一种人物状态识别方法、装置、介质及计算设备与流程
本发明涉及面部识别领域,尤其涉及一种人物状态识别方法、装置、介质及计算设备。
背景技术:
1、目前,关于面部识别研究领域颇多,但一般都是采取一张静态的照片进行脸部特征提取并识别判断,由于面部表情变化速度较快,基于单张静态照片对于部分表情难以捕捉识别,故而在面部表情识别率方面,尚且存在一定的挑战。另外,目前的面部识别装置大多需要依赖较为庞杂的3d卷积神经网络,考虑到所耗性能和时间成本问题,对于目前市场上一些小型终端设备还并没有得到普及运用。
2、上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现思路
1、本发明的主要目的在于提供一种人物状态识别方法、装置、介质及计算设备,旨在解决背景技术中所提到的问题。
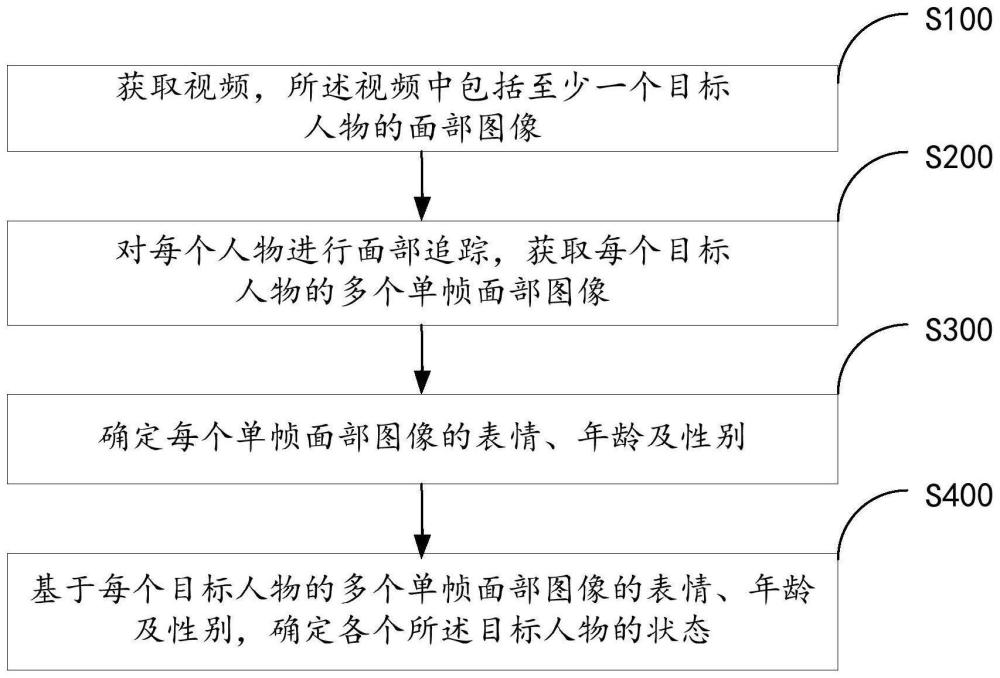
2、为实现上述目的,本发明提供一种人物状态识别方法,包括:
3、获取视频,所述视频中包括至少一个目标人物的面部图像;
4、对每个目标人物进行面部追踪,获取每个目标人物的多个单帧面部图像;
5、确定每个单帧面部图像的表情、年龄及性别;
6、基于每个目标人物的多个单帧面部图像的表情、年龄及性别,确定各个所述目标人物的状态。
7、在本技术实施例中,对每个目标人物进行面部追踪,获取视频中每个目标人物在当前帧的单帧面部图像,包括:
8、基于目标检测器,为所述视频中包含所述面部图像的每一帧中的每个面部创建检测框及对应的轨迹信息;
9、基于上一帧中每个面部的轨迹信息,预测得到所述每个面部在当前帧中的预测框;
10、基于当前帧中的预测框和检测框,确定当前帧中的各个面部与上一帧中的各个面部的对应关系;
11、将当前帧中与上一帧中具有对应关系的面部的轨迹信息进行更新,并基于当前帧的预测框和检测框,确定所述具有对应关系的面部在当前帧的边界框;以及
12、将当前帧中与上一帧中没有对应关系的面部的检测框,作为该面部在当前帧中的边界框;
13、基于每个目标人物的面部在当前帧中的边界框,获取每个目标人物在当前帧中的单帧面部图像。
14、在本技术实施例中,所述轨迹信息包括表观特征和运动特征;
15、所述基于上一帧中每个面部的轨迹信息,预测得到所述每个面部在当前帧中的预测框,包括:
16、利用卡尔曼滤波器,基于上一帧中每个面部的运动特征,预测得到所述每个面部在当前帧中的预测框。
17、在本技术实施例中,基于当前帧中的预测框和检测框,确定当前帧中的各个面部与上一帧中的各个面部的对应关系,包括:
18、基于当前帧的各个预测框和各个检测框的表观特征的马氏距离,得到各个预测框和各个检测框的余弦距离代价矩阵;
19、基于各个所述代价矩阵进行级联匹配和iou匹配,得到当前帧的各个面部,与上一帧的各个面部的对应关系。
20、在本技术实施例中,将当前帧中与上一帧中具有对应关系的面部的轨迹信息进行更新,并基于当前帧的预测框和检测框,确定所述具有对应关系的面部在当前帧的边界框,包括:
21、利用卡尔曼滤波器,基于前后两帧具有对应关系的面部在当前帧中的检测框,对其在当前帧中的预测框进行优化,得到所述面部在当前帧中的边界框。
22、在本技术实施例中,所述基于每个目标人物的面部在当前帧中的边界框,获取每个目标人物在当前帧中的单帧面部图像,包括:
23、基于目标检测器,确定所述目标人物对应的边界框在当前帧中的中心坐标及长宽;
24、基于所述边界框在当前帧中的中心坐标及长宽,在当前帧中进行剪裁,获取所述目标人物在当前帧的单帧面部图像。
25、在本技术实施例中,所述确定每个单帧面部图像的表情、年龄及性别,包括:
26、利用mobilenet神经网络识别所述单帧面部图像中的表情;以及
