一种基于多模态信息的发言人跟踪方法及系统
1.本发明涉及发言人跟踪领域,尤其涉及一种基于多模态信息的发言人跟踪方法及系统。
背景技术:
[0002]“在多人图像中识别出说话人”的问题,现有的方法有的依赖于一些物理设备如阵列麦克风进行发言人定位,有的依赖于事先注册与会者的人脸和语音,有的仅仅使用单一模态的信息如人脸图像信息或者语音信息进行发言人跟踪。这些发言人跟踪方法的精度较低,必须使用阵列麦克风或者必须事先进行注册的情况限制了其应用场景。
[0003]
专利cn111263106a的方案旨在解决会议场景下,快速检测画面中多个与会人员中当前的发言人,提出通过处理图像信息获得人员的位置分布,然后根据麦克风阵列进行声音定位处理,最后结合两者的信息确定发言人所在的位置及对应的人脸图像。但这一方法对人员的分布要求严苛,当人员密集或是人员以层级分布时,主要依靠麦克风阵列的声音定位信息将难以确定真实发言人。
[0004]
专利cn112633219a提出实时监测每个人的嘴唇面积,判断嘴唇面积大于预设面积阈值的人正在发言。这一方法的缺点在于精度不够高,打哈欠、吃东西、咧嘴等行为也会导致嘴唇面积高于阈值从而被误判为发言人。
[0005]
专利cn112040119a提出的方案需要事先录入人员的人脸信息和人声信息,然后才能检测画面中的具体发言人,有不小的局限性。
[0006]
专利cn112487978a提出了两种方案:一是根据事先录入的信息与当前的人脸和人声的数据进行比较,判断是否匹配;二是使用syncnet模型提取人脸和人声的特征向量,计算余弦相似度,判断是否匹配。这一方案较于先前的方案效果更佳,但是对于低分辨率、唇部动作模糊的情况下效果不佳。
[0007]
以上的解决方案对于视频中的声音和图片信息的挖掘都不够充分,使用的技术手段都比较简单传统,所有方案并没有考虑人类的语音和面貌之间的关联性,导致发言人跟踪精度较低,对于唇部动作模糊的场景效果不佳。同时,现有的技术方案有使用提前录入的人脸、人声数据对,但是没有设计动态更新的系统,没有将使用过程中配对可信度足够高的人脸、人声数据对记录到配对数据库中。
技术实现要素:
[0008]
为解决现有技术的不足,针对画面中的说话人定位任务,本发明提出了一种基于多模态信息的发言人跟踪方法及系统,利用输入的图像及对应的音频信息计算出图像中每个人脸的说话唇动得分、音貌匹配得分以及唇形同步得分,根据图像中的每个人脸的得分,定位具体说话人。同时支持提前录入注册配对的人声人脸对,并且支持在使用过程中将配对置信度高的人声人脸对录入到先验数据库中。
[0009]
为实现上述目的,本发明采用的技术方案为:
[0010]
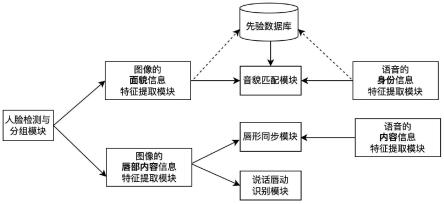
第一方面,本发明提供了一种基于多模态信息的发言人跟踪系统,所述系统包括:语音的身份信息特征提取模块、语音的内容信息特征提取模块、图像的面貌信息特征提取模块、图像的内容特征提取模块、人脸图像质量计算模块、人脸检测与分组模块、唇形同步模块、说话唇动识别模块、音貌匹配模块及先验数据库。
[0011]
采用语音的身份信息特征提取模块,对输入的音频提取得到语音身份信息特征向量;
[0012]
采用语音的内容信息特征提取模块,对输入的音频提取得到语音内容信息特征向量;
[0013]
采用图像的面貌信息特征提取模块,依次将r张输入图像face1…
facer提取得到逐帧人脸面貌特征向量,并将每张图像输入到人脸图像质量计算模块中,计算得到每张输入图像质量得分,将r张图像的质量得分与r个逐帧人脸面貌特征向量的通道维度上进行拼接,提取得到人脸面貌特征向量。
[0014]
采用图像的内容特征提取模块,将r张输入图像在时间维度上进行拼接,得到拼接后的图像拼接向量;将每张输入图像单独输入到人脸图像质量计算模块,得到每张输入图像质量得分,将每张输入图像的质量得分复制扩展后与图像拼接向量进行拼接和特征提取,得到人脸唇部内容特征向量;
