一种适用于多核数据处理器的CPU实现装置和方法与流程
本发明涉及芯片soc设计领域、ai人工智能计算领域,具体涉及一种适用于多核数据处理器的cpu实现装置和方法。
背景技术:
1、随着社会的快速发展以及电子信息技术的广泛应用,多核处理器已经是解决当前实时性要求高的复杂电子系统的必备硬件,多核处理器具备多个核心,既能为用户带来更强大的计算性能,更重要的,则是可满足用户同时进行多任务处理和多任务计算环境的要求。
2、但是随着多核处理器的发展,关于多核处理器存在的问题也越来越明显,主要是两个方面。第一是硬件资源的分享,一个多核处理器本身的硬件资源是有限的,多核处理器会相互争抢,导致性能非线性增长;其次多线程数据处理共享时可能会引起缓存一致性风暴。另外一方面是软件资源的分享,有时候线程在不同处理器内核之间切换,造成额外开销,多个处理器核访问同一数据结构时,必须存在内核锁,数据处理越频繁,内核锁所带来的的开销越大;再者,本身计算量不大,强行分给多核处理,数据处理效率可能适得其反了。因此多核处理器如何相互协调以便达成最优的处理能力成为亟需解决的问题。
技术实现思路
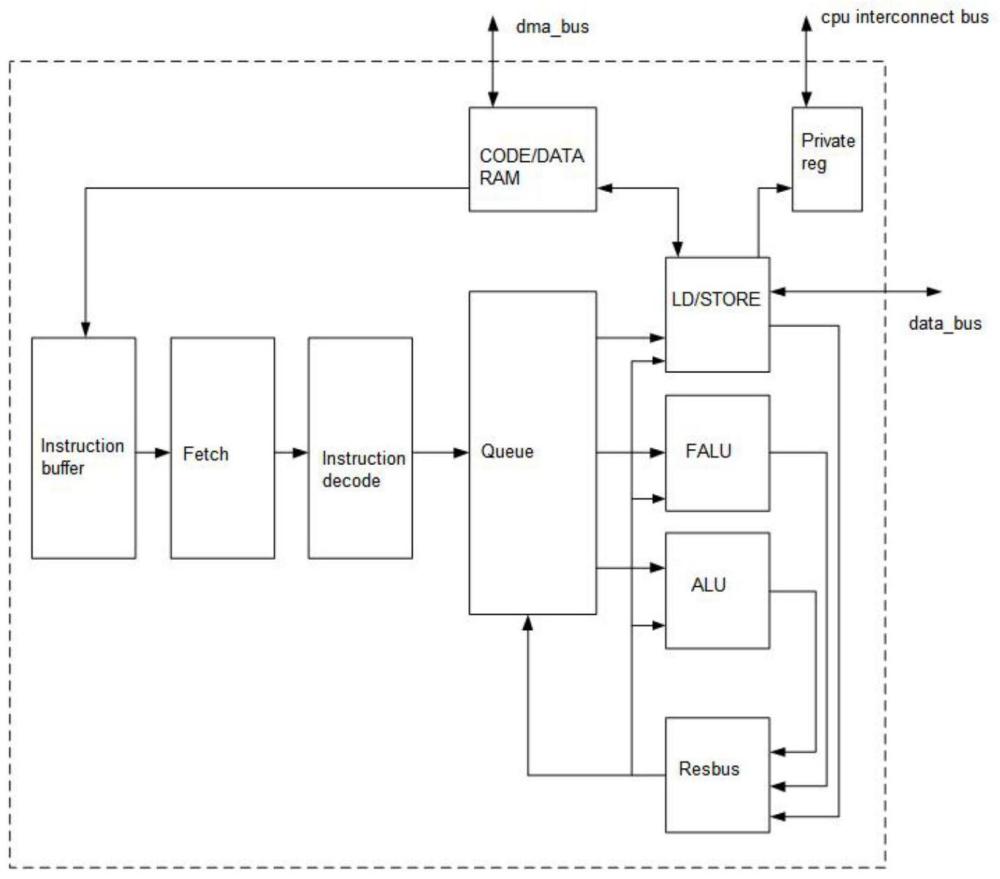
1、本发明提供一种适用于多核数据处理器的cpu实现装置和方法,通过执行由内部存储单元中的指令对数据的处理操作,实现多核协同处理数据的目的;且该cpu核也可以独立运行,本发明适合于多核数据处理;结构简洁简单,效率高。本发明解决上述技术问题的技术方案装置如下:一种适用于多核数据处理器的cpu实现装置包括取指、译码、发射、执行、写回、总线、专有寄存器七个部分。
2、进一步,所述取指包含code/data ram,instruction buffer,fetch三部分组成;
3、进一步,所述译码包括instruction decode,queue两部分组成;
4、进一步,所述发射包括queue部分组成;
5、进一步,所述执行包括ld/store,falu,alu三部分组成;
6、进一步,所述写回包括resbus,queue两部分组成;
7、进一步,所述总线包括dma_bus,cpu interconnect bus,data_bus三部分组成;
8、进一步,所述专有寄存器包括private reg;
9、进一步,所述译码以及写回都包含发射queue。
10、进一步,所述dma_bus与code/data ram相连接,并且是双向通信;
11、进一步,所述cpu interconnect bus与private reg相连接,并且是双向通信;
12、进一步,所述data_bus与ld/store相连接,并且是双向通信;
13、进一步,所述code/data ram与instruction buffer相连接,并且通信方向是从code/data ram到instruction buffer;
14、进一步,所述instruction buffer与fetch相连接,并且通信方向是从instruction buffer到fetch;
15、进一步,所述fetch与instruction decode相连接,并且通信方向是从fetch到instruction decode;
16、进一步,所述instruction decode与queue相连接,并且通信方向是从instruction decode到queue;
17、进一步,所述queue与ld/store相连接,并且通信方向是从queue到ld/store;
18、进一步,所述queue与falu相连接,并且通信方向是从queue到falu;
19、进一步,所述queue与alu相连接,并且通信方向是从queue到alu;
20、进一步,所述queue与resbus相连接,并且通信方向是从到resbus到queue;
