基于人体关键点检测和Transformer模型的老人吃药检测方法和系统与流程
基于人体关键点检测和transformer模型的老人吃药检测方法和系统
技术领域
1.本发明涉及机器学习领域和智慧养老服务领域,具体涉及基于人体关键点检测和transformer模型的老人吃药检测方法和系统。
背景技术:
2.随着人口出生率逐渐降低,我国逐渐进入老年社会,按照第七次全国人口普查统计,我国65岁及以上人口比例超过13.50%,人口老龄化程度已超过全球平均水平,我国人口老龄化问题日益严峻,如何让所有人“老有所养”成了我们必须要面对的问题。很多老人身患多种慢性病,这需要他们按时按量的正确吃药,但是老年人记忆差,有的甚至患有健忘症,对服用药物的时间和次数以及服用药物的种类和数量常混淆不清,而老人的子女也不能长期在身边进行提醒,很难保证老人能够定量正确吃药。这样不仅对病情不利,如果没有正确吃药甚至可能对老人的身体有药物毒副作用,因此让他们按量的正确吃药十分重要。现在的相关产品只能保证药物被正确取出,不能保证健忘的老人能够按量正确服用药物,且无法完成实时的全景检测。
技术实现要素:
3.为解决现有技术所存在的技术问题,本发明提供基于人体关键点检测和transformer模型的老人吃药检测方法和系统,通过人体各部位关键点来检测老人是否吃药,通过transformer时序模型可以提高对吃药、喝水等相似动作的区分度,准确检测老年人是否按量正确地完成吃药。
4.本发明的第一个目的在于提供基于人体关键点检测和transformer模型的老人吃药检测方法。
5.本发明的第二个目的在于提供基于人体关键点检测和transformer模型的老人吃药检测系统。
6.本发明的第一个目的可以通过采取如下技术方案达到:
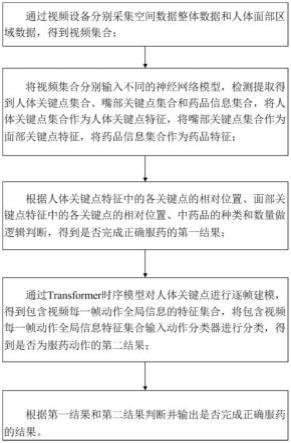
7.基于人体关键点检测和transformer模型的老人吃药检测方法,所述方法包括:包括以下步骤:
8.通过视频设备分别采集空间数据整体数据和人体面部区域数据,得到视频集合;
9.将视频集合分别通过不同的神经网络模型检测提取得到人体关键点集合、嘴部关键点集合和药品信息集合,将人体关键点集合作为人体关键点特征,将嘴部关键点集合作为面部关键点特征,将药品信息集合作为药品特征;
10.根据人体关键点特征中的各关键点的相对位置、面部关键点特征中的各关键点的相对位置、药品特征中药品的种类和数量做逻辑判断,得到是否完成正确服药的第一结果r1;
11.通过transformer时序模型对人体关键点特征进行逐帧建模,得到包含视频每一
帧动作全局信息的特征集合,将包含视频每一帧动作全局信息的特征集合输入动作分类器进行分类,得到是否为服药动作的第二结果r2;
12.根据第一结果r1和第二结果r2判断并输出是否完成正确服药的结果。
13.优选地,所述根据人体关键点特征中的各关键点的相对位置、面部关键点特征中的各关键点的相对位置、药品特征中药品的种类和数量做逻辑判断,得到是否完成正确服药的第一结果r1,包括:
14.当肘部关键点与对应体侧的肩部连线与身体中轴线所成的锐角大于三十度且腕部关键点高于肩部且低于鼻部时,视为手臂抬起,设定结果r
11
为真。
15.当嘴部轮廓点所围成的区域面积先增大再降低时,视为进行服药动作,设定结果r
12
为真。
16.当所药品特征中药品的种类和数量与数据库中的预设数据一致时,则视为正确服药,设定结果r
13
为真,否则视为不准确正确服药,设定结果r
13
为否;
17.将结果r
11
、结果r
12
和结果r
13
进行逻辑判断,当结果r
11
、结果r
12
和结果r
13
皆为真时,则结果r1为真,视为完成正确服药。
18.优选地,所述transformer时序模型包括transformer子模块,所述transformer子模块通过self-attention机制对得到的人体关键点特征进行逐帧建模:
[0019][0020][0021][0022][0023]
其中,q、k、v分别代表注意力机制中的query矩阵、key矩阵、value矩阵;wq,wk,wv均为用来抽象特征以形成上述query矩阵、key矩阵、value矩阵的向量,代表人体关键点特征j1中的每一个元素,为视频每一帧动作全局信息的特征,*表示矩阵乘法;
[0024][0025]
其中,xi为矩阵运算q*k
t