[0015]
人脸图像质量计算模块,将单张彩色人脸图像输入到卷积神经网络,得到图像质量得分;
[0016]
人脸检测与分组模块,逐帧检测视频片段中的人脸,给出每个人脸的矩阵信息,将属于同一个人的人脸矩阵分为一组,并对缺失人脸信息的帧进行人脸信息补全,得到完整的人脸矩阵序列。
[0017]
唇形同步模块,输入人脸唇部内容特征向量与语音内容信息特征向量,利用余弦相似度计算两个特征向量的相似度,得到唇形同步得分;
[0018]
说话唇动识别模块,将人脸唇部内容特征向量输入到一个或多个具有激活函数的全连接层后,再输入到带有sigmoid激活函数的全连接层,得到说话唇动得分;
[0019]
音貌匹配模块,输入人脸面貌信息特征向量与语音身份信息特征向量,利用l1距离计算两个特征向量的距离,得到音貌匹配得分;
[0020]
先验数据库,支持提前录入先验数据库及在使用中录入先验数据库,在发言人跟踪过程中优先使用先验数据库进行匹配。
[0021]
所述语音的身份信息特征提取模块,具体为:对输入的音频,经过梅尔滤波器提取网络滤波器组(filter bank)特征v0;将网络滤波器组特征v0输入到第一卷积神经网络(ecapa-tdnn)中,提取得到w1维的中间向量v1,对中间向量v1进行l2正则化,通过c1个全连接层,提取得到语音身份信息特征向量emb
vid
。
[0022]
所述语音的内容信息特征提取模块,具体为:将中间向量v1进行l2正则化,通过c2个全连接层,得到w2维的中间向量v2;将中间向量v2通过c3个全连接层,得到w3维的中间向量v3;使用残差连接,将中间向量v2和v3相加,得到v4=v2+v3,再通过c4个全连接层,得到语音内容信息特征向量emb
vct
。
[0023]
所述图像的面貌信息特征提取模块,具体为:依次将r张输入图像face1…
facer输入到第二卷积神经网络(inception-v1)中,提取得到w4维的中间向量并进行l2正则化,
通过c5个全连接层,提取得到w5维的特征向量r张输入图像处理后将得到形状为(r,w5)的特征向量z
fid
;将每张输入图像facei单独输入到人脸图像质量计算模块中,计算得到每张输入图像质量得分qi;
[0024]
r张输入图像得到形状为(r,1)的质量得分向量q;将质量得分向量q和特征向量z
fid
拼接得到形状为(r,w5+1)维的向量,输入到循环神经网络(lstm)中,计算得到w5+1维的中间向量z1;将中间向量z1通过c6个全连接层,得到综合r张输入图像的人脸面貌特征向量emb
fid
。
[0025]
所述图像的内容特征提取模块,具体为;将r张输入图像在时间维度上进行拼接,其他维度保留,得到(c,w*r,h)大小的向量,其中,c表示输入图像的通道数,若输入的是彩色图像,则c=3;若输入的是灰度图,则c=1;其中,r表示输入图像张数;w表示输入图像宽度的像素个数;h表示的是输入图像高度的像素个数,拼接后的输入图像拼接向量为x0;
[0026]
将每张输入图像单独输入到人脸图像质量计算模块,得到形状为(r,1)的质量得分向量x1;
[0027]
将形状为(r,1)的质量得分向量x1复制拓展为形状为(1,w*r,h)的质量得分向量x2,x2[1,i,j]=x1[i%w,1],i∈[0,w*r),j∈[0,h);将输入图像拼接向量x0与质量得分向量x2在第一维度进行拼接,得到形状为(c+1,w*r,h)的特征向量x3;
[0028]
将特征向量x3输入到第三卷积神经网络中,提取得到w6维的特征向量,记为x4;将中间向量x4进行l2归一化,得到内容特征向量emb
fct
。
[0029]
所述人脸图像质量计算模块,将单张彩色人脸图像输入到第四卷积神经网络(resnet50),得到w7维的中间向量v,将此中间向量输入到带有sigmoid激活函数的全连接层,得到图像质量得分score
