基于多目标深度强化学习的无人机边缘计算卸载方法
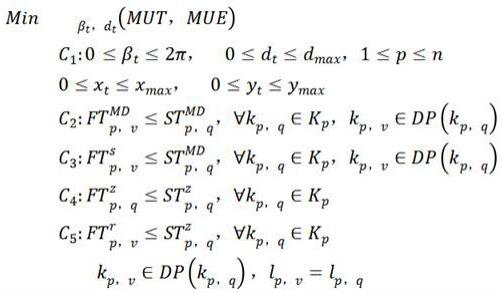
1.本发明属于无人机技术领域,涉及无人机边缘计算,尤其是一种基于多目标深度强化学习的无人机边缘计算卸载方法。
背景技术:
2.近年来,随着5g技术和物联网技术的发展,基于终端设备(terminal unit,tu)的计算密集型应用越来越多。但是,tu计算资源和电池容量有限,无法处理大量的计算密集型应用,而云端服务器距离tu较远,由其处理任务会造成较大的时延。多址边缘计算(multi-access edge computing,mec)被认为是缓解tu计算资源不足并减小任务处理时延的一个有效途径。mec服务器具有充足的计算资源,可以在距离tu更近的边缘处理计算密集型应用,从而减小tu的计算压力。用户可以选择将应用卸载到mec服务器执行或本地tu执行,此类问题被称为计算卸载问题(computation offloading problem,cop)。在本地执行虽会减少应用的时延,但是会导致较高的能耗,而卸载到mec执行时虽会减小tu能耗却会增加应用时延,因此解决mec中的cop受到了广泛的关注。此外,由于在复杂的环境下,如山区、战场和受灾区等,mec基站无法对此类区域进行信号覆盖。
3.因此,具有高机动性的无人机(unmanned aerial vehicle,uav)辅助多址边缘计算系统(uav-assisted multi-access edge computing,uav-mec)被应用于此类问题。其中uav搭载的边缘服务器可以扩大其通信覆盖范围,减小地域环境的约束,从而提高部署效率和用户服务质量。uav-mec具有灵活性高、覆盖范围广、响应更加迅速、成本低等优点。
4.针对uav-mec中计算卸载的研究,目前的方法主要包括基于传统的优化方法和基于机器学习的方法。传统的优化方法中主要利用凸优化、启发式算法和博弈论等方法来解决uav-mec的cop,上述方法在静态环境下可以取得较好的结果,但在动态环境下,特别是uav快速移动时,算法需要重新开始执行,这会导致计算资源的浪费和较高的时延,因此,传统的优化方法难以满足用户的需求。
5.基于机器学习的方法可以在uav-mec环境中动态地调整卸载策略以适应环境的快速变化。由于深度强化学习可以实时与环境进行交互,因此,目前基于机器学习的计算卸载大多采用深度强化学习(deep reinforcement learning,drl)方法。但是,现有的drls方法在解决多目标问题时,大都采用将多目标加权转换为单个目标以获得线性标量奖励的方式来进行处理。由于在不同的时间,用户对于不同目标具有不同的偏好,很难确定合适的权重,因此这些方法的效果很难满足用户需求。
技术实现要素:
6.本发明的目的在于克服现有技术的不足,提出一种基于多目标深度强化学习的无人机边缘计算卸载方法,解决现有uav-mec中计算卸载方法忽略用户对于不同目标的偏好变化问题,有效提高无人机边缘计算卸载性能。
7.本发明解决其技术问题是采取以下技术方案实现的:
一种基于多目标深度强化学习的无人机边缘计算卸载方法,包括以下步骤:步骤1、构建无人机-移动边缘计算系统,该无人机-移动边缘计算系统由f个终端设备和m架无人机组成,每个无人机搭载mec服务器在固定区域内进行任务卸载,使用表示第p个终端设备中的应用程序,p={1, 2,
ꢀ…
,f},f表示终端设备的个数,,其中表示为任务集,表示任务依赖约束,该无人机-移动边缘计算系统的最小化时延和能耗的任务卸载模型:其中mut 和mue 分别表示总时延和总能耗,表示任务在无人机执行完成并返回数据的完成时间,表示任务在本地执行时的完成时间,其中q={1, 2 ,
