了0.29%,可以忽略不计,但是每秒检测帧数(fps)提高约150%,提升了处理速度,有效节约了计算资源。
附图说明
[0030]
图1是现有技术中yolov4网络结构示意图;
[0031]
图2是现有技术中resblock_body模块的结构示意图;
[0032]
图3是现有技术中panet网络特征融合过程图;
[0033]
图4为本发明实施例提供的一种基于yolov4-lite网络的视频图像火焰检测方法的步骤图;
[0034]
图5是本发明实施例中采用的ghost模块的结构示意图;
[0035]
图6是本发明实施例中深度卷积模块(dw)和逐点卷积模块(pw)的结构示意图;
[0036]
图7是本发明实施例中的聚类结果图;
[0037]
图8是本发明实施例提供的信道注意力模块的结构图;
[0038]
图9是对比实验中三种网络模型loss对比曲线图;
[0039]
图10是对比实验中八种网络模型的迭代次数与损失函数对比曲线图。
具体实施方式
[0040]
下面结合附图具体阐明本发明的实施方式,实施例的给出仅仅是为了说明目的,并不能理解为对本发明的限定,包括附图仅供参考和说明使用,不构成对本发明专利保护范围的限制,因为在不脱离本发明精神和范围基础上,可以对本发明进行许多改变。
[0041]
为了对视频图像中是否存在火焰进行快速的机器检测,本发明实施例提供一种基于yolov4-lite网络的视频图像火焰检测方法,采用深度学习领域的yolov4-lite算法对视频图像中的火焰进行检测,具体步骤如图4所示,该方法主要包括步骤:
[0042]
s1:基于yolov4-lite网络构建火焰检测模型;
[0043]
将所述yolov4-lite网络的主干特征提取网络cspdarknet53替换为ghostnet网络,将所述yolov4-lite网络的加强特征提取网络panet的1x1和3x3的标准卷积替换为深度可分离卷积;同时在加强特征提取网络中加入了信道注意模块,所述信道注意模块由非线性自适应确定的一维卷积组成;
[0044]
s2:采集视频图像帧;
[0045]
s3:对步骤s2采集的视频图像帧进行预处理,得到数据集;
[0046]
s4:采用所述数据集对所述火焰检测模型进行训练、测试和验证,最终利用训练好的火焰检测模型实现视频图像火焰检测。
[0047]
针对步骤s1而言,本发明利用ghostnet网络替换原有的cspdarknet53网络。ghostnet网络是由华为诺亚方舟实验室最新研发的成果,它的核心思想在于“使用更少的参数得到更多的特征”,其中ghostnet网络的核心模块是ghost模块,如图5所示,ghost网络采用普通卷积生成部分特征图g,再将g进行线性运算生成g’,结合g和g’生成最终需要的特征图。
[0048]
输入特征图为h
×w×ci
,输出特征图为h
’×w’×co
,卷积核尺寸k,输入特征图划为s。
[0049]
常规卷积计算量如下式:
[0050]
flops=ci×h’×w’×co
×k×kꢀꢀ
(1)
[0051]
线性变化的计算量如下式:
[0052][0053]
ghostnet模块复杂度如下式:
[0054][0055]
与普通卷积神经网络相比,在不更改输出特征图大小的情况下,其所需的参数总数和计算复杂度均已降低,降低率约为s。
[0056]
设输入图像尺寸都为416
×
416
×
3,输入大小为1.98mb时,不考虑残差结构、池化层、激活函数、bn层与全连接层影响情况下,将cspdarknet53、mobilenet(v1、v2、v3)以及ghostnet的参数量进行对比,如表1所示。
[0057]
表1不同基础网络的参数量对比
[0058]
basic networkinput size/mbtraining parameters/millioncspdarknet531.986.40mobilenetv11.984.09mobilenetv11.983.90mobilebetv31.983.99ghostnet1.983.91
[0059]
由表1可以得出ghostnet网络参数比原有的cspdarknet53缩减了1.64倍,比轻量型网络mobilenetv3缩减了1.02倍。
[0060]
同时,在加强特征提取网络中采用了深度可分离卷积网络,深度可分离卷积由深度卷积(depthwise convolution,简称dw卷积)和1*1逐点卷积(pointwise convolution,简称pw卷积)组成,如图6所示,在所述深度卷积中每个卷积核的通道为1,而传统卷积要求卷积核通道和输入通道必须一致,pw卷积的功能是改变输出特征矩阵的通道。
