一种针对恶意流量检测的开集识别装置及方法
本发明涉及恶意流量检测,提供了一种针对恶意流量检测的开集识别检测装置及方法。
背景技术:
1、随着物联网技术的兴起与发展,越来越多的设备实现了网络接入,然而大多数物联网设备都采取弱安全防护措施,存在较大的安全隐患。网络流量是网络空间中信息交互和传递的主要载体,相关研究指出,网络设备数量将在2025年达到754.8亿,2022年以后,巨量的网络设备每年将产生4.8zb的流量。因此,基于网络流量的异常检测技术在恶意流量检测领域作为一项有效的主动防御技术,它通过对网络流量模式进行识别,及时发现网络流量中异常的流量模式和攻击行为,对于维护网络空间的安全具有重要意义。
2、然而,目前恶意流量检测系统的研究中,模型往往是在闭集的假设条件下进行的,很难适应现实的情况。在训练模型的过程中,没有为未知类别预留空间,模型会把出现的未知类错误地分为已知类的一种,从而导致已知类的分类准确性下降,同时模型也缺乏应对新类的能力,对出现的新型攻击类别造成遗漏。
3、如何在开集环境下仍具有较高的识别性能,研究人员提出了一些方法。
4、在文献《towards open set deep networks》中提出了openmax模型,用softmax层通过最小化交叉熵损失来训练网络,然后计算训练样本的特征到其对应类的平均特征向量的距离,并用于拟合每个已知类单独的威布尔分布,根据韦布尔分布拟合分数对特征向量进行重新分布,最后再利用softmax计算已知类和未知类的概率。
5、文献《generative openmax for multi-class open set classification》中采用条件生成网络来生成未知类的样本,并与openmax结合,提出了g-openmax算法,可以对生成的未知类样本进行概率估计。
6、文献《open-category classification by adversarial sample generation》提出了对抗样本生成框架(adver-sarial sample generation framework),可以用它生成与已知类样本相近的未知类样本,必要时也可以生成已知类样本来扩充已知类数据集。
7、但是上述方法都使用了多个模型来实现开集识别和已知类分类,这大大增加了性能消耗。
技术实现思路
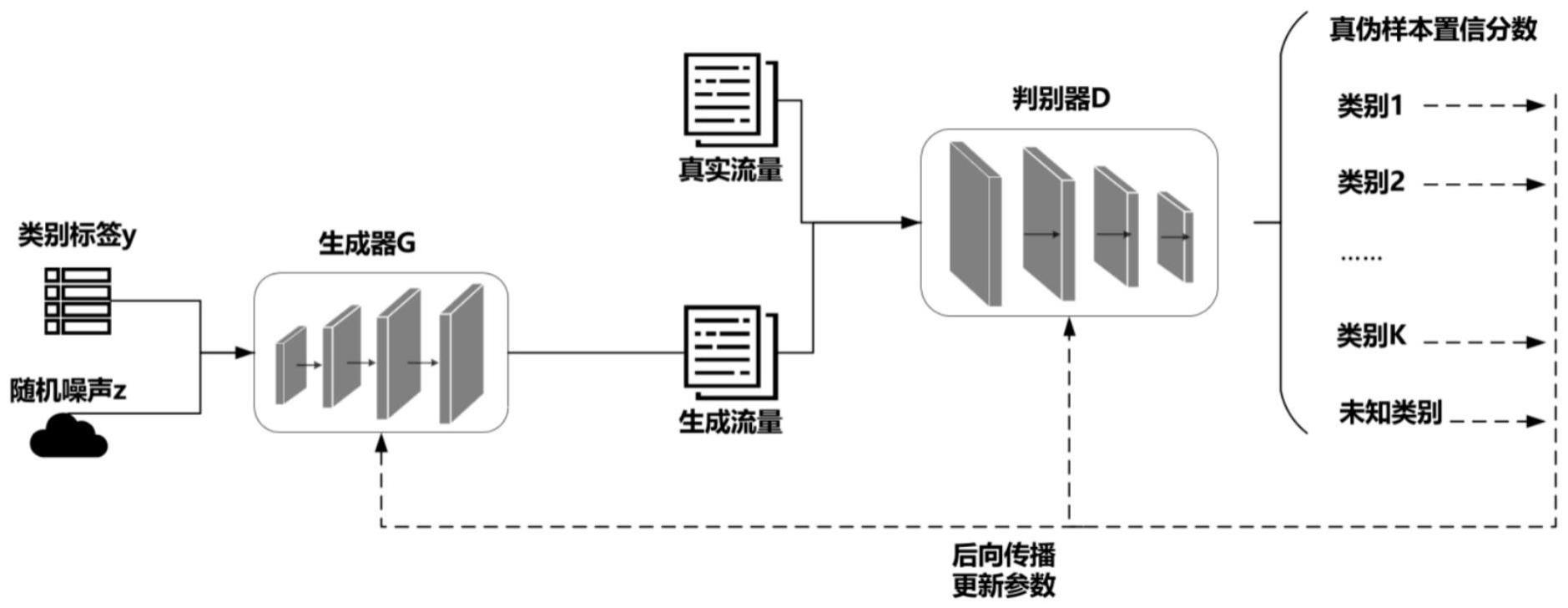
1、针对上述现有技术问题,本发明的目的在于提供一种针对恶意流量检测的开集识别检测装置,该系统能够解决在开集条件下,训练的模型难以检测未知类攻击造成性能下降的问题。初始化生成器结构,使其具备两个输入:随机噪声和随机标签,将噪声和类别标签拼接起来作为生成器的输入,使生成器生成指定类别的生成数据;初始化判别器结构,并为判别器最后一层添加一个k+1维度的分类分支,用于输出未知类判别与已知类分类的结果,其中k表示训练集中的攻击类别个数;基于判别器分数,使生成数据的判别分数更加接近于0,使真实数据的判别分数更加接近于1;对于生成器,使其生成的数据判别分数更加接近于1,即生成的数据接近于真实数据的样本分布;将生成器生成的数据作为开集数据的扩充,依据损失函数,使分类层能够对未知数据进行识别,也能对已知攻击进行分类。
2、为了达到上述目的,本发明采用如下技术方案:
3、本发明提供了一种针对恶意流量的开集识别检测装置,包括以下模块:
4、带标签的生成器模块:包括生成器与判别器,将随机生成的噪声和随机生成的类别标签拼接起来作为生成器的输入,从而使生成器能够生成指定类别的生成数据,将生成数据输入判别器,得到判别分数,判别分数表示判别器对真实数据和生成数据的评价,使生成数据的判别分数和真实数据的判别分数接近,从而优化生成器生成的生成数据,使得生成数据接近真实数据样本的分布;
5、具有辅助分类器的判别器模块:在判别器的最后一层添加一个k+1维度的分类分支,使判别器具有两个输出层:判别分数层和分类层,判别分数层对输入的数据产生真伪判别分数,分类层对多类别数据进行分类,输出未知类判别与已知类分类结果,其中k表示训练集中的攻击类别个数;
6、生成对抗和开集识别模块:根据判别器模块的判别分数层输出的判别分数,对生成器生成的生成数据和真实数据进行判别,使生成器和判别器模块相互对抗,共同训练,将生成器生成的伪数据,即生成数据作为开集数据的扩充,使分类层能够对未知数据进行识别分类,也能够对已知攻击进行分类,得到开集识别监测模型。
7、上述技术方案中,其中带标签的生成器模块具体实现步骤如下:
8、s1:初始化生成器的模型结构,生成器具备两个输入:随机噪声和随机标签,使其可以生成各种类别的生成数据,在训练开始前,通过高斯分布初始化生成器的模型参数;
9、s2:将随机生成的噪声和类别标签拼接起来,共同输入生成器中,使生成器生成指定类别的生成数据,依据判别器的判别分数,优化生成器生成的生成数据,使生成数据判别分数接近1,即接近真实数据样本的分布,最后将生成的数据与真实的样本数据一起输入判别器模块中。
10、上述技术方案中,其中具有辅助分类器的判别器模块具体实现步骤如下:
11、s1:定义判别器的模型结构,判别器具有一个输入,两个输出,生成数据和真实数据输入判别器中,判别器的最后一层增加一个k+1维度的分类分支,其中k表示训练集中的攻击类别个数,使其具有两个输出层:判别分数层和分类层;
12、s2:初始化判别器的判别分数层,使其对生成器生成的生成数据判别分数接近0,对真实数据样本的判别分数接近1;
13、s3:初始化判别器的分类层,使其将生成器生成的生成数据分类为第k+1类,实现对未知类的判别和已知类的分类。
14、上述技术方案中,其中生成对抗和开集识别模块具体实现步骤如下:
15、s1:基于判别器模块的判别器分数,使生成器和判别器模块相互对抗,共同训练,具体的为:
16、对判别器进行训练,使其对生成数据的判别分数接近于0,使真实数据的判别分数尽可能接近1,
17、对生成器进行训练,使生成器生成的生成数据判别分数接近1,即接近于真实数据分布,从而使生成器学习到真实数据的分布且判别器模块具备判断真伪样本的能力;
18、s2:生成器生成的生成数据接近于真实样本的数据分布,其特征空间接近于真实样本却区别于真实样本,则视为对开集数据的扩充,调整损失函数,使分类层对开集数据的预测为k+1,对闭集数据的预测为k类,从而使分类层能够对未知数据进行识别,也能够对已知攻击进行分类。
19、本发明还提供了一种针对恶意流量的开集识别检测方法,包括以下步骤:
20、s1:初始化生成器结构,使其具备两个输入:随机噪声和随机类别标签,将噪声和类别标签拼接起来作为生成器的输入,使生成器生成指定类别的生成数据;
21、s2:初始化判别器结构,并为判别器最后一层添加一个k+1维度的分类分支,得到判别器模块,用于输出未知类判别与已知类分类的结果,其中k表示训练集中的攻击类别个数;