…
, n},n是要卸载的应用中相关的密集型任务的个数,表示任务的完成时间,如果在无人机上执行,则等于,否则等于;表示任务集中最后一个任务的完成时间;和分别表示任务在无人机执行和在本地执行的能耗,表示无人机的飞行能耗;步骤2、采用深度强化学习的方法对无人机-移动边缘计算系统的最小化时延和能耗的任务卸载模型进行求解,求解方法为:通过多目标马尔可夫决策过程对采用深度强化学习进行求解的每一个卸载任务构建任务卸载模型,所构建的任务卸载模型表示为(s,a,r,ψ,f),该任务卸载模型的目标是最大化向量值奖励r;其中s 表示状态空间;a表示动作空间;是向量值奖励,和分别表示时延的奖励值和能耗的奖励值;ψ是偏好空间,用于存储不同的偏好方案;是任务卸载策略下的标量化函数, 其中、是指当前偏好;步骤3、为了求得最小化时延和能耗, 需初始化用户偏好空间:采用nbi法生成均匀分布的n个权重向量,从而为时延和能耗两目标分配当前用户偏好空间;步骤4、对深度强化学习中的q网络和目标q网络进行初始化:所述q网络采用double dqn与dueling dqn相结合的方法,用来选择动作以及对步骤2建立的任务卸载模型进行训练优化;所述目标q网络用于计算目标q值,所述目标q网络的网络参数每隔一段时间从当前q网络复制过来;所述q网络和目标q网络的结构是完全相同的,均包括一个输入层、两个隐藏层以及一个输出层,其中第二个隐藏层通过dueling dqn的方法将网络结构分为value层和advantage层;步骤5、深度强化学习中的智能体与mec环境开始交互,一方面智能体从mec环境中获取当前状态,另一方面mec环境通过智能体选择的动作返回当前奖励向量值和下一个状态,智能体从mec环境中获得当前状态,并进行偏好经验池更新,所述偏好经验池更新的方
法为:从偏好空间ψ中选择当前偏好,并判断当前偏好是否在遇到的偏好经验池w中,如果不存在,则将当前偏好添加到偏好经验池w,否则利用当前迭代次数对偏好经验池w进行更新;步骤6、深度强化学习中的智能体通过q网络训练得到当前q值,从动作空间a中选择当前状态s下的动作a,并执行动作得到向量值奖励r和下一个状态s
´
,所述动作空间a包括如下两个动作:在终端设备执行任务和卸载到无人机-移动边缘计算系统上执行任务;步骤7、进行经验存储操作:将q网络输出的当前状态s、动作a、向量值奖励r以及下一个状态s
´
作为一条经验存入经验缓冲池φ;步骤8、进行经验样本训练:首先从经验缓冲池φ中随机选择一部分作为经验样本;然后从偏好经验池w中利用非支配排序的方法选择经验偏好,通过q网络和目标q网络同时进行训练,旨在最大化向量值奖励,得到最优的卸载决策;在训练过程中,设q网络的输入为当前状态s、经验偏好和当前偏好,输出q值,目标q网络的输入为下一个状态s
´
、经验偏好和当前偏好,输出目标q值,利用下式计算损失函数l:上式中,q和q
´
分别表示q网络和目标q网络得到的q值和目标q值,γ表示奖励折扣因子,s
´
是q网络输出的下一个状态,表示状态s
´
下,执行当前最优动作后的得到的最大q值;最后,利用损失函数值更新q网络,每隔300代将q网络参数同步给目标q网络:步骤9、判断q网络训练是否结束,从而选择是否输出卸载决策,具体方法为:判断当前迭代是否达到最大迭代次数,是则输出最优卸载决策,其中最优卸载决策是指智能体执行动作a后得到的向量值奖励最大,否则转到步骤5。
8.进一步,所述任务依赖约束包括:约束1:无人机只能在规定的矩形区域飞行,同时规定了t时隙水平方向范围和t时隙内飞行的最大距离;约束2:任务执行时,必须保证其前面的任务已经全部执行完成;一方面,如果任务在无人机执行时,必须确保处理任务的输出数据已经完全传输到终端设备;另一方面,如果任务在本地终端设备执行时,其前面的任务必须全部执行完成;约束3:在无人机执行任务时必须保证任务的输入数据已全部传输到无人机-移动边缘计算系统上,并保证其前面的任务全部执行完成。