quality
∈(0,1);
[0030]
所述人脸检测与分组模块:利用深度学习算法检测视频片段的每一帧中的所有人脸,得到每个人脸的矩阵信息表示第j帧中检测到的第i张人脸的矩阵信息;根据相邻帧的人脸矩阵信息的交并比将所有帧中属于同一个人的人脸矩阵分组,若与的交并比大于设定的阈值,则判定这两个人脸矩阵属于同一个人,将被划分到同一组中;使用线性插值法为缺失人脸信息的帧根据相邻帧的人脸矩阵信息进行补全;根据补全后的人脸矩阵序列裁剪得到人脸图像序列
[0031]
所述唇形同步模块,输入人脸唇部内容特征向量emb
fct
与语音内容信息特征向量emb
vct
,利用余弦相似度计算两个特征向量的相似度,即为唇形同步得分score
ct
,其中score
ct
∈[-1,1];得分越高表示越匹配。
[0032]
所述音貌匹配模块,输入人脸面貌信息特征向量emb
fid
与语音身份信息特征向量emb
vid
,利用l1距离计算两个特征向量的距离,即为音貌匹配得分score
id
;其中,score
id
≥0;得分越小表示越匹配。
[0033]
所述说话唇动识别模块,将人脸唇部内容特征向量emb
fct
输入到带激活函数的全连接层中,得到w8维的中间向量a1;将中间向量a1输入到带sigmoid激活函数的全连接层,得到说话唇动得分score
talk
∈(0,1),说话唇动得分越高说明计算得到的人脸唇部内容特征
向量所对应的人脸说话的可能性越高;
[0034]
所述先验数据库,事先录入人员对应的若干张人脸照片及人声音频、将人脸照片序列输入到图像的面貌信息特征提取模块中,得到每个人员对应的面貌信息特征向量emb
fid
,将人声音频进行降噪处理,输入到语音的身份信息特征提取模块,提取得到每个人员对应的语音身份信息特征向量emb
vid
,将向量emb
vid
和emb
fid
保存进先验数据库中。在发言人跟踪过程中优先进行基于先验数据库的音貌匹配。
[0035]
所述先验数据库支持在使用中录入或更新,在使用过程中将配对置信度高的人声人脸对录入到数据库中。具体为:根据唇形同步、音貌匹配、说话唇动检测等模块找到了匹配的语音身份信息特征向量与图像面貌信息特征向量时,将匹配得分高于录入阈值的向量对保存进先验数据库中;
[0036]
所述语音的身份信息特征提取模块model
vid
与图像的面貌信息特征提取模块model
fid
共同训练,训练流程为:将同一个人员的人脸图片与人声音频分别输入到model
fid
和model
vid
中,得到emb
fid
和emb
vid
;
[0037]
使用均方误差损失函数loss1如式(1)所示:
[0038]
loss1=mse(emb
fid
,emb
vid
)
ꢀꢀ
(1)
[0039]
所述语音的内容信息特征提取模块model
vct
与图像的内容信息特征提取模块model
fct
共同训练;
[0040]
具体为:语音的内容信息特征提取模块model
vct
中的第一卷积神经网络的全部网络参数来自语音的身份信息特征提取模块model
vid
的第一卷积神经网络的参数,这些参数在训练过程中的数值大小固定、不参与反向传播过程中的参数更新;
[0041]
将同一个人员的说话片段所对应的人脸图片序列和人声音频片段分别输入到model
fct
及model
vct
中,分别得到图像的唇部内容特征向量emb
fct
及基于音频的语音内容信息特征向量emb
vct
;将和图片序列没有对应关系的人声音频输入到model
vct
中得到不匹配的语音内容信息特征向量emb
′
vct;
通过最大化emb
fct
和emb
′
vct
之间的余弦相似度,最小化emb
fct
和emb
vct
之间的余弦相似度来让两个模型学习得到视频中的内容信息;损失函数loss2如式(2)所示:
[0042]
loss2=cosinesim(emb
fct
,emb
