一种面向高速图像采集的超分辨率系统和方法
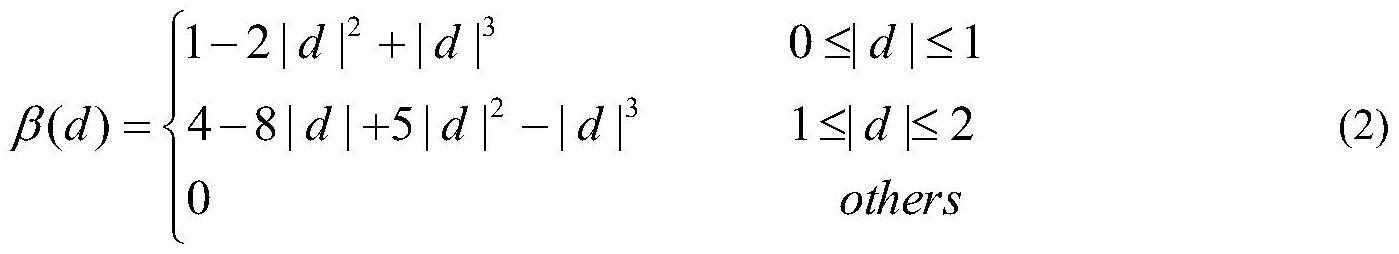
本发明属于fpga平台算法硬件加速的,具体涉及一种面向高速图像采集的超分辨率系统和方法。
背景技术:
1、高速移动的无人机在对地面进行监测时,往往会使用高帧率机载相机进行拍摄,但由于传输带宽和机载计算机算力的限制,通常搭载的相机分辨率较低,因而其向地面站传回的图像模糊、缺少细节,难以满足高精度监测的需求。
2、超分辨率(super-resolution),又称为上采样(upscale),是一类提高视频或图像分辨率及质量的算法,在监控视频处理、高分辨率摄像以及电影修复等视频编辑和图像处理领域应用十分广泛,可实现将地面站接收到的低分辨率图像转换为高分辨率图像的功能。
3、超分辨率算法中的传统插值算法以其算式规整、易于硬件实现等优势,仍存在较大的研究价值和硬件实现意义。传统插值算法主要包括最邻近插值法、双线性插值法和双三次插值法等。其中最邻近插值法简单快速,但插值输出图像质量不高。双线性插值法具有低通滤波器的属性,削弱了图像信息中的高频分量,导致插值输出图像边缘模糊。双三次插值法用插值点附近的4×4点阵(共16个点)作为参考,求得插值点像素值,其克服了最邻近插值法的阶梯边界问题,图像边缘的插值效果优于双线性插值。
4、双三次插值算法主要有两种实现方式:16点-普通双三次插值法和16点-卷积双三次插值法,其主要区别在于求解插值核的方式不同。前者根据卷积核的双三次项公式,求得插值系数;后者将二维平面插值核的求解化简为x方向和y方向,先后计算每个一维方向上的插值点系数,求得插值系数。16点-卷积双三次插值法算式简洁,x方向和y方向的硬件实现电路可以复用。
5、但是现有方法,横向窗和纵向窗未分离,需要缓存16个原始像素点,增加了硬件消耗和等待时间。
6、此外,16点-卷积双三次插值法首先在x方向和y方向进行系数计算,现有方法通常选取α=-0.5或α=-0.75作为插值算法的卷积核系数,由于通用计算机平台使用浮点alu(算术逻辑单元)进行运算,选择带有小数位的系数并不会产生额外的计算开销,同时由于浮点数极大的动态范围,额外的小数位也可以被其精确的表示而不会引入误差。但对于fpga平台来说,浮点运算的速度极慢,同时也会产生大量资源开销,而定点运算单元对于数据位宽十分敏感,现有方案使用α=-0.5或α=-0.75会导致参与运算的数据位宽成倍增加并带来额外的资源消耗,若为节省此消耗舍弃低位数据维持数据位宽,则会恶化插值图像的质量。同时目前16点-卷积双三次插值法并没有考虑4倍上采样时的特殊优化,对于4倍上采样,若直接插值,则在相邻两参考点间插入的点数并不固定,这样则需统计两参考点间所需插入的点数,引入了额外的计算复杂度。另外,由于相对距离不规则,在定点计算中需用有限小数近似表示无限小数,这带来了舍入误差。此外,现有方案在计算插值系数时使用不同的相对距离进行运算,其通过化简算式减少了加法与乘法的计算量,但并没有考虑到多级流水线带来的累计误差。
7、最佳架构是准确性和硬件成本之间的最佳权衡。因此必须在输出图像质量、硬件资源消耗和吞吐量性能方面仔细研究。g.mahale等人所提出的双三次插值架构可生成高质量的上采样图片,但需要非常多的输出资源,能耗极高。a.nuno-magand、k.gribbon、f.sabetzadeh等人实现了双三次插值,这些架构将整个图像像素存储在外部存储器中,因此,需要相当大的外部存储器。这种外部存储器增加了系统的整体成本,降低了性能,并增加了功耗。同时目前大多数利用fpga进行图像双三次插值的硬件实现方案使用浮点单元。浮点单元会造成很大的面积开销,产生高功率,并影响系统的整体性能。
8、综上所述,尽管基于16点-卷积双三次线性插值的超分辨率硬件系统设计已经存在多种解决方案,但是仍缺少一种兼顾硬件资源消耗、输出图像质量和吞吐量性能的方法。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种面向高速图像采集的超分辨率系统和方法,提高了处理效率,降低了资源消耗。
2、本发明通过以下技术方案实现:
3、一种面向高速图像采集的超分辨率系统,包括:padding模块、linebuffer模块、bicubic顶层计算模块和移位寄存器;
4、padding模块,用于对原始图像进行补充,输出补充图像至linebuffer模块;
5、linebuffer模块,用于对补充图像进行行缓存,按顺序同步输出四行数据;
6、bicubic顶层计算模块,用于接收linebuffer模块输出的四行数据,通过纵向窗按列计算一维插值中间结果并暂存在移位寄存器中,四列计算完成后,通过横向窗按行计算一维插值中间结果的一维插值,得到插值点像素值并输出。
7、优选的,bicubic顶层计算模块包括三个单通道模块,分别为r通道模块、g通道模块和b通道模块;每个单通道模块均包括bicubic模块;