9.进一步,所述步骤6的具体实现方法为:采用double dqn方法选择动作a,利用两个动作价值函数确定动作a:一个用于估计动作,另一个估计该动作的价值,表示如下:
其中s表示当前状态,a表示所执行的动作,表示用户当前偏好,表示当前状态s下选择q值最大的动作,rand是一个[0,1]的随机数,表示贪心概率,取值0.9;在当前状态s下执行动作a得到下一步的状态s
´
和向量值奖励r, 该向量值奖励r定义为:其中和分别表示第p个终端设备中应用程序的任务执行顺序中第q-1个和第q个任务,表示任务的完成时间,表示t时隙任务的能耗, 和分别表示时延的奖励值和能耗的奖励值;t个时隙内的奖励值函数和分别定义为:其中表示奖励折扣因子,取值为0.99。
[0010]
本发明的优点和积极效果是:1、本发明将无人机-移动边缘计算系统(uav-mec系统)的cop建模为一个多目标马尔可夫决策过程,并采用多目标深度强化学习方法进行求解,从而得到最优的计算卸载策略,进而优化系统性能,能够满足用户的不断变换的偏好,得到满足用户需求的最优解,提高了求解效率和灵活性,可广泛用于对无人机边缘计算环境进行计算卸载。
[0011]
2、本发明在uav-mec系统建模中加入了任务依赖约束,提高了计算资源的利用率。
[0012]
3、本发明采用多目标强化学习方法解决无人机边缘计算卸载问题,寻求uav-mec中cop的最优卸载策略,使时延和能耗最小化,从而满足用户需求,提高uav-mec系统的优化效率。
[0013]
4、本发明中将cop建模为多目标马尔可夫决策过程,与传统的马尔可夫决策过程不同,多目标马尔可夫决策过程中将奖励值拓展为向量值奖励,其中每一个元素对应一个目标,对多个目标进行同时优化,并动态调整权重以满足不同的用户偏好。
[0014]
5、本发明采用动态的权重调整策略,利用q网络对当前用户的偏好和之前的用户偏好同时进行训练优化,其中之前的用户偏好通过非支配排序的方法从偏好经验池中获取当前最好优的偏好,可以更好地维护先前学习的策略。
[0015]
6、本发明采用double dqn和dueling dqn相结合的网络结构,通过double dqn和dueling dqn调整q网络结构,提高算法效率。
附图说明
[0016]
图1为本发明的无人机边缘计算卸载方法流程图;
图2为本发明的无人机边缘计算卸载方法原理图;图3为本发明的网络结构图;图4为本发明的不同任务数下获得的自适应误差;图5a为本发明在任务数为20下获得的累积遗憾值;图5b为本发明在任务数为30下获得的累积遗憾值;图5c为本发明在任务数为40下获得的累积遗憾值;图5d为本发明在任务数为50下获得的累积遗憾值。
具体实施方式
[0017]
以下结合附图对本发明做进一步详述。
[0018]
一种基于多目标深度强化学习的无人机边缘计算卸载方法,如图1及图2所示,包括以下步骤:步骤1、构建无人机-移动边缘计算系统。
[0019]
为了实现基于多目标深度强化学习的无人机边缘计算卸载功能,本步骤构建一个基于uav辅助的mec系统,其中每个uav搭载mec服务器,在固定区域内进行任务卸载。将cop(计算卸载问题)建模为一个多目标优化问题并加入了任务依赖约束,旨在同时最小化uav-mec系统的时延和能耗。
[0020]
本步骤针对uav-mec环境中的多目标(时延和能耗)进行了建模,具体方法如下:本发明考虑了一个由f个tus和m架uav组成的无人机-移动边缘计算系统(uav-mec系统),其中f={1,2,
