一种入院记录缺失文本补充方法与流程
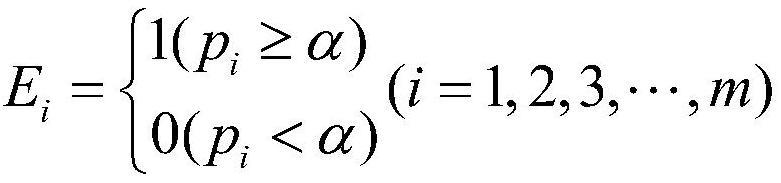
本发明涉及自然语言处理,具体涉及一种入院记录缺失文本补充方法。
背景技术:
1、电子病历的应用,为医生书写病历节省了大量的宝贵时间,同时医生在入院记录的书写过程会因为打字错误或者套用电子病历模板而引起一些病历出现缺失文本的情况,导致一些重要的指标没有在电子病历中呈现。这些缺失文本的存在会导致入院记录的书写质量低下,甚至引发一些医患纠纷。由于医院中每天产生数以千计的入院记录,医生除了书写入院记录之外还有大量的工作,所以没有大量的时间对书写的入院记录进行一遍一遍的查看修改。利用人工智能技术对入院记录中存在的缺失文本的位置自动检测和自动补充是提高入院记录书写质量和减轻医生修改入院记录负担的最有效的途径之一。
2、基于有监督学习的方式,需要人工对入院记录出现的缺失文本的位置进行标注,然而医学领域文本数据的标注对标注人员的素质要求较高,这就会导致时间和人力成本较高昂。在通用领域常常会bert模型检测缺失字的位置,然后通过对缺失字的位置设置mask标签来对相应位置的缺失字的进行填充。但是入院记录作为医院中的大病历,要求覆盖内容比较全面,因此入院记录的文本长度较长,存在大量大于1000字的单段文本。而bert模型适用的文本长度不能超过512字,transformer模型随着文本的长度增长计算量指数级增大。使用文本槽填充的方式需要对缺失字的位置添加占位符,这需要提前获取到缺失字的字数,按照字数创建相关数量的占位符来对文本进行填充,这对于缺失单字的文本填充效果还好,但是对于入院记录中缺失文本较长的文本,识别的效果和填充准确率很低。虽然使用传统的序列到序列模型,给定存在缺失文本的入院记录,来生成一段正确的入院记录文本可以来实现对入院记录缺失文本的补充,但是一段入院记录中存在缺失文本的字数相较于整个病历文本的字数很少,采用上述方式会造成大量的计算资源浪费,也会导致补充后的入院记录和之前的入院记录存在较大的差异,达不到对于缺失文本的位置定点补充的效果。因此入院记录中缺失文本补充的问题,利用常规的补充方式不能很好的解决。
技术实现思路
1、本发明为了克服以上技术的不足,提供了一种可以更好的识别与补充入院记录中的缺失文本的方法。
2、本发明克服其技术问题所采用的技术方案是:
3、一种入院记录缺失文本补充方法,包括如下步骤:
4、a)建立入院记录文本数据集;
5、b)对入院记录文本数据集进行数据预处理操作,利用预处理后的入院记录文本数据集构建入院记录缺失文本位置识别训练样本,根据入院记录缺失文本位置识别训练样本构建缺失文本补充模型训练样本;
6、c)利用缺失文本位置识别训练样本训练基于longformer缺失文本位置识别模型,得到入院记录缺失文本位置识别训练样本中文本的标签序列,通过损失函数训练缺失文本位置识别模型,得到训练后的缺失文本位置识别模型;
7、d)建立缺失文本补充模型;
8、e)计算损失函数,利用损失函数训练缺失文本补充模型;得到训练后的缺失文本补充模型;
9、f)接收输入入院记录数据,对该入院记录数据进行预处理操作;
10、g)将预处理后的入院记录数据输入到训练后的缺失文本位置识别模型中,输出入院记录数据的文本标签序列;
11、h)将预处理后的入院记录数据和入院记录数据的文本标签序列输入到训练后的缺失文本补充模型中,输出得到g个补充的缺失文本序列。
12、优选的,步骤a)中入院记录文本数据集包括:医院各个科室产生的入院记录文本,所述入院记录文本的内容包括:主诉、现病史、个人史、既往史、婚姻史、体格检查、辅助检查、初步诊断。
13、进一步的,步骤b)包括如下步骤:
14、b-1)以入院记录文本数据集中的段落为单位构建样本,对样本中前后的空格进行删除,对样本中连续的多个空格替换成单一空格,完成入院记录文本数据集的预处理操作;
15、b-2)预处理后的入院记录文本数据集中的入院记录缺失文本类型包括:因打字原因造成单个字词或标点的缺失、因引用病历模板造成描述性语言的缺失、因病历模板中缺乏要点造成的要点的缺失,对于因打字原因造成单个字词或标点的缺失采用随机删除的方式对预处理后的入院记录文本数据集中的单个字词或者标点符号进行删除,然后对预处理后的入院记录文本数据集中的文本序列构建标签,如果文字的前一个位置或后一个位置存在缺失文本,则该文字的标签为1,如果文字的前一个位置或后一个位置不存在缺失文本,则该文字的标签为0,对于因引用模板造成描述性语言的缺失根据病历模板中的指标名称随机将指标中的描述语句删除,删除后对预处理后的入院记录文本数据集中的文本序列构建标签,如果文字的前一个位置或后一个位置存在缺失文本,则该文字的标签为1,如果文字的前一个位置或后一个位置不存在缺失文本,则该文字的标签为0,对于因病历模板中缺乏要点造成的要点的缺失随机删除掉两个语义分隔符中的文本内容,删除后对预处理后的入院记录文本数据集中的文本序列构建标签,如果文字的前一个位置或后一个位置存在缺失文本,则该文字的标签为1,如果文字的前一个位置或后一个位置不存在缺失文本,则该文字的标签为0,完成入院记录缺失文本位置识别训练样本的建立;