[0061]
设定dk是卷积核的大小,df是输入特征图,m是输入特征矩阵的通道,n是输出特征矩阵的通道,则:
[0062]
标准卷积计算量为:
[0063]dk
×dk
×m×n×df
×df
ꢀꢀ
(4)
[0064]
标准卷积层参数量:
[0065]dk
×dk
×m×nꢀꢀ
(5)
[0066]
深度可分离卷积计算量:
[0067]dk
×dk
×m×df
×df
+m
×n×df
×df
ꢀꢀ
(6)
[0068]
深度可分离卷积参数量:
[0069]dk
×dk
×m×
n+dk×dk
×nꢀꢀ
(7)
[0070]
将(4)式与(6)式相除则有:
[0071][0072]
将3*3卷积核代入计算,可得深度可分离卷积计算量是标准卷积的约为1/9倍。因此,为了进一步减少参数量和运算量,本发明将加强特征提取网络(panet)的1*1和3*3的标准卷积替换为深度可分离卷积,改进后的整体网络参数量如表2所示。
[0073]
表2优化前后网络参数量对比
[0074]
basic networkbefore optimization/millionafter optimization/millioncspdarknet536.404.90mobilenetv14.091.26mobilenetv13.901.08mobilebetv33.991.17ghostnet2.301.14
[0075]
由表2可知,基础网络为cspdarknet53的yolov4网络,网络参数量降低了1.31倍。以ghostnet为基础网络的yolov4-lite,只有1.14million的参数量。因此可以认为,加强特征提取网络的普通卷积替换成深度可分离卷积,可以很好的降低网络的参数量,提高网络的检测速度。
[0076]
针对步骤s3而言,具体实施时,步骤s2中采集视频图像帧包括利用爬虫技术从网络页面上爬取部分带有火焰图像的图片数据,经过数据清洗选择合适的图片进行标注,从而作为样本数据。
[0077]
在进行图像预处理时,采用9个不同尺寸的先验框对样本数据的图像进行标注,并利用k-means++聚类算法对预先标注的先验框的尺寸进行修正。
[0078]
所谓先验框,简单来说,其作用就是帮助我们定好了常见目标的宽和高,在进行预测的时候,我们可以利用这个已经定好的宽和高处理,可以帮助我们进行预测。进行训练的时候,我们也要利用到先验框,找到真实框在图片中对应着哪个网格点。传统的yolov4网络中,每个网格点采用9个不同尺寸的先验框,且依据coco和voc2007数据集等设置先验框大小。
[0079]
coco和voc2007数据集的检测目标大,设置的先验框也较大,合适的先验框大小对于yolov4目标检测十分重要,火焰检测通常属于小目标,本身不是十分容易检测,在处于昏暗,遮掩物等环境条件下,更加难以检测。因此本实施例通过对yolov4-lite网络进行改进,采用k-means++聚类算法根据已标注好的真实框获取9个不同尺寸的先验框。
[0080]
具体来说,所述k-means++聚类算法步骤包括:
[0081]
s31:输入数据集,随机从样本框区域选取一个初始聚类中心xj;
[0082]
s32:计算每个样本框xi与初始聚类中心之间的最短距离d(xi);
[0083]
d(xi)=1-iou(xj,xi)
ꢀꢀ
(8)
[0084][0085]
s33:按照轮盘法选择一个新的点作为新的中心点,设定距离较大的点具有更大的选取概率;如式8所示。由于要选取图片的宽和高作为特征,需要先对图片的宽高进行归一化(resize),但是其宽和高不唯一,直接resize会导致图片发生形变,会影响特征提取结果,因此使用letterbox_image让图片不失真;
[0086]
s34:重复s31-s33直到每个簇中元素不在发生变化,输出聚类结果,得到的9个聚类中心结果乘以图片输入尺寸,作为原始的宽高,如图7所示。
[0087]
使用上述方法计算合适的先验框(5,10),(6,13),(7,15),(9,19),(13,24),(19,32),(27,47),(43,74),(81,140),如表3所示。
[0088]
表3改进的yolov4-lite先验框尺寸
[0089][0090]
实施过程中,由于在yolov4-lite网络的加强特征提取部分加入信道注意模块(eca),在ghostnet获得(52,52,256),(26,26,512),(13,13,1024)三个有效特征层以及上采样过程加入eca模块,可以提高网络模型在复杂条件下火焰的特征表达能力,使检测精度得到提升。eca模块是对se模块的改进,如图8所示。通过非线性自适应确定的一维卷积组成,是一种超轻量级的注意力模块,所以加入eca使精度提升的同时不会带来参数开销的问题。