…
,f},m={1,2,...,m},无人机在规定区域内飞行,在每个uav上搭载计算资源丰富的mec服务器,从而收集tus中的计算密集型任务。tus可以通过无线链路将计算密集型任务卸载到uavs上执行。在每个tu中存在一个计算密集型应用,其中有n个相关的密集型任务。通过有向无环图(dag)对应用进行建模,表示为,其中表示为任务集,表示任务依赖约束。设和分别表示直接前驱集和直接后继集,其中p={1,2,
…
,f},q={1,2,
…
,n}。表示任务和之间的依赖约束,其中是任务的直接前驱,相应的是任务的直接后继,是指在任务必须在完成后执行。应用中的每个任务被表示为一个三元组,其中表示执行任务的cpu周期数,和分别表示任务的输入数据和输出数据规模。每个计算密集型任务即可以选择在tu上执行,也可以卸载到任意uav上执行。设表示第p个终端设备中所有任务的执行位置集,其中为任务的执行位置,如果,表示任务在上执行,否则卸载到第个uav执行。
[0021]
下面分别对无人机的飞行模型、本地终端设备模型和无人机边缘计算模型进行说
明。
[0022]
无人机的飞行模型:假设uav飞行在固定高度h,将整个任务收集过程分成t个时隙,其中t=f
×
n。设τ为时隙持续时长,t={1,2,...,t}为时隙集。设uav在t时隙的水平坐标为。uav在t+1时隙的水平坐标通过下面公式得到:其中表示uav在t时隙的水平方向,表示uav在t时隙的飞行距离,指的是uav在每个时隙的最大飞行距离。假设uav只能在边长为和的矩形区域内移动。在uav-mec系统中无人机匀速飞行,其速度v=dt/τ,其推进功耗p(v)定义为:其中和分别表示悬停时的叶型功率和叶尖速度下的叶型功率,和分别表示悬停时的诱导功率和平均诱导速度。因此,uav在t时间内的总能耗定义为:。
[0023]
本地终端设备模型:假设任务通过无线信道卸载到无人机时的结束时间表示为,在uav执行任务的结束时间为以及返回输出数据的结束时间为。当任务在终端设备执行时,其结束时间表示为,并设。如果任务卸载到,则。值得注意的是,任务必须在直接前置任务集内任务全部完成后才能执行,即在终端设备上执行的开始时间为:任务在本地上执行时的时延和能耗,分别定义为:其中,表示执行的cpu周期数,是指的计算能力,η是与芯片相关的常数。
[0024]
无人机边缘计算模型:设传输任务到无人机的时间为,定义为:
其中表示任务输入数据大小,表示t时隙上行链路的速率。其中定义为:其中和分别表示信道带宽和噪声功率,表示终端设备的发射功率,指的是t时隙和直接的信道增益。值得注意的是,由于环境的时变性,每个时隙的无限信道质量会发生变化,导致信道传输速率可能会变化。另外,假设上行链路和下行链路的传输速率相同,相应的,传输任务到的能耗为。当任务卸载到后,立即开始调用计算资源执行任务。设执行任务的开始时间,定义为:其中是的直接前驱任务。设任务的执行时间为,其中表示的计算能力。假设uav上的边缘服务器有充足的计算资源,因此忽略任务在uav执行时的能耗。当任务在uav执行完成后,需要将输出数据返回到tu。通过下行链路传输任务的时延为定义为:其中表示任务输出数据大小。相应的传输任务的能耗,表示终端设备的接收功率。当将任务卸载到的总时延和总能耗,分别定义为:根据上述三个部分的模型,得到无人机-移动边缘计算系统的最小化时延和能耗的任务卸载模型,分别定义为:
其中mut 和mue 分别表示总时延和总能耗,表示任务在无人机执行完成并返回数据的完成时间,表示任务在本地执行时的完成时间,其中q={1, 2 ,
…
, n},n是要卸载的应用中相关的密集型任务的个数,表示任务的完成时间,如果在无人机上执行,则等于,否则等于;表示任务集中最后一个任务的完成时间;和分别表示任务在无人机执行和在本地执行的能耗,表示无人机的飞行能耗。