vct
)-cosinesim(emb
fct
,-emb
′
vct
)
ꢀꢀ
(2)
[0043]
所述说话唇动识别模块表示为model
talk
,在图像的内容信息特征提取模块提取出的emb
fct
上进行训练;
[0044]
具体为:将在说话的人脸图像序列输入到model
fct
中得到将没有在说话的人脸图像序列输入到model
fct
中得到将和输入到model
talk
中,得到对应的说话唇动得分和使用二分类交叉熵损失训练模型,最小化并且最大化损失函数loss3如式(3)所示:
[0045][0046]
另一方面,本发明提供了一种基于多模态信息的发言人跟踪方法,采用所述一种基于多模态信息的发言人跟踪系统实现,包括以下步骤:
[0047]
s1:获取音频和视频,分别利用音频采集设备和视频采集设备获取t时刻到t+s时刻的音频片段和视频片段;
[0048]
s2:人声判断与语音特征提取,判断所述音频片段中是否包含人声;若未包含人声,则判断t时刻到t+s时刻没有人发言,进入s9;若包含人声,将所述音频片段输入到语音的身份信息特征提取模块,得到语音身份信息特征向量emb
vid
;并将所述音频片段输入到语音的内容信息特征提取模块,得到语音内容信息特征向量emb
vct
;
[0049]
s3:人脸图像序列提取,将所述视频片段逐帧输入到人脸检测与分组模块,得到人脸图像序列
[0050]
s4:图像特征提取,将人脸图像序列输入到人脸图像质量计算模块,得到每一帧人脸图像所对应的图像质量得分将与输入到图像的面貌信息特征提取模块,得到人脸面貌特征向量序列将与输入到图像的内容特征提取模块,得到人脸唇部内容特征向量
[0051]
s5:检索先验数据库中所有已录入的语音身份信息特征向量,判断是否有与语音身份特征向量emb
vid
相似的录入人声;
[0052]
若存在与emb
vid
相似的录入人声向量emb
′
vid
,则进入s6;
[0053]
若不存在与语音身份特征向量emb
vid
相似的录入人声,则进入s7;
[0054]
s6:取出与emb
′
vid
对应的目标人脸面貌特征向量在给定图像中的面貌信息特征向量候选序列中寻找是否有相似度高于匹配阈值threshold
match
的特征向量,若有,则将对应的人脸矩阵序列信息标记输出,若没有,则判断当前画面中没有和对应人声符合的人脸,进入s9;
[0055]
s7:依次将图像中第i个人的与emb
vct
配对输入到唇形同步模块中得到唇形同步得分将与emb
vid
输入到音貌匹配模块中计算得到音貌匹配得分将输入到说话唇动识别模块中计算得到说话唇动得分
[0056]
综合唇形同步得分、音貌匹配得分以及说话唇动得分,赋权计算得到最终得分综合唇形同步得分、音貌匹配得分以及说话唇动得分,赋权计算得到最终得分比较最终得分与识别阈值threshold
score
,若每个人的人脸图像序列的得分都低于识别阈值,则判断为没有和人声符合的人脸,进入s9;若只有一个或有多个人的人脸图像序列的得分高于识别阈值,则将得分最高者记为当前发言人;
[0057]
s8:若当前发言人的最终得分高于录入阈值threshold
record
,则将当前发言人对应的emb
vid
与emb
fid
登记到先验数据库中;
[0058]
s9:t=t+s,返回步骤s1。
[0059]
采用上述技术方案所产生的有益效果在于:
[0060]
1、本发明提供了一种基于多模态信息的发言人跟踪方法及系统,综合计算人声与
人脸的说话唇动得分、唇形同步得分、音貌匹配得分,对图像中当前发言人做出判断,从而支持在运算过程中将配对置信度高的数据对录入到数据库中,且数据库支持提前录入注册匹配的人脸、人声数据对。
[0061]
2、本发明通过计算输入的人声与图像中每一个人脸的匹配得分,解决了传统方法中依靠麦克风阵列的声音定位信息所无法解决的人员密集、多人位于同一角度的问题。
[0062]