[0091]
eca通过共享相同的学习参数,内核大小为k的快速一维卷积来实现局部跨通道交互,eca模块通过通道维度和卷积核大小k成比例的思想来确定k值。计算公式如下:
[0092][0093][0094]
|t|
odd
表示距离t最近的奇数,α和b为修正系数,本例中α=2,b=1。不同深度的卷积层具有不同最优k值,k对于eca注意力机制有明显的的影响,通常自适应确定的卷积核大小k要优于固定的卷积核大小,因此采取自适应确定k的方法。
[0095]
为了进一步验证本发明的技术效果,下面通过设计以下对比实验做进一步的说明
[0096]
实验环境:windows10(amd ryzen 7 4800h with radeon graphics八核);内存8gb;显卡是nvidia geforce gtx 1650(显存4gb)。编程语言是python3.8,深度学习框架是pytorch1.5.1,gpu加速软件cuda10.1,cudnn7.6。
[0097]
实验数据一部分利用网络爬虫技术,从网上爬取图片数据,再经过数据清洗选择合适的图片;另一部分来源于视频帧和自制,主要覆盖建筑工地、实验室、矿业生产等环境,共收集的图片7580张。使用labelimg软件对数据标注为pascal voc2007数据格式,标注类别分为无火焰和有火焰两种类别。按照比例将数据随机划分训练集和测试集,测试集共有759张,其中标有火焰的真实框为728个,标未有火焰的真实框为10340个。
[0098]
通过采用召回率(r)如公式(12)、精确率(p)如公式(13)、所有类别的平均精度(ap)如公式(14)、每秒检测帧数(fps)、平均精度均值(map)如公式(15)、召回率和精确率的加权值(f1)如公式(16),对模型评估性能。其中tp(true positives)是被分为了正样本,而且分对了。tn(true negatives)是被分为了负样本,而且分对了。fp(false positives)是被分为了正样本,却分错了(事实上这个样本是负样本)。fn(false negatives)是被分为了负样本,却分错了(事实上这个样本是正样本)。
[0099]
[0100][0101][0102][0103][0104]
模型训练过程中,原有的yolov4和改进的yolov4-lite都开启mosaic数据增强、余弦退火学习率衰减(cosineannealing)方法、标签平滑(label smoothing)训练技巧。标签平滑的值都设为0.01,图片尺寸设置(416,416),迭代总数为300epoch,前150epoch为冻结训练,初始学习率0.001,设置批训练数据量(batch_size)为64,后150epoch为解冻训练,初始学习率0.0001,设置批训练数据量(batch_size)为32。
[0105]
为了验证eca注意力模块对于卷积网络有更好的性能,特意设计注意力机制消融实验,实验中设置了三种网络模型,如表4所示,
①
代表了基础网络是cspdarknet53的yolov4-lite在fpn模块中添加se模块;
②
代表了基础网络是cspdarknet53的yolov4-lite添加在fpn模块中添加cbam模块;
③
代表了基础网络是cspdarknet53的yolov4-lite在fpn模块中添加eca模块。
[0106]
表4注意力机制消融实验设计
[0107]
modelsecbameca
①
√
××②×
√
×③××
√
[0108]
实验结果如表5所示,对比
①②
,以cspdarknet53作为基础网络,在相同的网络复杂度下cbam模块比se模块的map提高了1.64%,但fps降低了5.76,造成这种原因是由于cbam模块是空间注意力与通道注意力的融合,网络参数传播需要更多的运算。
[0109]
对比
②③
,在map上eca模块比cbam模块提升了1.69%,fps提高了10.27,精度与速度都得到了提升。体现了eca模块在卷积神经网络的有效性和高效性。
[0110]
综上所述,eca模块的深层卷积网络层引入了很少的附加参数和可忽略的计算,同时带来了显着的性能提升。
[0111]
表5注意力机制消融实验结果
[0112][0113]
三种网络模型迭代300次实验训练损失结果如图9所示,前150轮迭代冻结训练,
①