27、利用efficientnet神经网络识别所述单帧面部图像所对应的目标人物的年龄和性别。
28、本技术实施例还提出一种人物状态识别装置,包括:
29、获取模块,用于获取视频,所述视频中包括至少一个目标人物的面部图像;
30、处理模块,用于对每个目标人物进行面部追踪,获取每个目标人物的多个单帧面部图像;
31、确定每个单帧面部图像的表情、年龄及性别;以及
32、基于每个目标人物的多个单帧面部图像的表情、年龄及性别,确定各个所述目标人物的状态。
33、在本技术实施例中,所述处理模块包括目标检测器和跟踪模块;
34、所述目标检测器用于,为所述视频中包含所述面部图像的每一帧中的每个面部创建检测框及对应的轨迹信息;
35、所述跟踪模块用于,基于上一帧中每个面部的轨迹信息,预测得到所述每个面部在当前帧中的预测框;
36、基于当前帧中的预测框和检测框,确定当前帧中的各个面部与上一帧中的各个面部的对应关系;
37、将当前帧中与上一帧中具有对应关系的面部的轨迹信息进行更新,并基于当前帧的预测框和检测框,确定所述具有对应关系的面部在当前帧的边界框;以及
38、将当前帧中与上一帧中没有对应关系的面部的检测框,作为该面部在当前帧中的边界框;
39、所述目标检测器还用于,基于每个目标人物的面部在当前帧中的边界框,获取每个目标人物在当前帧中的单帧面部图像。
40、在本技术实施例中,所述轨迹信息包括表观特征和运动特征;
41、所述跟踪模块包括卡尔曼滤波器,所述跟踪模块被配置为,利用所述卡尔曼滤波器,基于上一帧中每个面部的运动特征,预测得到所述每个面部在当前帧中的预测框。
42、在本技术实施例中,所述跟踪模块还包括匈牙利模型,所述跟踪模块还被配置为:
43、利用所述匈牙利模型,确定当前帧的各个预测框和各个检测框的表观特征的马氏距离,得到各个预测框和各个检测框的余弦距离代价矩阵;以及
44、基于各个所述代价矩阵进行级联匹配和iou匹配,得到当前帧的各个面部,与上一帧的各个面部的对应关系。
45、在本技术实施例中,所述处理模块还被配置为:
46、利用所述卡尔曼滤波器,基于前后两帧具有对应关系的面部,在当前帧中的检测框,对其在当前帧中的预测框进行优化,得到所述面部在当前帧中的边界框。
47、在本技术实施例中,所述目标检测器还被配置为:
48、确定每个所述边界框在其所在帧中的中心坐标及长宽;
49、基于每个所述边界框在其所在帧中的中心坐标及长宽,在其所在帧中进行剪裁,获取每个边界框所对应的单帧面部图像。
50、在本技术实施例中,所述处理模块还包括:mobilenet神经网络和efficientnet神经网络;
51、所述mobilenet神经网络用于,识别所述单帧面部图像中的表情;
52、所述efficientnet神经网络用于,识别所述单帧面部图像所对应的目标人物的年龄和性别。
53、本技术还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法。
54、本技术还提出一种计算设备,所述计算设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现上述的方法。
55、本技术技术方案,通过对视频中的各个目标人物的面部进行追踪,得到各个目标人物在视频中的多个单帧面部图像,并基于每个目标人物的多个单帧面部图像,确定各个目标人物的面部表情、年龄及性别,进而根据每个目标人物的年龄、性别,以及在每一帧中的表情,来确定各个目标人物的状态。相较于现有技术中基于静态图像识别目标人物状态,本技术可以基于动态的视频来同时确定多个目标人物的状态,而且对于连续的视频序列而言,还能够达到实时检测的效果。
- 还没有人留言评论。精彩留言会获得点赞!