产生的结果矩阵中的每一个元素,n为结果矩阵所含的全部元素个数,是以自然对数e为底,xi为指数的幂运算。
[0026]
本发明的第二个目的可以通过采取如下技术方案达到:
[0027]
基于人体关键点检测和transformer模型的老人吃药检测系统,所述系统包括:
[0028]
视频采集模块,用于通过视频设备分别采集空间数据整体数据和人体面部区域数据,得到视频集合。
[0029]
特征提取与检测模块,用于将视频集合分别通过不同的神经网络模型检测提取得到人体关键点集合、嘴部关键点集合和药品信息集合,将人体关键点集合作为人体关键点特征,将嘴部关键点集合作为面部关键点特征,将药品信息集合作为药品特征。
[0030]
逻辑判断模块,用于根据人体关键点特征中的各关键点的相对位置、面部关键点特征中的各关键点的相对位置、药品特征中药品的种类和数量做逻辑判断,得到是否完成正确服药的第一结果r1;通过transformer时序模型对人体关键点特征进行逐帧建模,得到
包含视频每一帧动作全局信息的特征集合,将包含视频每一帧动作全局信息的特征集合输入动作分类器进行分类,得到是否为服药动作的第二结果r2;根据结果r1和结果r2判断并输出是否完成正确服药的结果。
[0031]
交互展示模块,将是否完成正确服药的结果信息通过文字显示或者通过语音播报。
[0032]
本发明与现有技术相比,具有如下优点和有益效果:
[0033]
本发明提供基于人体关键点检测和transformer模型的老人吃药检测方法和系统,通过运用了人体关键点检测技术,通过嘴部关键点判断老人是否将药物正常吞下,使用yolo分类算法判断药物的种类和数量,可以检测判断老人是否正确吃药;由人体关键点所建构的时序动作特征中,通过时序建模中的transformer框架,可以有效地利用由人体关键点建模产生的动作所隐含的时序信息,区分吃药、喝水等相类似的动作,能够准确检测老年人是否按量正确地完成吃药。
附图说明
[0034]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
[0035]
图1是本发明实施例中的老人吃药检测方法的流程图;
[0036]
图2是本发明实施例中的老人吃药检测方法逻辑框图。
具体实施方式
[0037]
下面将结合附图和实施例,对本发明技术方案做进一步详细描述,显然所描述的实施例是本发明一部分实施例,而不是全部的实施例,本发明的实施方式并不限于此。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0038]
实施例1:
[0039]
为了解决老人因健忘而无法按时按量正确吃药的问题,本发明结合深度学习的方法提供了基于人体关键点检测和transformer模型的老人吃药检测方法,本发明运用了人体关键点检测技术,通过嘴部关键点判断老人是否将药物正常吞下,使用yolo分类算法判断药物的种类和数量,可以检测判断老人是否正确吃药;由人体关键点所建构的时序动作特征中,通过时序建模中的transformer框架,可以有效地利用由人体关键点建模产生的动作所隐含的时序信息,区分吃药、喝水等相类似的动作。将全局的人体关键点、面部关键点以及药物信息作为条件判据,将时序的人体关键点传入transformer时序模型后进行动作分类,以提高对吃药、喝水等相似动作的区分度,从而降低误判率,可以准确检测老年人是否按时按量地正确吃药。
[0040]
如图1-2所示,本发明所述的基于人体关键点检测和transformer模型的老人吃药检测方法,包括步骤:
[0041]
s1、通过视频设备分别采集空间数据整体数据和人体面部区域数据,得到视频集
合vn。
[0042]
本实施例中,视频设备使用两个rgb-d摄像头(深度+彩色摄像头)或两个普通摄像头,分别用来采集空间数据整体数据和老人面部区域数据,得到视频集合vn。
[0043]
s2、将视频集合vn分别输入不同的神经网络模型,分别检测提取得到人体关键点集合、嘴部关键点集合、药品信息集合,将人体关键点集合作为人体关键点特征j1,将面部关键点中的嘴部关键点集合作为面部关键点特征j2,将药品信息集合作为药品特征j3。
[0044]
本实施例中,将视频集合vn复制三份,得到三个相同的视频集合视频集合和视频集合这样使得后续步骤能够并行计算,加快处理速度。
[0045]