8、bicubic顶层计算模块,用于接收linebuffer模块输出的四行数据,并将四行数据的r、g、b像素值分别送入r通道模块、g通道模块、b通道模块;各单通道模块的bicubic模块通过纵向窗按列计算一维插值中间结果并暂存在移位寄存器中,四列计算完成后,通过横向窗按行计算一维插值中间结果的一维插值,分别得到插值点的r、g、b像素值,将插值点的r、g、b像素值拼接得到插值点像素值并输出。
9、进一步的,linebuffer模块提供使能信号,用于开启bicubic模块进行运算。
10、进一步的,bicubic模块包括cal_b模块、cal_q模块、shift_reg模块、cal_b_post模块和cal_q_post模块;
11、cal_b模块,用于接收四行数据,依次进行乘二操作、减法运算和加法运算,得到四个中间系数输出至cal_q模块;
12、cal_q模块,用于接收cal_b模块输出的四个中间系数,依次通过乘法操作和两级加法树,得到一维插值中间结果输出至shift_reg模块;
13、shift_reg模块,用于接收cal_q模块输出的一维插值中间结果并通过移位寄存器进行缓存,实现四点一维插值中间结果并行输出至cal_b_post模块;
14、cal_b_post模块,用于接收shift_reg模块输出的四点一维插值中间结果,依次进行乘二操作、减法运算和加法运算,得到四个横向中间系数并输出至cal_q_post模块;
15、cal_q_post模块,用于接收cal_b_post模块输出的四个横向中间系数,依次通过乘法操作和两级加法树,得到二维插值结果,即插值点的r、g或b像素值。
16、进一步的,cal_q模块,将接收的输入四个中间系数与预存参数进行运算,第一级完成乘法操作,然后通过两级加法树得到一维插值中间结果。
17、进一步的,cal_q_post模块,将接收的四个横向中间系数与预存参数进行运算,第一级完成乘法操作,然后通过两级加法树得到二维插值结果;
18、cal_q_post模块设置四个,每个cal_q_post模块的预存参数不同,四个cal_q_post模块并行计算,在一个时钟周期得到相邻四个点的二维插值结果。
19、一种面向高速图像采集的超分辨率方法,包括:
20、s1,对原始图像进行补充,得到补充图像;
21、s2,对补充图像进行行缓存,得到四行数据;
22、s3,将四行数据通过纵向窗按列进行一维插值得到一维插值中间结果并暂存,四列计算完成后,通过横向窗按行对一维插值中间结果进行一维插值,得到插值点像素值。
23、优选的,s1具体是:将原始图像边缘的像素值赋给原始图像需补充的像素点,得到补充图像。
24、优选的,s3中,进行一维插值时,按照固定间隔插入插值点的规则进行。
25、优选的,s3中,一维插值采用的卷积核如下:
26、
27、其中,|d|为插值点到参考点的距离。
28、与现有技术相比,本发明具有如下的有益效果:
29、本发明超分辨率系统,基于16点-卷积双三次插值算法,bicubic顶层计算模块通过纵向窗先按列计算一维插值中间结果,将算出的一维插值中间结果暂存在移位寄存器中,每周期向右滑动一次;4个周期后,横向窗按行计算一维插值中间结果的一维插值,采用移位寄存器进行缓存并实现4点一维插值中间结果值并行输出,能对运算过程中的中间结果进行高效复用,可以在纵向窗并行度减少到1的同时保持输出数据不变,从而节省硬件资源,在一定程度上降低了资源消耗。本发明为高频率、低功耗的超分辨率系统,此系统实现将地面站接收到的低分辨率图像转换为高分辨率图像的功能,可满足无人机系统在高速移动下的高精度监测需求。
30、进一步的,将运算中用到的常数(如两个插值点之间的距离d)预先存储在硬件中,从而避免了大量的冗余运算。
31、本发明超分辨率方法,基于16点-卷积双三次插值算法,通过纵向窗先按列计算一维插值中间结果,将算出的一维插值中间结果暂存,每周期向右滑动一次;4个周期后,横向窗按行计算一维插值中间结果的一维插值,通过缓存的方式实现4点一维插值中间结果值并行输出,从而对运算过程中的中间结果进行高效复用,可以在纵向窗并行度减少到1的同时保持输出数据不变,从而节省硬件资源,在一定程度上提高了资源利用率。
32、进一步的,在本发明中,将原始图像最外圈即边缘的像素值赋给了需要填充的值,从而能够最大程度地使得插值点不失真。
33、进一步的,考虑到直接4倍上采样会使参考点之间插入不同个数的点数引起额外的资源消耗和精度损失,本发明通过padding使待插值点均匀的分布于参考点之间,并且其与参考点间的相对距离为固定的数,即|d|固定,可以减少硬件消耗。
34、进一步的,本发明在参数选取过程中考虑到现有方案可能引入的误差和计算量,选择α=-1作为卷积核参数,避免卷积核参数中出现小数,同时规避因引入除法器执行单元造成流水线延迟恶化,提高卷积核计算的流水线吞吐率。
- 还没有人留言评论。精彩留言会获得点赞!