神经网络模型生成、生理数据分类、以及患者临床分类
本发明涉及用于生成神经网络的方法,特别涉及用于特定应用的自动神经网络设计,例如生理数据的分类以及对患者进行临床分类。
背景技术:
1、神经网络正被在越来越多的领域中用于各种目的,包括数据分类。一种流行的神经网络类型是卷积神经网络。卷积神经网络(cnn)是具有至少一个卷积运算层的网络,并且是权重共享机制的一个示例。
2、第一个cnn(lenet-5)由[13]提出,用于读取手写数字。lenet-5开始使用由一个或多个卷积层后跟池化层组成的重复结构。这些重复结构后跟扁平化层(flatten layer),以将最后的输出张量(tensor)连接成一个长向量,再连接到几个密集连接层进行分类。lenet-5还推广了随着层的加深而减少fh和fw并增加fc的启发式方法(heuristic)。卷积-池化块用作特征提取层,全连接层通常具有递减的神经元数量、逐渐降低的维度、且最后一层用作分类器。
3、alexnet由alexander krizhevsky提出[12],并赢得了ilsvrc 2012[16],这对深度学习历史产生了深远的影响,因为它让计算机视觉界相信了深度学习的力量。alexnet的架构与lenet-5相似,但它是一个更大的网络,有8层神经网络和超过6200万个参数。k.simonyan和a.zisserman[18]将“原则性”超参数选择提升到了另一个水平,构建了vgg-16。随着层的加深,他们使用了越来越多的神经元,总共产生了16层和1.38亿个参数。相对合理的超参数选择使其对开发者很有吸引力。vgg-16在2014年赢得了ilsvrc。最先进cnn的发展有深度增加的趋势,但参数的数量并不一定增加。
4、在可以在特定数据集上训练神经网络之前,必须对神经网络的架构进行设计选择,例如网络中层的数量和维度。目前用于这一阶段神经网络开发的最先进的方法是试错法。设计者将选择架构,对架构进行测试,并根据自己关于性能提升的经验和直觉进行调整。可以遵循一些常规原则,例如当训练数据稀缺时使用小模型,而当训练数据丰富时使用大模型。然而,很少以一致且系统性的方式设计神经网络架构,例如基于确切数量的训练样本。
5、由于随机权重初始化、随机梯度估计和其他随机性来源引起的神经网络训练中固有的随机性使得模型开发特别有挑战性。可能不清楚性能的变化是由于为了改变架构而进行的干预(如添加层和改变超参数)还是由于训练中的随机性。通常,研究人员在得出干预有益或有害的结论之前,会在同一组超参数上对模型进行多次训练。当模型变得非常大时,这是不可取的,并且训练一次需要几天到几个月的时间。
6、考虑到这些限制,希望提供改进的技术来设计更加具备一致性且需要更少人工输入的神经网络架构。
技术实现思路
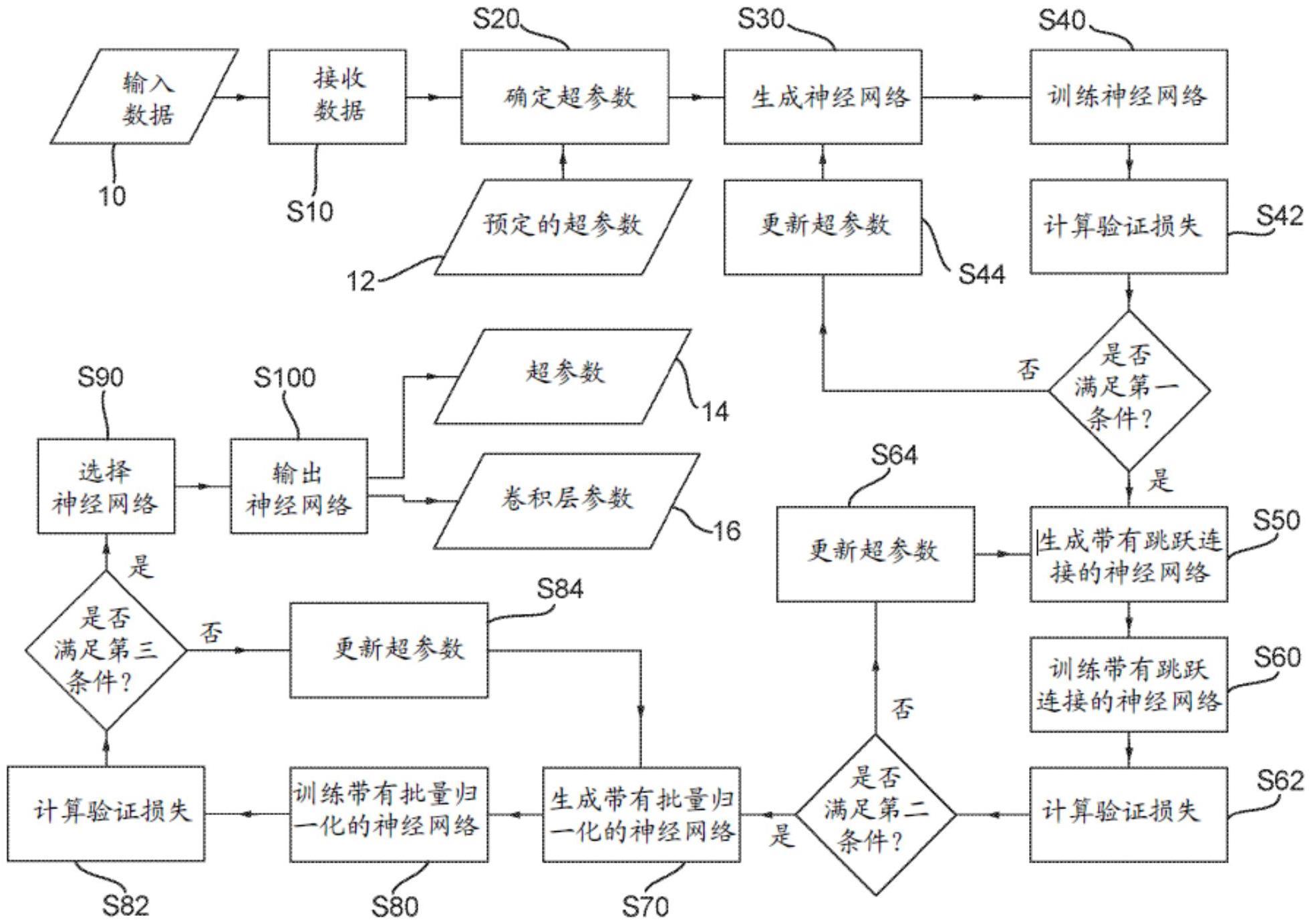
1、根据本发明的一个方面,提供了一种由计算机实现的用于生成神经网络的方法,包括:接收输入数据;基于所述输入数据的一个或多个属性确定多个超参数的值;基于所述超参数的值,生成包括多个层的神经网络;使用所述输入数据训练所述神经网络,并且至少如果不满足第一预定条件,则更新所述超参数中的一个或多个超参数的值;复所述生成一个神经网络并对其进行训练的步骤直到满足所述第一预定条件;选择经训练的神经网络中的一个;以及输出所述选择的神经网络。