[0025]
总能耗mue包括tu和uav执行任务时的能耗和uav飞行时的能耗。此外,在任务卸载过程中,我们还需遵循如下任务依赖约束:约束1:无人机只能在规定的矩形区域飞行,同时规定了t时隙水平方向范围和t时隙内飞行的最大距离;约束2:任务执行时,必须保证其前面的任务已经全部执行完成;一方面,如果任务在无人机执行时,必须确保处理任务的输出数据已经完全传输到终端设备;另一方面,如果任务在本地终端设备执行时,其前面的任务必须全部执行完成;约束3:在无人机执行任务时必须保证任务的输入数据已全部传输到无人机-移动边缘计算系统上,并保证其前面的任务全部执行完成。
[0026]
上述任务依赖约束可表示为:其中约束表示uav只能在边长为和的矩形区域飞行,同时规定了t时隙水平方向范围和t时隙内飞行的最大距离。约束和表示任务执行时,必须保证其直接前驱集已经全部执行完成。如果任务在uav执行时,必须确保处理任务的输出数据已经完全传输到tu。否则任务在本地tu执行时,其直接前驱集必须全部执行完成。约束和表示
在uav执行任务时必须保证其输入数据已全部传输完成以及其直接前驱任务全部执行完成。
[0027]
步骤2、采用深度强化学习的方法对无人机-移动边缘计算系统的最小化时延和能耗的任务卸载模型进行求解。
[0028]
本步骤的具体实现方法为:通过多目标马尔可夫决策过程对采用深度强化学习进行求解的每一个卸载任务构建任务卸载模型,所构建的任务卸载模型表示为(s,a,r,ψ,f),该任务卸载模型的目标是最大化向量值奖励r;其中s 表示状态空间;a表示动作空间;是向量值奖励,和分别表示时延的奖励值和能耗的奖励值;ψ是偏好空间,用于存储不同的偏好方案;是任务卸载策略下的标量化函数, 其中、是指当前偏好,mut和mue分别表示总时延和总能耗。
[0029]
在本发明中,cop被定义为一个多目标问题,因此r表示为一个向量值奖励,每一个元素代表一个目标。
[0030]
步骤3、为了求得最小化f,即最小化时延和能耗, 需初始化用户偏好空间,为时延和能耗两目标分配当前用户偏好(权重), 具体采用nbi(normal boundary intersection)法生成均匀分布的n个权重向量。
[0031]
步骤4、对深度强化学习中的q网络和目标q网络进行初始化,为训练过程奠定基础。q 网络部分采用了double deep q network(double dqn) 和dueling deep q network(dueling dqn)相结合的方法.q网络用来选择动作以及对步骤2建立的任务卸载模型进行训练优化,目标q网络用于计算目标q值,目标q网络的网络参数不需要迭代更新,而是每隔一段时间从当前q网络复制过来,即延时更新,这样可以减少目标q值和当前的q值相关性。此外,q网络和目标q网络的结构是完全相同的,均包括一个输入层、两个隐藏层以及一个输出层,其中为了提高收敛效率和训练速度,本发明采用dueling dqn的方法将第二个隐藏层的网络结构分为value层和advantage层。
[0032]
步骤5、深度强化学习中的智能体与mec环境开始交互(即训练过程开始),一方面智能体从环境中获取当前状态, 另一方面环境通过智能体选择的动作返回当前奖励向量值和下一个状态.智能体从环境中获得当前状态,并进行偏好经验池更新。其中偏好经验池的更新过程为:从偏好空间ψ中选择当前偏好,并判断当前偏好是否在遇到的偏好经验池w中,如果不存在,则将当前偏好添加到偏好经验池w,否则利用当前迭代次数对偏好经验池w进行更新。
[0033]