22、s3:对判别器模块进行训练,使得对于生成数据,判别器的判别分数接近于0,对于真实数据,判别器模块判别分数接近1;
23、对生成器进行训练,使其生成的数据判别分数更加接近于1,即生成的数据接近于真实数据的样本分布;将生成器生成的数据作为开集数据的扩充,依据损失函数,使分类层能够对未知数据进行识别,也能对已知攻击进行分类。
24、上述方法中,步骤1具体包括以下步骤:
25、s1.1:初始化生成器模型结构,生成器具备两个输入:随机噪声和随机标签,使其可以生成各种类别的生成数据,在训练开始前,通过高斯分布初始化模型参数;
26、s1.2:将随机生成的噪声和类别标签拼接起来,共同输入生成器中,使生成器生成指定类别的生成数据,依据判别器分数,优化生成器生成的数据,使生成的数据判别分数接近1,即接近真实数据样本的分布,最后将生成的数据与真实的样本数据一起输入判别器模块中。
27、上述方法中,步骤2具体包括以下步骤:
28、s2.1:定义判别器模块结构,为判别器最后一层增加一个k+1维度的分类分支,其中k表示训练集中的攻击类别个数,使其具有两个输出层:判别分数层和分类层;
29、s2.2:初始化判别器模块的判别分数层,使其对生成器生成的伪数据,即生成数据判别分数接近0,对真实数据样本的判别分数接近1;
30、s2.3:初始化判别器模块的分类层,使其将生成器生成的数据分类为第k+1类,从而实现对未知类的判别和已知类的分类。
31、上述方法中,步骤3具体包括以下步骤:
32、s3.1:基于判别器模块的判别分数,使生成器和判别器模块相互对抗,共同训练,具体的为:
33、对判别器进行训练,使其对生成数据的判别分数接近于0,使真实数据的判别分数尽可能接近1,
34、对生成器进行训练,使生成器生成的生成数据判别分数接近1,即接近于真实数据分布,从而使生成器学习到真实数据的分布且判别器模块具备判断真伪样本的能力;
35、s3.2:生成器生成的数据接近于真实样本的数据分布,其特征空间接近于真实样本却区别于真实样本,则视为对开集数据的扩充,调整损失函数,使分类层对开集数据的预测为k+1,对闭集数据的预测为k类,从而使分类层能够对未知数据进行识别,也能够对已知攻击进行分类。
36、本发明同现有技术相比,其有益效果表现在:
37、一、目前常用的生成器模型在生成数据时,往往会产生相似于多种类别数据分布的生成数据,这会导致生成的数据与真实数据出入较大。该发明通过改进生成器结构,将随机噪声与随机标签的拼接作为输入,有效地提高了生成数据的真实性;普通的生成器只有一个输入:随机噪声。但是实际数据具有多种类别,不同类别的数据分布是不同的。这样的生成器和判别器对抗产生的数据,其分布可能既像这一类,又像那一类。将随机噪声和随机标签拼接输入生成器中,判别器同时还具备分类层。在生成对抗过程中,不仅仅是基于判别分数,还基于分类器预测的结果要尽可能接近随机标签的值,这样经过对抗训练后,生成的数据是像随机标签那一类的数据。
38、二、该发明利用生成对抗模型,生成的数据既可以模拟未知类别的样本分布,也可以扩充已知类的特征空间,有助于模型更好地学习样本分布;
39、三、该发明通过改进判别器网络,在最后一层增加分支,使判别器同时具备判别分数层与分类层,通过分类层实现对未知类的拒判和已知类的分类,通过判别分数层实现生成对抗,大大减少了性能消耗。
- 还没有人留言评论。精彩留言会获得点赞!