模型的loss值为18.6076;
②
模型的loss值为18.17002;
③
模型的loss值为17.78542。在第
150轮迭代解冻训练时loss显著下降,添加se注意力机制模型的loss一直低于添加cbam注意力机制模型和添加eca注意力机制模型,在300轮迭代稳定在3.333462左右,添加se注意力机制的网络模型更加容易收敛。
[0114]
接下来,通过消融实验将原有的yolov4与本发明提出改进的yolov4-lite进行对比分析,以此验证本文提出的改进yolov4-lite的有效性和高效性。消融实验设计如表6所示。所有对比实验均使用mosaic数据增强、余弦退火学习率衰减(cosineannealing)方法、标签平滑(label smoothing)训练技巧。
[0115]
网络模型分为8种模型,如表6所示。
①
原有的yolov4网络,
②
基础网络为mobilenetv1的yolov4网络,
③
基础网络为mobilenetv2的yolov4网络,
④
基础网络为mobilenetv3的yolov4网络,
⑤
基础网络为ghostnet的初步优化网络,
⑥
基础网络为ghostnet和加强特征提取网络添加eca模块的注意力优化网络,
⑦
基础网络为ghostnet,加强特征提取网络添加eca模块和采用k-means++聚类优化网络,
⑧
基础网络为ghostnet,加强特征提取网络添加eca模块,采用k-means++聚类以及使用深度可分离卷积的轻量化优化网络。
[0116]
表6消融实验实验设计
[0117][0118]
八种网络模型迭代300次,由图10可以看出模型
⑧
的loss下降的更快,网络模型更容易收敛,在迭代至280轮左右时,loss在2.22左右浮动,模型达到收敛。
[0119]
消融实验的实验结果如表7所示,分析表中实验结果,可以得出以下结论:
[0120]
(1)对比
①②③④
实验,在map的表现上,基础网络是mobilenet轻量化网络的比基础网络是cspdarknet53略降低,但是fps最高达到35.32,提高了18.38,说明检测速度有十分明显的提升。
[0121]
(2)对比
①⑤
实验,在map的表现上,
⑤
模型的比
①
模型降低了1.94%,但是在fps上提升了20.97,比mobilenet网络提高了2.40,检测速度有很明显的提升。这是因为ghostnet网络采用更少的卷积核和逐个特征图进行深度可分离卷积,cspdarknet53模型参数占用244mb,而ghostnet模型参数仅占用42.3mb,ghostnet网络中采用了se模块,替换后检测准确度没有受到太大影响。
[0122]
(3)由注意力机制消融实验可知,eca在深度卷积网络中,以忽略不计的计算开销带来精度和速度的提升。对比
⑤⑥
实验,
⑥
模型的精度和准确度都得到了相应的提高。
[0123]
(4)对比
⑥⑦
,后者
⑦
模型的map得到提升,从93.81到95.09,表明经过k-means++聚类得到的先验框更适合火焰目标检测。
[0124]
(5)对比
⑦⑧
实验,map方面降低了0.81%,fps达到42,提高了2.97。理论分析:深
度可分离卷积最大的优势在于减少参数量和网络运算。牺牲很小的准确度,带来了检测速度的提升,对于光照条件不足,光照不均的条件下,是可以接受的。
[0125]
表7消融实验实验结果
[0126][0127]
随机抽取测试集图片进行检测,对原有的yolov4和改进的yolov4-lite进行对比实验,结果发现,在有遮掩物的情况下,原有yolov4漏检了2个火焰,改进的yolov4-lite可以很好的全部识别出火焰。改进的yolov4-lite模型有效的减少了漏检率、误检率,虽然存在小部分漏检,但相比与原有的yolov4网络模型,准确率和检测速度都得到相应的加强。
[0128]
综上所述,本实施例提出的一种基于yolov4-lite网络的视频图像火焰检测方法,在现有技术的基础上,主要有以下四点改进,
①
主干特征提取网络修改为ghostnet网络,
②
使用k-means++聚类调整先验框,
③
加强特征提取网络添加eca注意力模块,
④
加强特征提取网络使用深度可分离卷积替换传统卷积,在精度和速度上,都可以很好的满足在光照条件不足、光照不均的环境中火焰检测要求,保证在减少网络参数的同时,准确率不会降低太多,从而提升视频图像火焰检测速度。
[0129]
最后需要说明的是,上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1