16、b-3)步骤b-2)中删除的预处理后的入院记录文本数据集中的单个字词或者标点符号、随机删除的指标中的描述语句、随机删除的两个语义分隔符中的文本内容中共包含j个由字和标点构成的字符,将所有删除的j个字符构成目标序列文本,将删除后的文本、文字标签以及目标序列文本组成缺失文本补充模型训练样本。优选的,步骤b-2)中的语义分隔符为句号或逗号。
17、进一步的,步骤c)包括如下步骤:
18、c-1)利用字嵌入法将入院记录缺失文本位置识别训练样本中每一个字映射成一个n维的实数向量,利用m×n的矩阵表示输入的样本,m为入院记录缺失文本位置识别训练样本中字的个数;
19、c-2)将m×n的矩阵输入到longformer模型中,输出得到状态s,通过公式计算得到输入的样本中每个字作为正样本的概率值p,式中e为自然常数,w为权重矩阵,b为偏置向量,p={p1,p2,...,pi,...,pm},pi为第i个字的预测为正样本的概率值,i∈{1,2,...,m};
20、c-3)通过公式计算得到入院记录缺失文本位置识别训练样本中第i个字的标签ei,α为判定标签为1的阈值,0<α<1,得到入院记录缺失文本位置识别训练样本中文本的标签序列e,e={e1,e2,...,ei,...,em};
21、c-4)通过公式计算得到损失函数l,yi为第i个字的类别,正类别定义为1,负类别定义为0,t为负样本对整体损失的贡献比率,0<t<1;
22、c-5)利用损失函数l采用随机梯度下降法训练缺失文本位置识别模型,得到训练后的缺失文本位置识别模型。
23、进一步的,步骤d)包括如下步骤:
24、d-1)建立由编码器和解码器组成的缺失文本补充模型,所述编码器由双向长短期记忆神经网络bilstm构成,所述解码器由长短期记忆神经网络lstm构成;
25、d-2)缺失文本补充模型训练样本中每一个字映射成一个n维的实数向量,利用矩阵i1表示缺失文本补充模型训练样本,为实数空间,将入院记录缺失文本位置识别训练样本中第i个字的标签ei映射成一个n维的实数向量,利用矩阵i2表示缺失文本补充模型训练样本的缺失的字的标签,通过公式i=i1+i2计算得到模型输入数据i,将模型的输入数据i输入到编码器中,输出得到状态张量g,l为缺失文本补充模型训练样本的长度,h为隐藏层的维度;
26、d-3)设定一个起始符<start>作为预测补充文本序列的第一个字,将起始符<start>的字向量c<start>及状态张量g中最后一维的张量gl输入到解码器中,计算得到第一个字的状态向量h1,其中
27、d-4)通过公式计算得到第一个字的状态向量h1与状态张量g的连接矩阵q,其中为向量首尾相连操作,gi为状态张量g中第i个一维的张量,i∈{1,2,...,l},
28、d-5)通过公式β=g*softmax(v*mlp1(q)t)计算得到解码器生成的文字与输入的缺失文本补充模型训练样本的关系权重值β,式中v为参数矩阵,softmax(·)为归一化函数,mlp1(·)为线性变化操作,连接矩阵q通过线性变化操作将其维度从2h变换为h,t为矩阵转置,
29、d-6)通过公式计算得到解码器解码的第一个字的概率向量wp1,式中mlp2(·)为线性变化操作,通过线性变化操作将其维度从h变换为s,s为字表的长度;
30、d-7)获取概率向量wp1中概率最大的值的位置在字表中所对应的文字w1作为生成的第一个字;
31、d-8)将文字w1对应的字向量和第一个字的状态向量h1输入到解码器中,重复执行步骤d-3)至步骤d-8)计算得到下一个字的状态向量h2和生成的文字w2;
32、d-9)将文字w2替代步骤d-7)中的文字w1,重复执行步骤d-7)至d-8)直至生成文字wk作为终止符号<end>,k∈{1,2,...,l},l为生成的文本的长度,完成缺失文本的补充,得到补充的缺失文本序列{w1,w2,...,wl-1}。
33、进一步的,步骤e)包括如下步骤:
34、e-1)通过公式计算得到损失函数loss,式中yki为符号函数,如生成的第k个文字等于字表中的第i个字,则yki取1,如生成的第k个文字不等于字表中的第i个字,则yki取0,wpki为生成的第k个文字预测为字表中第i个字的概率;
35、e-2)利用损失函数loss采用梯度下降法训练缺失文本补充模型。
36、优选的,c-3)中α取值为0.5。
37、本发明的有益效果是:解决了文本序列中存在较长文本缺失,无法定点补充的问题,又解决了序列到序列模型长文本解码消耗计算资源大的问题。解决了医生因打字或者引用模板的原因引起的入院记录文本缺失问题,提高了医生对入院记录缺失文本补充的效率,极大提高了医生书写入院记录的质量。通过缺失文本位置识别模型识别文本中存在缺失文本的位置,缺失文本补充模型针对存在的缺失文本给出修改方案的方式进行相互验证,将缺失文本位置误检的数据过滤掉一部分,进一步提高了入院记录缺失文本补充的准确率。
- 还没有人留言评论。精彩留言会获得点赞!