根据视频集合通过由开源的pp-tinypose算法训练的神经网络模型,得到人体关键点集合,并将人体关键点集合作为人体关键点特征j1。其中,人体关键点共包括17个关键点,分别为:鼻子,左、右眼,左、右耳,左、右肩,左、右手肘,左、右手腕,左、右大腿根部,左、右膝,左、右脚踝。
[0046]
根据视频集合使用由开源的face_landmark算法训练的神经网络模型,得到面部关键点中的嘴部关键点集合,并将嘴部关键点集合作为面部关键点特征j2。其中面部关键点包括68个关键点,覆盖了脸部轮廓、眼部、鼻部以及嘴部,其中涉及到嘴部的关键点为第49个到第68个。
[0047]
根据视频集合使用由开源的yolov7算法训练的神经网络模型,得到由该模型预测得出的药品的数量和种类构成的药品信息集合,并将药品信息集合作为药品特征j3,即老人当前准备服用的药物的数量和种类。再定义特征集合j={j1,j2,j3}。
[0048]
使用由开源的pp-tinypose算法训练的模型,得到人体关键点集合并将其作为特征j1,该开源算法具有快速高精度的优点,且对微小目标检测效果较好。此外,该算法是轻量化的,适合在多种设备上进行快速部署。该算法采用采用自上而下的方式,先检测出人体框,再检测对应关键点,由此确保关键点检测的高精度;同时在预处理与后处理中加入aid和udp策略,在后处理中加入dark等策略,保证模型的高性能。aid策略即augmentation by information dropping,通过选择性的信息丢失,提升模型对关键点的定位能力。udp即unbiased data processing,通过使用无偏差数据的编码和解码提升模型精度。dark即distribution-aware coordinate representation of keypoints,通过引入分布-感知坐标来提升低分辨率热力图下模型的精度表现。
[0049]
使用由开源的face_landmark算法训练的模型,得到面部关键点中的嘴部关键点集合并将其作为特征j2,该算法采用多任务学习的方法、使用wing loss作为损失函数使得算法具有更好的拟合性,该算法可以实现人脸面部68个关键点快速检测。
[0050]
使用由开源的yolov7算法训练的模型,得到由药品的数量和种类构成的集合并作为特征j3,该算法通过卷积操作来提取特征并据此预测物体边框,然后通过nms非极大值抑制去除多余窗口得到检测框。在此基础上,对检测框进行计数即可得到待测物体的数量。
[0051]
s3、根据人体关键点特征j1中各关键点的相对位置、面部关键点特征j2中各关键点的相对位置、药品特征j3中药品的种类和数量做逻辑判断,得到是否完成正确服药的第一结果r1;通过transformer时序模型对人体关键点特征j1进行逐帧建模,得到包含视频每一帧动作全局信息的特征集合,将包含视频每一帧动作全局信息的特征集合合输入动作分类
器进行分类,得到是否服药动作的第二结果r2;根据第一结果r1和第二结果r2判断并输出是否完成正确服药的结果。。
[0052]
s31、根据人体关键点特征j1、面部关键点特征j2中各关键点的相对位置和药品特征j3中药品的种类和数量做条件判断,得到是否完成正确服药的第一结果r1,具体包括:
[0053]
(1)对于全局的人体关键点特征,当肘部(不区分左肘或右肘)关键点与对应体侧的肩部连线与身体中轴线所成的锐角大于三十度且腕部(不区分左腕或右腕)关键点高于肩部且低于鼻部时,视为手臂抬起,即结果r
11
为真。
[0054]
(2)对于局部的面部关键点特征,当嘴部轮廓点所围成的区域面积先增大再降低时,视为进行服药动作,即结果r
12
为真。
[0055]
(3)对于药品信息,将所获得的种类、数量以及当前服药时间与数据库中的预设数据比对,无误则代表正确服药。即r
13
为真。否则为否。若r
13
为否,系统发出语音警报“嘀嘀嘀,药品信息错误”的声音提示。数据库中的预设数据可由医生或家人根据医生的治疗意见设定。
[0056]
(4)将结果r
11
、结果r
12
和结果r
13
进行逻辑判断,当结果r
11
、结果r
12
、结果r
13
同时为真时,则结果r1为真,视为完成正确服药。
[0057]
s32、对通过transformer时序模型对人体关键点特征j1进行逐帧建模,得到包含视频每一帧动作全局信息的特征集合,将包含视频每一帧动作全局信息的特征集合输入动作分类器进行分类,得到分类结果r2。
[0058]