2、通过基于输入数据的属性来选择神经网络的初始参数,并使用迭代方法来开发神经网络,该方法可以一致地适用于要使用神经网络的输入数据的生成架构。
3、在一些实施例中,所述多个层包括一个或多个池化层以及每个池化层之间的一个或多个卷积层,所述多个超参数包括池化层的数量以及每个池化层之间的卷积层的数量。
4、卷积神经网络(cnn)是权重共享机制的一个例子。cnn允许在输入数据的多个位置重复使用“特征检测器”。例如,在图像处理应用中,cnn应该能够检测图像中任意位置的眼睛。cnn还在同一层内共享权重,以减少参数的数量,从而有效地减少过拟合并降低计算量。
5、在一些实施例中,池化层是最大池化层。
6、最大池化层提供了一种降低维度的简单机制,从而降低了计算量。
7、在一些实施例中,其中所述输入数据是周期性时序数据,并且在所述确定多个超参数的值的步骤中,基于所述时序数据的每个周期内所述时序数据中的样本数量来确定所述池化层的数量。
8、通过将池化层的数量建立在周期性数据的时间尺度上,可以通过防止基于数据的周期性而不合适的跨更大时间尺度的拟合来最小化过拟合,跨更大时间尺度的拟合不适合基于数据的周期性。
9、在一些实施例中,所述池化层的数量根据以下来确定:
10、
11、其中,n最大池化是所述池化层的数量,p是量化每个池化层的维度降低的预定参数,τ是所述时序数据周期的预定估计值,以及fs是所述时序数据的采样频率。
12、这种特定形式的依赖关系基于周期性和每个池化层所选择的池化程度确保了池化层的数量适当。
13、在一些实施例中,所述输入数据是非周期性时序数据,并且在所述确定多个超参数的值的步骤中,基于所述时序数据中的样本数量来确定所述池化层的数量。
14、如果数据是非周期性的,则适合于在输入数据的整个长度上进行拟合。
15、在一些实施例中,所述池化层的数量根据以下来确定:
16、
17、其中,n最大池化是所述池化层的数量,p是量化每个池化层的维度降低的预定参数,以及d是所述时序数据的样本数量。
18、这种特定形式的依赖关系基于输入数据的长度和每个池化层所选择的池化程度确保了池化层的数量适当。
19、在一些实施例中,所述多个层还包括每个卷积层之后的激活层。
20、使用激活层可以标准化卷积层的输出,提供更加可预测的训练性能,并在训练过程中减少错误参数选项。
21、在一些实施例中,所述激活层包括线性整流函数(relu)或带泄漏线性整流函数(leaky relu)。
22、线性整流函数或带泄漏线性整流函数是众所周知的激活函数,其确保卷积层的输出将是(非严格)单调的,这样可以提高训练表现。
23、在一些实施例中,所述更新所述超参数中的一个或多个超参数的值包括增加每个池化层之间的卷积层的数量。
24、逐渐增加卷积层的数量允许神经网络深度增长到适合输入数据的适当水平。这降低了神经网络层过多(导致过拟合、训练时间增加和计算要求增加)或层过少(导致精度和性能降低)的可能性。
25、在一些实施例中,所述输入数据为经标注的输入数据,并且使用监督学习的方式来训练所述神经网络。
26、监督学习最适合于分类任务,例如生理数据的分类。
27、在一些实施例中,所述多个层包括一个或多个池化层和每个池化层之间的一个或多个卷积层,所述多个超参数包括池化层的数量和每个池化层之间的卷积层的数量;每个卷积层有相关联的多个参数,并且训练所述神经网络包括:基于所述超参数的值和所述卷积层的参数的先前值来选择所述卷积层的参数值;使用所述神经网络的输出来计算损失函数的训练值;以及重复所述选择参数值和计算损失函数的训练值的步骤,直到在两次或更多次连续计算所述损失函数的训练值的步骤内所述损失函数的训练值的变化低于预定阈值。