21、进一步,所述resbus与ld/store相连接,并且通信方向是双向通信;
22、进一步,所述resbus与falu相连接,并且通信方向是双向通信;
23、进一步,所述resbus与alu相连接,并且通信方向是双向通信;
24、进一步,所述ld/store与private regs相连接,并且通信方向是从ld/store到private regs;
25、采用上述步骤的有益效果是:通过取指、译码、发射、执行、写回、总线、专有寄存器七个部分组成了多核处理器的cpu装置;该装置通过执行由内部存储单元中的指令对数据的处理操作,实现多核协同处理数据的目的;且该cpu核也可以独立运行,本发明适合于多核数据处理;结构简洁简单,效率高。
26、一种适用于多核数据处理器的cpu实现方法,包括以下步骤:
27、步骤1,取指;cpu启动后,cpu根据fetch模块发来的pc值,从instruction buffer中取出相应的指令,假如instruction buffer中没有相应地址的指令,则instructionbuffer会从code/data ram中把相应的指令取出来,放在instruction buffer中,同时把相应指令返回给fetch。
28、步骤2,译码;即对所有指令进行译码并保存在queue中。
29、首先,对所有指令进行分类,本发明中所有指令基本分为4类:跳转指令,falu指令,alu指令,访存指令即ld/store指令。其次,指令取出来后,根据指令的类型翻译成统一的规格以便于这些指令容易发射到各个执行单元。最后,指令译码之后,保存在queue中。
30、步骤3,发射;本发明采用乱序发射的机制;queue中的指令根据各个执行部件的状态决定是否把该指令发送到各个执行部件;queue这个部件同时执行跳转指令的功能。
31、进一步,本发明采用了最简单的跳转预测成功的模式;当是跳转指令时,等到所有所需的数据已经准备好了,才能执行。当该指令判断的结果是不跳转时,则需要取消所有之后的指令,包括instruction buffer,fetch,以及译码之后保存在queue中没有发出的指令。如果判断是跳转时,则继续执行。其它类型的指令,可以不需要等待数据准备好之后就可以发射;数据没有准备好的指令发到各个执行部件去等待数据准备好,之后再执行。
32、步骤4,执行;根据指令的类型,执行不同的运算指令。本发明包括falu指令,alu指令和访存指令即ld/store指令执行部件,falu指令部件主要执行浮点运算指令,alu指令部件主要执行定点运算指令,访存部件主要执行访存指令,包括ld和store指令。每个执行部件保存queue发射过来的相应命令;当发过来命令的数据没有准备好,则执行部件监听写回总线resbus的结果,假如写回总线的结果是需要的数据时,则数据准备好。当所有的数据准备好时,则可以根据命令实现执行操作。当访存指令的地址空间指向private regs时,则读写private regs的寄存器值。这些专有寄存器与各个核之间互联,实现多核之间的同步操作。当访存指令的控制指向外部地址空间时,则通过data_bus与外部地址空间进行数据交互。
33、步骤5,写回;当执行部件得到的结果后,数据返回到queue中的寄存器中。
34、本发明设计简单,设计一条写回总线,这样做的有益效果是这样执行部件同时有时间返回时,则根据部件的优先级进行仲裁一个结果返回,其它的执行部件则等待一下一个时钟周期返回结果。
35、本发明对硬件加速要求比较高的加速模块,如fft,卷积,矩阵乘法等,该cpu核可以实现对部分数据的处理,多个cpu核协同工作则可以完全处理整个功能;额外,每个微处理器适合于数据处理,结构简洁,控制简单;同时又可以处理各种不同应用场景的数据。
- 还没有人留言评论。精彩留言会获得点赞!