3.本发明采用多层神经网络来提取人脸图像的深层信息,相较于使用浅层的嘴唇面积数据判断人脸是否在说话而言更加准确。
[0063]
4.本发明不仅支持事先录入人脸人声数据对,同时也支持在使用过程中判断新出现的人脸与人声是否配对,并且能够将置信度高的数据对录入数据库方便后续使用。
[0064]
5.本发明不仅会提取人脸的唇部动作信息,计算人脸和人声的唇形同步得分,还会提取人脸身份信息,根据人脸的面貌信息与人声的声纹信息之间的深层联系计算人脸和人声的音貌匹配得分,从而提高了当图像分辨率低、唇部动作难以识别时的人声和人脸的匹配准确度。
[0065]
6、本发明综合使用多维度信息,不仅使用了唇部动作序列和音频内容信息的联系,还联合使用了人脸面貌信息与人声声纹信息之间的关系。进一步提高了匹配的准确率,缓解了唇部动作不够清晰的场景下的匹配压力,并且在一定程度上能识别图片中的说话人是否只是在对口型的情况。
附图说明
[0066]
图1为本发明实施例提供的一种基于多模态信息的发言人跟踪系统模块图;
[0067]
图2为本发明实施例提供的语音的身份信息特征提取模块工作流程图;
[0068]
图3为本发明实施例提供的语音的内容信息特征提取模块工作流程图;
[0069]
图4为本发明实施例提供的图像的面貌信息特征提取模块工作流程图;
[0070]
图5为本发明实施例提供的图像的内容特征提取模块工作流程图;
[0071]
图6为本发明实施例提供的人脸图像质量计算模块工作流程图;
[0072]
图7为本发明实施例提供的人脸检测与分组补全模块工作流程图;
[0073]
图8为本发明实施例提供的唇形同步模块工作流程图;
[0074]
图9为本发明实施例提供的说话唇动识别模块工作流程图;
[0075]
图10为本发明实施例提供的音貌匹配模块工作流程图;
[0076]
图11为本发明实施例提供的先验数据库工作流程图;
[0077]
图12为本发明实施例提供的一种基于多模态信息的发言人跟踪方法流程图。
具体实施方式
[0078]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
[0079]
本实施例提出了一种基于多模态信息的发言人跟踪方法,利用输入的图像音频信息计算出图像中每个人脸的说话唇动得分、音貌匹配得分以及唇形同步得分的系统,可以对图像中的每个人脸进行打分,定位具体说话人。同时支持提前录入注册配对的人声人脸对,并且支持在使用过程中将配对置信度高的人声人脸对录入到先验数据库中。
[0080]
为实现上述目的,本实施例采用的技术方案为:
[0081]
第一方面,本实施例提供了一种基于多模态信息的发言人跟踪系统,如图1所示,所述系统包括:语音的身份信息特征提取模块、语音的内容信息特征提取模块、图像的面貌信息特征提取模块、图像的内容特征提取模块、人脸图像质量计算模块、人脸检测与分组模块、唇形同步模块、说话唇动识别模块、音貌匹配模块及先验数据库。
[0082]
语音的身份信息特征提取模块,如图2所示,对输入的音频,经过梅尔滤波器组提取网络滤波器组特征v0;将网络滤波器组特征v0输入到ecapa-tdnn卷积神经网络模型中,提取得到512维的中间向量v1,对中间向量v1进行l2正则化,通过4个全连接层,提取得到语音身份信息特征向量emb
vid
。
[0083]
语音的内容信息特征提取模块,如图3所示,将中间向量v1进行l2正则化,通过5个全连接层,得到256维的中间向量v2;将中间向量v2通过2个全连接层,得到256维的中间向量v3;使用残差连接,将中间向量v2和v3相加,得到v4=v2+v3,再通过1个全连接层,得到语音内容信息特征向量emb
vct
。
[0084]
图像的面貌信息特征提取模块,如图4所示,依次将r张输入图像face1…