28、网络的迭代训练允许网络选择适合于输入数据的参数。
29、在一些实施例中,所述损失函数的训练值包括通过对应用于所述输入数据的所述神经网络的输出上的所述损失函数进行评估来计算的训练损失。
30、使用训练损失值允许监督学习迭代地提高其在输入数据上的性能。
31、在一些实施例中,当在神经网络在训练之后的损失函数的验证值不低于前一个神经网络在训练之后的损失函数的验证值时,满足所述第一预定条件。
32、使用验证损失值来评估架构的性能并选择何时改变神经网络的架构,提供了各网络之间的训练和性能评估独立性。
33、在一些实施例中,该方法还包括,在满足所述第一预定条件之后:基于所述超参数的值生成神经网络,所述神经网络在其非连续层之间包括一个或多个跳跃连接;使用所述输入数据训练所述包括一个或多个跳跃连接的神经网络,并且至少如果不满足第二预定条件,则更新所述超参数中的一个或多个超参数的值;以及重复所述生成包括一个或多个跳跃连接的神经网络并对其进行训练的步骤,直到满足所述第二预定条件。
34、添加跳跃连接有助于防止神经网络训练中的梯度消失问题,该问题会导致训练迭代之间的改进停滞。然而,跳跃连接可以使得神经网络在相对较浅的架构下收敛,这是因为跳跃连接通常会显著改善训练和验证损失。因此,一旦仅添加额外的卷积层没有获得进一步的改进,那么在架构开发的后期阶段仅添加跳跃连接是有利的。
35、在一些实施例中,当包括一个或多个跳跃连接的神经网络在训练之后的损失函数的验证值不低于前一个包括一个或多个跳跃连接的神经网络在训练之后的损失函数的验证值时,满足所述第二预定条件。
36、使用验证损失值来评估架构的性能提供了各网络之间的训练和性能评估的独立性。
37、在一些实施例中,该方法还包括,在满足所述第二预定条件之后:基于所述超参数的值生成包括一个或多个批量归一化层的神经网络;使用所述输入数据训练所述包括一个或多个批量归一化层的神经网络,并且至少如果不满足第三预定条件,则更新所述超参数中的一个或多个超参数的值;以及重复所述生成包括一个或多个批量归一化层的神经网络并对其进行训练的步骤,直到满足所述第三预定条件。
38、批量归一化提高了神经网络的稳定性,因此在深度神经网络中是可取的。类似于跳跃连接,在架构开发的后期阶段添加批量归一化也是有利的,因为这提高了架构开发早期阶段的稳定性。
39、在一些实施例中,所述多个层包括多个卷积层和每个卷积层之后的激活层,并且所述包括一个或多个批量归一化层的神经网络包括每个激活层之后的批量归一化层。
40、在每个激活层之后包括批量归一化层确保了每个卷积层的输入被归一化。
41、在一些实施例中,包括一个或多个批量归一化层的神经网络在训练之后的损失函数的验证值不低于前一个包括一个或多个批量归一化层的神经网络在训练之后的损失函数的验证值时,满足所述第三预定条件。
42、如上所述,使用验证损失值来评估架构的性能提供了各网络之间的训练和性能评估的独立性。
43、在一些实施例中,所述损失函数的验证值包括通过对应用于验证数据集的神经网络的输出上的损失函数进行评估来计算的验证损失。
44、使用单独的验证数据集来计算验证损失确保了神经网络可推广到用于训练神经网络的数据之外的数据。
45、在一些实施例中,所述输入数据包括时序数据。
