基于密度峰值聚类的高斯混合模型核电运行工况划分方法
本发明涉及核电运行工况监测,具体涉及一种基于密度峰值聚类的高斯混合模型核电运行工况划分方法。
背景技术:
1、核电的运行工况划分正是核电运行监测的基础,因此一种有效的核电运行工况划分方法十分重要。
2、目前,核电运行工况的划分仍然以专家经验为主,通过运行人员的经验来对核电运行工况进行划分,但是随着核电数字化和智能化,人工经验已无法满足核电厂的需求,所以急需发展一种自动划分核电运行工况的方法。由于核电厂内部过程的复杂性和影响因素的多样性,核电运行工况的准确个数无法直接得到,而聚类算法可对不同数据按内在相似性进行分类,因此可选用聚类方法来完成对核电运行工况的划分工作。
3、对于工况划分问题,有k-means聚类算法,ticc聚类算法以及传统的高斯混合模型可以作为选择,但是k-means聚类算法对初始聚类中心的依赖非常严重,对非凸数据集的聚类效果欠佳,且会出现局部最小值的情况。ticc聚类算法时间窗的大小需要靠先验知识确定,造成了该方法的适用性不强。传统的高斯混合模型存在着对聚类初值敏感,处理高维数据时计算难度大的问题。这三种聚类方法无法很好的适用于高维的核电厂时序数据。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于密度峰值聚类的高斯混合模型核电运行工况划分方法,该方法能够解决传统高斯混合模型的缺点,提高工况划分的准确性,对于高维的核电厂运行数据的工况划分起到了良好的效果。
2、本发明采取的技术方案为:
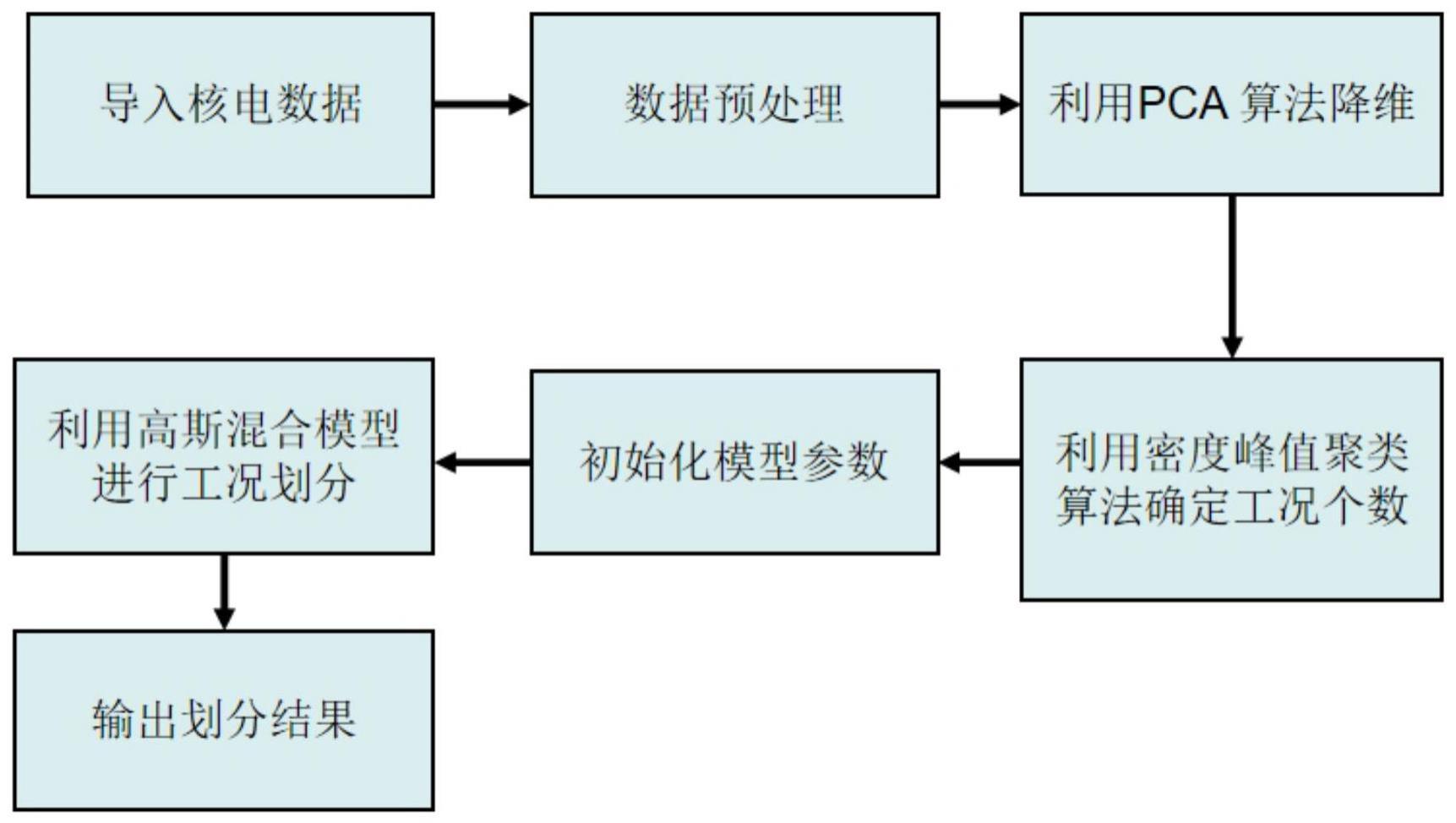
3、基于密度峰值聚类的高斯混合模型核电运行工况划分方法,包括以下步骤:
4、步骤1:对核电运行数据进行预处理,对核电数据进行降噪;
5、步骤2:利用pca算法对高维核电运行数据进行特征提取;
6、步骤3:利用密度峰值聚类算法对步骤2中pca算法降维后的数据进行聚类,确定核电运行工况数;
7、步骤4:利用高斯混合模型在聚类参考初值的情况下完成对核电工况的划分工作,并实现划分结果可视化。
8、所述步骤1中,选择使用小波包分解重构的方法实现数据降噪。对输入信号,根据数据长度和波函数,确定合适的最大分解层数,将输入信号按小波树分解成多个成分,之后按照频率信息对每一层的各成分重新排序,按照设定规则挑选合适的成分后重构数据,达到降噪效果;
9、所述步骤2所包含的以下步骤:
10、s2.1、对原始数据进行归一化处理,消除量纲影响;
11、μ=(x1+...+xn/n;
12、其中:x1...xn表示各个时间点所记录的原始数据,n表示所记录到的数据个数;μ为变量的均值;
13、
14、
15、其中:δ为变量的标准差,xi*是标准化后的变量。最终得到归一化的数据矩阵x。其中数据矩阵x是指将原始数据按上述方法归一化后所得到的矩阵,每一列为各传感器的数据,一行代表一个时间点的数据。
16、s2.2、对归一化的数据矩阵x的协方差矩阵s进行特征值分解,获得对角矩阵λ。
17、
18、λ是协方差矩阵s的非负的实特征值di并递减排列,v是正交单位特征向量。
19、
20、s2.3、取出对角矩阵λ中最大的几个值及其对应的特征向量。
21、θ=(d1+...+dm)/(d1+...+di);