具体地,所述transformer时序模型包括至少一个transformer子模块,所述transformer子模块通过self-attention机制对得到的人体关键点特征j1进行逐帧建模:
[0059][0060][0061][0062][0063]
其中,q、k、v分别代表注意力机制中的query矩阵、key矩阵、value矩阵;wq,wk,wv均为用来抽象特征以形成上述query矩阵、key矩阵、value矩阵的向量,代表人体关键点特征j1中的每一个元素,为视频每一帧动作全局信息的特征,*表示矩阵乘法;
[0064][0065]
其中,xi为矩阵运算q*k
t
产生的结果矩阵中的每一个元素,n为结果矩阵所含的全部元素个数,是以自然对数e为底,xi为指数的幂运算。该操作的意义是对结果矩阵进行归一化,将每个元素所得到的权重作为该元素新的值。这样,即可得到被抽象表示之后的包含视频每一帧动作全局信息的特征集合
[0066]
self-attention机制具体包括:首先对人体关键点特征整体的每一部分进行遍历操作,计算该部分与组成整体的每一部分(包括其自身)的关联程度,然后对每一部分(包括其自身)按照关联程度分配一系列的权重参数,即注意力系数,将注意力系数与每一部分原
始值相乘即可得到新的特征表示。
[0067]
进一步地,第一个transformer子模块生成的包含视频每一帧动作全局信息的关键点特征集合输入到下一个transformer子模块中继续进行建模:
[0068][0069][0070][0071][0072]
这样,由此不断循环,直至最后一个transformer子模块建模完成,最终输出即可得到被抽象表示之后的包含视频每一帧动作全局信息的关键点特征集合
[0073]
为了能快速聚合视频中的时序信息,transformer时序模型可以采用多层soft-attention机制,并且,transformer时序模型在宽度方面可以采用multi-head机制。
[0074]
在soft-attention中,注意力系数为[0,1]之间的小数,使得关注度细致化。
[0075]
在multi-head机制中,通过将多个self-attention模块并行以获得多方面的关联程度,进而提高特征表达能力。
[0076]
将包含视频每一帧动作全局信息的关键点特征集合输入动作分类器中进行分类并对其结果进行softmax归一化,得到结果r2,当r2为吃药动作时,视为真(即完成服药);若r1、r2为真(即完成服药)则视为完成吃药动作。
[0077]
动作分类器包括分值回归器和分类器,所述分值回归器和分类器分别通过两层全连接层实现,分值回归器用于计算视频每一帧中各类可能动作的得分并对视频每一类动作的得分进行softmax归一化,分类器用于分类选取动作得分值最大对应的动作作为分类结果r2。
[0078]
全连接层为:
[0079][0080]
这样即可计算出每一类动作的得分,即分别对应n个不同类动作的得分,然后对其进行softmax归一化,取从a1到an这n个数中最大的数所对应的动作作为分类结果r2,若得到分类结果r2为吃药动作,则视r2为真(即完成服药),否则r2为假。例如,r2的结果可能是多类动作中具体的一个,比如喝水动作、吃药动作、吃饭动作等具体的一个,当喝水动作得分0.3、吃药动作得分0.5、吃饭动作得分0.2,则吃药动作得分最高,吃药动作为结果r2,那么视结果r2为真。当喝水动作得分0.5、吃药动作得分0.2、吃饭动作得分0.3,则喝水动作得分最高,喝水动作为结果r2,结果r2不是吃药动作,那么视结果r2为不真。
[0081]
s33:当逻辑判断结果r1、分类结果r2都为真时则视为完成吃药动作,否则视为未完成吃药动作。
[0082]
s34、将是否完成正确服药的结果信息通过文字显示或者通过语音播报。
[0083]
本实施例中,可以将最终是否完成正确服药的结果信息传入交互展示模块,将“完成吃药”的信息显示在app客户端上或者通过语音播报提示“完成吃药”。
[0084]
本实施例采用了深度学习的方法提供了一种基于人体关键点检测和transformer技术的老人吃药检测方法,运用了人体关键点检测技术来判断吃药动作,利用面部关键点的嘴部关键点来判断老人将药物是否正常吞下,使用yolo分类算法判断药物的种类和数量来判断老人是否正确吃药,通过采用时序建模中的transformer框架可以有效地利用由人体关键点建模产生的动作所隐含的时序信息,区分吃药、喝水等相类似的动作,从而解决老人因健忘而无法按时按量正确吃药的问题。