facer输入到inception-v1卷积神经网络中,提取得到512维的中间向量并进行l2正则化,通过4个全连接层,提取得到每张图像的128维的人脸面貌特征向量r张输入图像处理后将得到形状为(r,128)的特征向量z
fid
;将每张输入图像facei单独输入到人脸图像质量计算模块中,计算得到每张输入图像质量得分qi;
[0085]
得分在0~1之间,得分越高表示图像质量越高;所述图像质量通过图像中人脸的清晰度及姿态是否为正面判定,用于表示图片中的人脸是否足够清晰、是否具有足够的信息来提取特征;
[0086]
r张输入图像得到形状为(r,1)的质量得分向量q;将质量得分向量q和特征向量z
fid
拼接得到形状为(r,129)维的向量,输入到lstm中,得到129维的中间向量z1;将中间向量z1通过1个全连接层,得到综合r张输入图像的人脸面貌特征向量emb
fid
。
[0087]
图像的内容特征提取模块,如图5所示,将r张输入图像在时间维度上进行拼接,其他维度保留,得到(c,w*r,h)大小的向量,其中,c表示输入图像的通道数,若输入的是彩色图像,则c=3;若输入的是灰度图,则c=1;其中,r表示输入图像张数;w表示输入图像宽度的像素个数;h表示输入图像高度的像素个数,拼接后的输入图像拼接向量为x0;
[0088]
将每张输入图像单独输入到人脸图像质量计算模块,得到形状为(r,1)的质量得分向量x1;每张输入图像质量得分在0~1之间,得分越高表示图像质量越高,所述图像质量包括图像清晰度和图像中人脸姿态。
[0089]
将形状为(r,1)的质量得分向量x1复制拓展为形状为(1,w*r,h)的质量得分向量x2,x2[1,i,j]=x1[i%w,1],i∈[0,w*r),j∈[0,h);将输入图像拼接向量x0与质量得分向量x2在第一维度进行拼接,得到形状为(c+1,w*r,h)的特征向量x3;
[0090]
将特征向量x3输入到17层二维卷积网络中,提取得到128维的特征向量x4;将特征向量x4进行l2归一化,得到内容特征向量emb
fct
。
[0091]
人脸图像质量计算模块,如图6所示,将单张彩色人脸图像输入到resnet50卷积神经网络,得到2048维的中间向量v,将中间向量v输入到全连接层,并通过sigmoid层,得到图像质量得分score
quality
∈(0,1);
[0092]
所述人脸检测与分组模块,本实施例中,采用yolo-v5或s3fd深度学习模型进行人脸检测,如图7所示,检测t时刻至t+s时刻的视频片段的每一帧中的所有人脸,得到每个人脸的矩阵信息其中,i表示当前帧中检测到的第i张人脸;j表示是第j帧。表示覆盖第i张人脸对应的矩阵的左上角横坐标信息、左上角纵坐标信息、右下角横坐标信息、右下角纵坐标信息;根据相邻帧的人脸矩阵信息的交并比将所有帧中属于同一个人的人脸矩阵分组,若与的交并比大于设定的阈值,则判定这两个人脸矩阵属于同一个人,将被划分到同一组中,得到分组后的人脸矩阵序列。
[0093]
唇形同步模块,如图8所示,输入人脸唇部内容特征向量emb
fct
与语音内容信息特征向量emb
vct
,利用余弦相似度计算两个特征向量的相似度,即为唇形同步得分score
ct
,其中score
ct
∈[-1,1];得分越高表示越匹配。
[0094]
说话唇动识别模块,如图9所示将人脸唇部内容特征向量emb
fct
输入到带激活函数的全连接层中,得到128维的中间向量a1;将中间向量a1输入到带sigmoid激活函数的全连接层,得到说话唇动得分score
talk
∈(0,1),说话唇动得分越高说明计算得到的人脸唇部内容特征向量所对应的人脸说话的可能性越高;没有在说话既可以是沉默,也可以是咀嚼、微笑动作;
[0095]
音貌匹配模块,如图10所示,输入人脸面貌信息特征向量emb
fid
与语音身份信息特征向量emb
vid
,利用l1距离计算两个特征向量的距离,即为音貌匹配得分score
id
;其中,score
id
≥0;得分越小表示越匹配;
[0096]
