基于流式计算的数据处理方法、装置、设备及存储介质与流程
本发明涉及数据处理,尤其涉及一种基于流式计算的数据处理方法、装置、设备及存储介质。
背景技术:
1、目前,如果数据在实时库下线,在天库上没有上线,会出现数据时有时无的情况,对客户很不友好。而且,天库虽然每天都有上线,但因为批量模式、资源问题、长尾效应等原因,数据经常多天还没上线,引起数据时有时无。
技术实现思路
1、本发明的主要目的在于提出一种基于流式计算的数据处理方法、装置、设备及存储介质,旨在解决如何提高数据处理效率,解决数据上线周期长的情况的技术问题。
2、为实现上述目的,本发明实施例提供一种基于流式计算的数据处理方法,所述基于流式计算的数据处理方法包括:
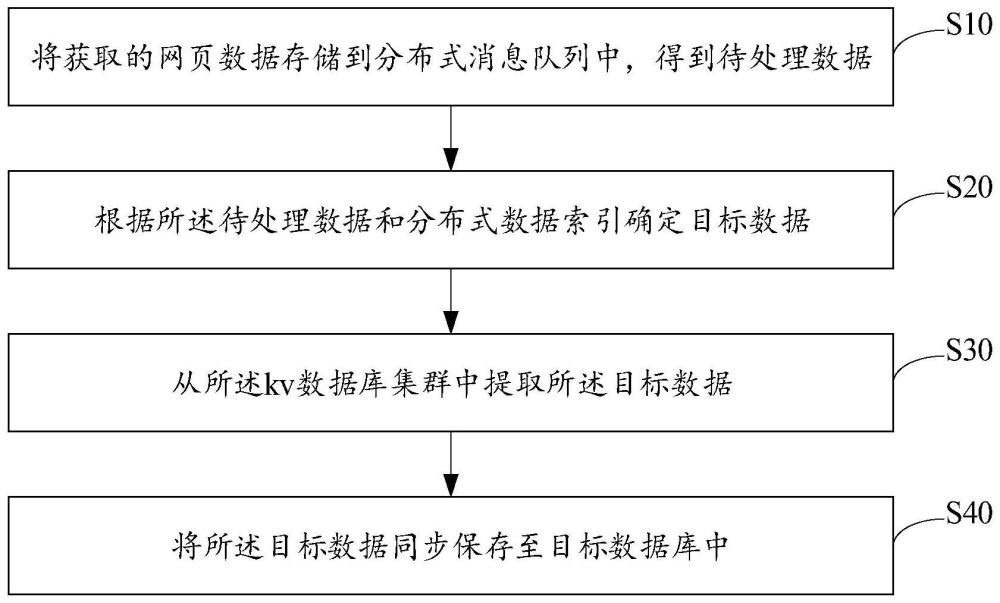
3、将获取的网页数据存储到分布式消息队列中,得到待处理数据;
4、根据所述待处理数据和分布式数据索引确定目标数据,所述分布式数据索引为kv数据库集群对应的索引;
5、从所述kv数据库集群中提取所述目标数据;
6、将所述目标数据同步保存至目标数据库中。
7、可选地,所述根据所述待处理数据和分布式数据索引确定目标数据之前,还包括:
8、基于kv的原始数据构建kv数据库集群;
9、根据所述kv数据库集群生成分布式数据索引。
10、可选地,所述基于kv的原始数据构建kv数据库集群,包括:
11、将kv的原始数据批量存入预设数据库;
12、通过调度系统调用分桶服务对所述预设数据库中的数据进行分桶;
13、根据分桶后的数据构建kv数据库集群。
14、可选地,所述通过调度系统调用分桶服务对所述预设数据库中的数据进行分桶,包括:
15、通过调度系统调用分桶服务确定至少一个桶;
16、根据所述桶对所述预设数据库中的数据进行划分,使划分出的数据与所述桶对应;
17、将划分出的数据分别存储至对应的桶中,以对所述预设数据库中的数据进行分桶。
18、可选地,所述根据分桶后的数据构建kv数据库集群,包括:
19、在有桶产出之后,针对每个桶进行分片,得到每个桶对应的至少一个片;
20、根据分桶后的数据得到各个片对应的片数据;
21、根据所述片数据构建kv数据库集群。
22、可选地,所述kv数据库集群至少为一个,各kv数据库集群互为主备。
23、可选地,所述根据所述kv数据库集群生成分布式数据索引,包括:
24、在映射阶段,读取片数据,并将所述片数据划分到对应的规约中;
25、在规约阶段,调用kv写接口构建kv索引;
26、当一个桶的kv索引构建完之后,将生成的kv索引放到临时路径;
27、根据所述临时路径中的kv索引生成分布式数据索引。
28、可选地,所述根据所述临时路径中的kv索引生成分布式数据索引,包括:
29、对所述临时路径中的kv索引进行校验;
30、将通过校验的kv索引放到正式路径,并对没有通过校验的kv索引进行重建;
31、根据所述正式路径中的kv索引生成分布式数据索引。
32、可选地,所述根据所述正式路径中的kv索引生成分布式数据索引之前,还包括:
33、获取分布式文件系统上的kv的当前版本以及线上版本;
34、根据所述当前版本和所述线上版本判断是否存在版本更新;
35、若存在版本更新,则生成更新后的kv索引,并根据更新后的kv索引对所述正式路径中的kv索引进行替换。
36、可选地,所述将获取的网页数据存储到分布式消息队列中,得到待处理数据,包括:
37、将获取的网页数据存储到分布式消息队列中;
38、读取所述分布式消息队列中的数据,得到候选数据;
39、对所述候选数据进行过滤,得到待处理数据。
40、可选地,所述对所述候选数据进行过滤之前,还包括:
41、接收数据通道推送的词典;
42、根据所述词典对当前词典进行更新,得到更新后的当前词典;
43、相应地,所述对所述候选数据进行过滤,包括:
44、根据所述更新后的当前词典对所述候选数据进行过滤。
45、可选地,所述将所述目标数据同步保存至目标数据库中,包括:
46、将所述目标数据同步保存至至少一个目标数据库中,各目标数据库的数据更新频次存在区别。
47、此外,为实现上述目的,本发明实施例还提出一种基于流式计算的数据处理装置,所述基于流式计算的数据处理装置包括:
48、数据处理模块,用于将获取的网页数据存储到分布式消息队列中,得到待处理数据;
49、数据查找模块,用于根据所述待处理数据和分布式数据索引确定目标数据,所述分布式数据索引为kv数据库集群对应的索引;
50、数据提取模块,用于从所述kv数据库集群中提取所述目标数据;
51、数据保存模块,用于将所述目标数据同步保存至目标数据库中。
52、可选地,所述基于流式计算的数据处理装置,还包括:
53、数据库构建模块,用于基于kv的原始数据构建kv数据库集群;
54、索引生成模块,用于根据所述kv数据库集群生成分布式数据索引。
55、可选地,所述数据库构建模块,还用于将kv的原始数据批量存入预设数据库;通过调度系统调用分桶服务对所述预设数据库中的数据进行分桶;根据分桶后的数据构建kv数据库集群。
56、可选地,所述数据库构建模块,还用于通过调度系统调用分桶服务确定至少一个桶;根据所述桶对所述预设数据库中的数据进行划分,使划分出的数据与所述桶对应;将划分出的数据分别存储至对应的桶中,以对所述预设数据库中的数据进行分桶。
57、可选地,所述数据库构建模块,还用于在有桶产出之后,针对每个桶进行分片,得到每个桶对应的至少一个片;根据分桶后的数据得到各个片对应的片数据;根据所述片数据构建kv数据库集群。
58、可选地,所述kv数据库集群至少为一个,各kv数据库集群互为主备。
59、此外,为实现上述目的,本发明实施例还提出一种基于流式计算的数据处理设备,所述基于流式计算的数据处理设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于流式计算的数据处理程序,所述基于流式计算的数据处理程序被处理器执行时实现如上所述的基于流式计算的数据处理方法。
60、此外,为实现上述目的,本发明实施例还提出一种存储介质,所述存储介质上存储有基于流式计算的数据处理程序,所述基于流式计算的数据处理程序被处理器执行时实现如上所述的基于流式计算的数据处理方法。
61、本发明实施例提出的基于流式计算的数据处理方法中,将获取的网页数据存储到分布式消息队列中,得到待处理数据;根据所述待处理数据和分布式数据索引确定目标数据,所述分布式数据索引为kv数据库集群对应的索引;从所述kv数据库集群中提取所述目标数据;将所述目标数据同步保存至目标数据库中。从而可以结合实时流式处理架构、分布式数据索引以及kv数据库集群,提高数据处理效率,避免了数据上线周期长的问题。
- 还没有人留言评论。精彩留言会获得点赞!