[0085]
与现有技术相比,本发明不需要额外的设备,只需两个摄像头来采集信息即可,同时摄像头也可作为监控使用,具有复用性;能对动作中所蕴含的时序信息进行有效建模,充分挖掘有用信息;由人体关键点所建构的时序动作特征中,经过transformer模型后能够区分喝水、吃药等相似行为,避免误判;可以将关键点判据替换为其他动作,完成对老人所有物理行为的检测,具有很好的可拓展性。
[0086]
实施例2:
[0087]
本实施例提供了基于人体关键点检测和transformer模型的老人吃药检测系统,包括视频采集模块、特征提取与检测模块、逻辑判断模块和交互展示模块,具体模块的功能如下:
[0088]
视频采集模块,用于通过视频设备分别采集空间数据整体数据和人体面部区域数据,得到视频集合。
[0089]
特征提取与检测模块,用于将视频集合分别通过不同的神经网络模型检测提取得到人体关键点集合、面部关键点中的嘴部关键点集合和药品信息集合,将人体关键点集合作为人体关键点特征,将嘴部关键点集合作为面部关键点特征,将药品信息集合作为药品特征。
[0090]
逻辑判断模块,用于根据人体关键点特征中的各关键点的相对位置、面部关键点特征中的各关键点的相对位置、药品特征中药品的种类和数量做逻辑判断,得到是否完成正确服药的第一结果r1;通过transformer时序模型对人体关键点特征进行逐帧建模,得到包含视频每一帧动作全局信息的特征集合,将包含视频每一帧动作全局信息的特征集合输入动作分类器进行分类,得到是否为服药动作的第二结果r2;根据第一结果r1和第二结果r2判断并输出是否完成正确服药的结果。
[0091]
交互展示模块,将是否完成正确服药的结果信息通过文字显示或者通过语音播报。
[0092]
优选地,所述将视频集合分别通过不同的神经网络模型检测提取得到人体关键点集合、面部关键点中的嘴部关键点集合和药品信息集合,包括:将视频集合复制三份,得到三个相同的视频集合视频集合视频集合根据视频集合通过由开源的pp-tinypose算法训练的神经网络模型检测提取得到人体关键点集合并;根据视频集合使用由开源的face landmark算法训练的神经网络模型检测提取得到面部关键点中的嘴部关
键点集合;根据视频集合使用由开源的yolov7算法训练的神经网络模型检测提取得到由药品的数量和种类构成的药品信息集合。
[0093]
所述的基于人体关键点检测和transformer模型的老人吃药检测方法,其特征在于,所述根据人体关键点特征中的各关键点的相对位置、面部关键点特征中的各关键点的相对位置、药品特征中药品的种类和数量做逻辑判断,得到是否完成正确服药的第一结果r1,包括:
[0094]
当肘部关键点与对应体侧的肩部连线与身体中轴线所成的锐角大于三十度且腕部关键点高于肩部且低于鼻部时,视为手臂抬起,设定结果r
11
为真。
[0095]
当嘴部轮廓点所围成的区域面积先增大再降低时,视为进行服药动作,设定结果r
12
为真。
[0096]
当所药品特征中药品的种类和数量与数据库中的预设数据一致时,则视为正确服药,设定结果r
13
为真,否则视为不准确正确服药,设定结果r
13
为否;
[0097]
将结果r
11
、结果r
12
和结果r
13
进行逻辑判断,当结果r
11
、结果r
12
和结果r
13
皆为真时,则结果r1为真,视为完成正确服药。
[0098]
所述transformer时序模型包括transformer子模块,所述transformer子模块通过self-attention机制对得到的人体关键点特征进行逐帧建模:
[0099][0100][0101][0102][0103]
其中,q、k、v分别代表注意力机制中的query矩阵、key矩阵、value矩阵;wq,wk,wv均为用来抽象特征以形成上述query矩阵、key矩阵、value矩阵的向量,代表人体关键点特征j1中的每一个元素,为视频每一帧动作全局信息的特征,*表示矩阵乘法;
[0104][0105]
其中,xi为矩阵运算q*k
t
产生的结果矩阵中的每一个元素,n为结果矩阵所含的全部元素个数,是以自然对数e为底,xi为指数的幂运算。
[0106]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1