先验数据库,如图11所示,给定录入数据库的人员对应的若干张人脸照片以及一段人声音频;将给定的人脸照片序列输入到图像的面貌信息特征提取模块中,得到每个人员对应的面貌信息特征向量emb
fid
;将给定的人声音频进行降噪处理,输入到基于音频的身份信息特征提取模块,提取得到每个人员对应的语音身份信息特征向量emb
vid
;将人员编号及其向量构成的三元组《id,emb
vid
,emb
fid
》保存进先验数据库中。在发言人跟踪过程中优先进行基于先验数据库的音貌匹配;
[0097]
所述先验数据库在使用中的自动更新,当输入的数据没有在数据库中找到对应的向量,且后续根据唇形同步、音貌匹配、说话唇动检测等模块找到了匹配的“语音身份信息特征向量emb
vid”与“图像面貌信息特征向量emb
fid”时,则将匹配得分高于录入阈值的发言人编号和向量构成的三元组《id,emb
vid
,emb
fid
》保存进先验数据库中;
[0098]
所述语音的身份信息特征提取模块与图像的面貌信息特征提取模块共同训练,训练流程为:需训练的模块分别是语音的身份信息特征提取模块model
vid
、图像的面貌信息特征提取模块model
fid
,输入同一个人员的人脸图片与人声音频到各个模块中,得到emb
vid
和emb
fid
;其中model
vid
的4个全连接层和model
fid
的4个全连接层共享网络参数。
[0099]
使用均方误差损失函数loss1如式(1)所示:
[0100]
loss1=mse(emb
fid
,emb
vid
)
ꢀꢀ
(1)
[0101]
所述语音的内容信息特征提取模块model
vct
与图像的内容信息特征提取模块model
fct
共同训练;
[0102]
具体为:语音的内容信息特征提取模块model
vct
中的ecapc-tdnn层的网络参数取
值是来自语音的身份信息特征提取模块model
vid
的网络参数,在训练过程中这些参数取值固定不再变化,不参与反向传播的参数更新;
[0103]
将同一个人员的说话片段所对应的人脸图片序列和人声音频片段分别输入到model
fct
及model
vct
中,分别得到图像的唇部内容特征向量emb
fct
及基于音频的语音内容信息特征向量emb
vct
;将和图片序列没有对应关系的人声音频输入到model
vct
中得到不匹配的语音内容信息特征向量emb
′
vct
;为了使得从同一个视频中提取出的相互匹配的特征emb
fct
和emb
vct
足够接近,不匹配的特征emb
fct
和emb
′
vct
足够远离,计算两者之间的cosine相似度;通过最大化emb
fct
和emb
′
vct
之间的cosine相似度,最小化emb
fct
和emb
vct
之间的相似度来让两个模型学习得到视频中的内容信息;损失函数loss2如式(2)所示:
[0104]
loss2=cosinesim(emb
fct
,emb
vct
)-cosinesim(emb
fct
,-emb
′
vct
)
ꢀꢀ
(2)
[0105]
所述说话唇动识别模块表示为model
talk
,在图像的内容信息特征提取模块提取出的emb
fct
上进行训练;
[0106]
具体为:将在说话的人脸图像序列输入到model
fct
中得到将没有在说话的人脸图像序列输入到model
fct
中得到将和输入到model
talk
中,得到对应的说话唇动得分和使用二元交叉熵损失训练模型,最小化并且最大化损失函数loss3如式(3)所示:
[0107][0108]
另一方面,本发明提供了一种基于多模态信息的发言人跟踪方法,采用所述一种基于多模态信息的发言人跟踪系统实现,如图12所示,包括以下步骤:
[0109]
s1:通过云台摄像头获取t时刻到t+s时刻的视频片段,记为通过麦克风或阵列麦克风获取t时刻到t+s时刻的音频片段,记为
[0110]