46、通过这种方法生成的这类神经网络特别适合于时序数据的分析。
47、在一些实施例中,所述时序数据是周期性生理数据。
48、希望能够将机器学习技术应用于周期性生理数据,以帮助对患者数据进行分类并识别潜在的异常。
49、在一些实施例中,所述时序数据是心电图数据。
50、心电图(ecg)数据是生理数据的一个例子,可以通过使用本方法生成的神经网络对其进行分类。
51、在一些实施例中,所述选择经训练的神经网络中的一个包括选择具有最低的损失函数验证值的经训练的神经网络。
52、基于验证损失选择性能最佳的网络是提供该方法输出的一种简单方法,其最大限度地减少了用于提供输出的任何额外步骤,并最大限度地降低了计算量。
53、在一些实施例中,所述选择经训练的神经网络中的一个包括:多次训练具有最低的损失函数验证值的神经网络,以获得所述具有损失函数的最低验证值的神经网络的对应多个经训练实例;以及提供所述经训练实例的平均集合作为所述选择的神经网络。
54、输出最佳性能网络的训练实例的平均集合可以减少由于训练的随机性而引起的变化。这可以提供性能更好的神经网络的更一致的输出。
55、在一些实施例中,所述损失函数验证值包括通过对应用于验证数据集的经训练的神经网络的输出上的损失函数进行评估来计算的验证损失:。
56、如上所述,使用单独的验证数据集来计算验证损失确保了神经网络可推广到用于训练神经网络的数据之外的数据。
57、在一些实施例中,输出所述选择的神经网络包括输出在生成所述选择的神经网络时使用的所述超参数的值。
58、超参数定义了神经网络的架构,因此一个理想的输出是被确定为适合特定类别输入数据的架构。然后,超参数可以用于生成最佳架构的神经网络,用于在相同类型的其他数据集上进行训练。
59、在一些实施例中,所述多个层包括一个或多个卷积层,每个卷积层有相关联的多个参数,并且输出所述选择的神经网络包括输出所述卷积层的参数值。
60、根据要使用神经网络的应用,还可能希望输出完全训练的神经网络,包括参数的值。
61、在一些实施例中,所述神经网络还包括分类层。
62、分类层可以用于将输入数据分类到多个类别中的一个,例如,使得决策可以基于判定特定输入数据实例对应于某个类别。
63、在一些实施例中,所述时序数据是生理数据,并且所述分类层用于将所述输入数据分类到多个临床类别中的一个。
64、一个特别理想的应用是通过将输入分类为临床类别来帮助医务人员诊断临床数据。
65、根据本发明的另一方面,提供了一种对来自患者的生理数据进行分类的方法,该方法包括:接收生理数据;根据第一方面的实施例生成神经网络,其中所述时序数据是生理数据,该网络包括分类层;使用该神经网络对所述生理数据进行分类(例如,分类为多个临床类别中的一个)。
66、生成神经网络的方法确保了神经网络具有优化性能和准确性的架构。因此,当应用于对来自患者的生理数据的分类时,使用该方法生成的神经网络提供了性能和准确性上的改进。
67、根据本发明的另一方面,提供了一种将患者分类为临床类别的方法,该方法包括:接收生理数据;根据第一方面的实施例生成神经网络,其中所述时序数据是生理数据,所述分类层用于将输入数据分类到多个临床类别中的一个;使用所述神经网络对所述生理数据进行分类;以及基于来自所述神经网络的分类层对所述生理数据的分类,将所述患者分类为多个临床类别中的一个。
68、本发明还可以在计算机程序、计算机可读介质或设备中进行实施。
- 还没有人留言评论。精彩留言会获得点赞!