22、d1...dm为从对角矩阵中最大的几个值;d1...di为对角矩阵中的所有特征值。
23、s2.4、将原始特征投影到选取出的特征向量上,得到降维后的矩阵x*,从而达到降维的目的。
24、x*=xm;
25、m为步骤2.3中寻找到的几个最大特征值所对应的特征向量所组成的矩阵,该矩阵被作为投影向量矩阵。
26、所述步骤3所包含的以下步骤:
27、s3.1、计算聚类中心的局部密度ρi:聚类中心的密度大于周围区域的密度,即寻找与聚类中心点距离dij小于截断距离的数据点dc的个数。
28、
29、χ表示的是满足聚类中心点距离dij小于截断距离的数据点dc的个数;j表示的任一散点。
30、
31、s3.2、计算聚类中心点的距离δi:
32、
33、dij指的是任意散点j与聚类中心点i的距离。j:ρi>ρj指的是在在所有的比i点的局部密度都大的样本点中,找到与i点距离最小的一个。
34、s3.3、决策图将同时满足具有较大密度和较大距离的点认定为类簇中心。这样的簇类中心的个数,即为工况数n。
35、所述步骤4所包含的以下步骤:
36、s4.1、将步骤3中获得的工况数作为聚类初始值的参考值;
37、s4.2、利用em算法优化参数,同时利用模型的响应度来剔除响应度低的分类。
38、高斯混合模型的概率密度函数描述为:
39、
40、其中:αk为第k个高斯分布出现的概率,可得θk为第k个高斯模型的参数,其中包含了均值和方差,f(x|θk)就是第k个高斯模型的概率密度函数。
41、计算得到关于第k个高斯模型的响应度γk:
42、
43、em算法可分为两步,在进行这两步工作之前需要设定子分布模型的参数的初值。
44、e步:求取第k个分模型的对当前观测数据的响应度;
45、m步:迭代求取新一轮的模型参数:期望μ'k,方差权重α'k,当迭代满足|αk-αk-1|<=ε时即可终止迭代,ε为阈值。
46、
47、
48、
49、s4.3、获得划分结果,并使划分结果可视化。
50、所述步骤4.3所包括以下步骤:
51、步骤4.3.1:将划分结果,即各个工况的数据点集以不同颜色区分,不属于任何工况的数据点以原始点表示。
52、步骤4.3.2:将各个工况的所属数据点,按照所对应的时间戳依次还原至各个传感器数据之上;
53、与现有的人工经验划分方法以及其他聚类方法相比,本发明一种基于密度峰值聚类的高斯混合模型核电运行工况划分方法,技术效果如下:
54、1)本发明方法在保留数据特征的前提下,消除了数据中的噪声。解决了核电厂数据中含有噪声的问题。
55、2)本发明利用pca算法对高维的核电时序数据进行降维,解决了高斯混合模型在处理高维核电数据时出现的计算困难的问题。
56、3)本发明通过峰值密度聚类的决策图确定工况分类数,为高斯混合模型提供聚类参考值,解决高斯混合模型对聚类初值敏感的问题。
57、4)本发明可实现自动划分核电运行工况,提高划分效率;可对高维核电数据进行综合分析,获得更为准确的划分结果。
58、5)本发明消除了传统的聚类方法对聚类初值敏感,以及在处理高维数据时出现的计算难度大的问题。
59、6)本发明可以区别出不属于任何工况的处于变化状态的运行状态,实现了工况划分结果的可视化,核电运维人员更为直观的看到工况划分结果。
- 还没有人留言评论。精彩留言会获得点赞!