s2:对于音频片段提取能量大小及过零率判断这一片段中是否包含人声;若未包含人声,则t时刻到t+s时刻没有人发言,t=t+s,返回s1;若包含人声,则将人声音频输入到语音的身份信息特征提取模块,得到语音身份信息特征向量emb
vid
;将人声音频输入到语音的内容信息特征提取模块,得到语音内容信息特征向量emb
vct
;
[0111]
s3:将视频片段输入到人脸检测与分组模块,得到每个人在各个帧中的人脸矩阵信息序列i表示是第i个人的人脸,j表示是第j帧,j∈[t,t+s];
[0112]
s4:由于视频中人脸可能处于移动状态,不能保证每一帧的图片都足够清晰,也因此存在人脸检测模块无法识别出有些帧的一些人脸的情况,面对这一问题,使用线性插值法为缺失人脸信息的帧根据相邻帧的人脸矩阵信息进行补全,得到更新后的人脸矩阵信息序列
[0113]
具体为:若检测到了第i人在时刻j1和时刻j2上的人脸矩阵
和在时刻j1和j2时刻之间没有检测出该人的人脸,使用线性插值法得到时刻k中第i人所对应的人脸矩阵信息其中,其中,
[0114]
若第i人检测到人脸的第一帧在时刻t
first
,且t
first
>t,将使用t
first
时刻的人脸矩阵信息为时刻t到时刻t
first
之间的帧赋予人脸矩阵信息;若检测到人脸的最后一帧t
final
<t+s,则使用时刻t
final
的人脸矩阵信息为时刻t
final
后的帧赋予人脸矩阵信息。
[0115]
s5:根据人脸矩阵序列裁剪得到人脸图像序列输入到人脸图像质量计算模块,得到每一帧人脸图像所对应的图像质量得分将与输入到图像的面貌信息特征提取模块,得到人脸面貌特征向量序列将与输入到图像的唇部信息特征提取模块,得到人脸唇部内容特征向量序列
[0116]
s6:检索数据库中所有已录入的语音身份信息特征向量,判断是否有向量emb
′
vid
满足l1(emb
′
vid, emb
vid
)<threshold
vid
,其中l1(*)表示两个向量的l1距离,threshold
vid
为距离阈值;
[0117]
若存在录入人声向量emb
′
vid
与向量emb
vid
之间的l1距离小于threshold
vid
,配对成功,若有多个音频配对成功,则取l1距离最近的录入人声向量记为emb
′
vid
;进入s7;
[0118]
若在先验数据库中不存在与向量emb
vid
之间的l1距离小于阈值的录入人声向量,则进入s8;
[0119]
s7:将emb
′
vid
对应的目标面貌信息特征向量取出,记为遍历给定图像中的面貌信息特征向量序列中的所有向量,计算与目标面貌信息特征向量之间的l1距离,查看是否有满足的向量,若有,则取其中与之间的l1距离最小的面貌特征向量对应的人脸信息作为标记结果;若没有,则判断发言人不在画面中;
[0120]
进入步骤s10;
[0121]
s8:依次将图像中第i个人的与emb
vct
输入到唇形同步模块中得到唇形同步得分将与emb
vid
输入到音貌匹配模块中计算得到音貌匹配得分将
输入到说话唇动识别模块中计算得到说话唇动得分
[0122]
综合唇形同步得分、音貌匹配得分以及说话唇动得分,赋权计算得到最终得分综合唇形同步得分、音貌匹配得分以及说话唇动得分,赋权计算得到最终得分比较最终得分与识别阈值threshold
score
,若每个人的人脸图像序列的得分都低于识别阈值,则判断为没有和人声符合的人脸;若只有一个或有多个人的人脸图像序列的得分高于识别阈值,则将得分最高者记为当前发言人;
[0123]
s9:若当前发言人的最终得分score高于录入阈值threshold
record
,则将当前发言人编号及其对应的emb
vid
与emb
fid
登记到先验数据库中;
[0124]
s10:t=t+s,返回步骤s1。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1