步骤6、首先智能体通过q网络训练得到当前q值,然后从动作空间a中选择当前状态下的动作,并执行动作得到向量值奖励和下一个状态,其中动作空间a中包括两个动作,即在终端设备执行任务和卸载到uav-mec上执行任务。
[0034]
本步骤的具体实现方法为:采用double dqn方法选择动作a,其中利用两个动作价值函数确定动作a:一个用于估计动作,另一个估计该动作的价值,表示如下:其中s表示当前状态,a表示所执行的动作,表示用户当前偏好,
表示当前状态s下选择q值最大的动作,rand是一个[0,1]的随机数,表示贪心概率,取值0.9;在当前状态s下执行动作a得到下一步的状态s
´
和向量值奖励r, 该向量值奖励r定义为:其中和分别表示第p个终端设备中应用程序的任务执行顺序中第q-1个和第q个任务,表示任务的完成时间,表示t时隙任务的能耗, 和分别表示时延的奖励值和能耗的奖励值。本发明旨在最小化时延和能耗,但为了保证奖励值最大, 取时延和能耗的相反数。t个时隙内的奖励值函数和分别定义:其中表示奖励折扣因子,取值为0.99。因此,最大化,就相当于最小化总时延和总能耗。
[0035]
步骤7、经验存储操作:在智能体执行动作后,进行经验存储操作,将q网络输出的当前状态s、动作a、向量值奖励r以及下一个状态s
´
作为一条经验存入经验缓冲池φ。
[0036]
步骤8、为了提高训练效率,进行经验样本训练:从经验缓冲池φ中随机选择一部分作为经验样本,然后从偏好经验池w中利用非支配排序的方法选择经验偏好,通过q网络和目标q网络同时进行训练,旨在最大化向量值奖励,得到最优的卸载决策。其中q网络的输入为当前状态s、经验偏好和当前偏好,输出q值,目标q网络的输入为下一个状态s
´
、经验偏好和当前偏好,输出目标q值,利用q网络和目标q网络得到的q值和目标q值计算损失函数l,表示为:其中,q和q
´
分别表示q网络和目标q网络得到的q值和目标q值,γ表示奖励折扣因子,s
´
是q网络输出的下一个状态,表示状态s
´
下,执行当前最优动作后的得到的最大q值;最后,利用损失函数值更新q网络,每隔300代将q网络参数同步给目标q网络。
[0037]
步骤9、判断训练是否结束,从而选择是否输出卸载决策。判断当前迭代是否达到
最大迭代次数,是则输出最优卸载决策,其中最优卸载决策是指智能体执行动作a(本地设备执行或卸载到uav-mec执行)后得到的向量值奖励最大,否则转到步骤5。
[0038]
下面通过仿真实验对本发明的效果进行验证:1、实验条件:在cpu为amd r7 5800h、内存16g、windows 10的系统上使用python tensorflow 2.2进行仿真。
[0039]
2、实验内容及结果:实验结果主要比较不同任务数下算法的自适应误差以及累积遗憾值。表1列出了四种实例下的任务数。
[0040]
图4显示出四个不同实例下算法的自适应误差,自适应误差越小说明算法性能越好。从图中可以看出四种实例下,本发明都取得了最小值,说明本发明能够快速的调整目标权重以应对用户的偏好变化,从而满足用户需求。
[0041]
图5a、图5b、图5c和图5d分别显示出四种不同实例下本发明的累积遗憾值,其中最大迭代次数为2000,并与现有的技术对比分析。可以看出,在四种实例下,本发明的累积遗憾值都小于现有的技术,说明本发明取得了更好的性能。
[0042]
此外,本发明还实现了时延和能耗的最小化,实现了最大化效用,如表2和表3所示。示。
[0043]
表2和表3分别显示了四种不同实例下系统平均时延和系统平均能耗,从并与现有的技术进行了对比,可以看出本发明都取得了最优值。
[0044]
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1