基于空间注意力引导可变卷积的跨域高光谱图像分类方法与流程
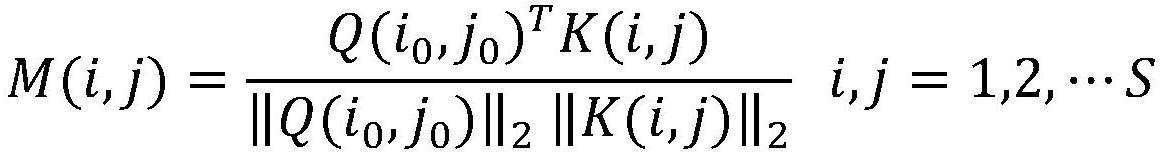
本发明涉及高光谱图像分类,特别是涉及一种基于空间注意力引导可变卷积的跨域高光谱图像分类方法。
背景技术:
1、遥感技术是通过获取各类电磁波的反射和折射并对其处理的一门综合技术。高光谱遥感技术有效地结合了二维成像技术与光谱技术,其具有纳米级的光谱分辨率,能够获得地表物体在0.4-2.5um(即可见光、近红外、短波红外、中红外等)电磁波谱段上几十个至几百个连续谱段的信息。与rgb图像和多光谱图像相比,高光谱遥感技术所得到的高光谱图像不再是一个二维图像,而是同时包含了光谱信息和地表物体空间信息的三维图像,如图1所示,图中展示了两个像素点的光谱曲线,并标注出了red,green,blue三个波段的位置。0.4-2.5um的光谱范围和较高的光谱分辨率使得高光谱图像能够提供地面物体更多的光谱特性,具有全色图像、rgb图像和多光谱图像无法比拟的优势,这也会使得地物光谱的全局特征将更加完整,局部细微特征将更加明显。
2、高光谱图像分类就是赋予图像中每一个像素点一个特定类别,属于像素级分类任务,是高光谱图像用于后续实际应用任务的基础。因此,高光谱遥感图像处理技术被广泛应用于精准农业、智慧农业、矿物勘测、环境保护、森林树种监测、国防军事战略等多个领域,具有重要的研究意义。
3、早期高光谱图像分类任务大多通过目视解译方法实现,并且为了准确性还需要进行实地考察,这一过程往往需要耗费大量的人力物力和财力,且非常耗时。如今,随着机器学习和深度学习的兴起,高光谱图像分类算法也可以分为基于机器学习的算法和基于深度学习的算法。传统的基于机器学习的算法大多以统计学习为理论基础,希望利用数学模型找到高光谱图像数据之间的联系,但是基于机器学习的算法只能提取高光谱数据的浅层特征,无法提取到深层特征,使得分类效果不佳。而基于深度学习的算法可以借助较深的特征提取网络,提取到高光谱数据的深层特征,对各类别的光谱曲线的表征能力和拟合能力更强。因此,基于深度学习的高光谱图像分类算法逐渐成为研究主流。
4、深度学习在各个领域虽然都已经取得了非常好的应用效果,但现阶段的深度学习算法大部分严重依赖大量的训练样本才能取得理想的性能,而获得标记样本是耗时耗力的。现实中,新获取的数据往往是没有标记样本的,研究如何在无标记样本下完成对高光谱图像的分类任务具有研究意义和现实意义。
5、此外,基于深度学习的算法还要求训练数据和测试数据是同分布的,同时不同场景的高光谱图像具有明显的光谱偏移和分布差异,这意味着在现有数据集上训练好的模型直接迁移到其他场景的高光谱图像上,无法获得较高的分类精度。为了减少两个数据集之间的分布差异,域自适应技术被提出来,并应用到了跨场景高光谱图像分类任务中。域自适应是迁移学习的一种,具体是指源域(sd)有标签,目标域(td)无标签,源域和目标域具有不同的数据分布,相同的分类任务。在高光谱图像分类领域,域自适应算法可以分为基于分类器对齐的和基于特征对齐的两大类。
6、另一方面,由图1可知,高光谱图像的空间分辨率相对较低,同时物体边缘和纹理信息复杂,地面物体的形状不规则。普通的卷积神经网络使用的是固定形状的卷积核,该卷积核的采样点是固定的,会无差别的引入中心像素的邻域像素点的信息。在这种情况下,固定形状的卷积核会不可避免的引入不同类别的光谱特征,进而使得卷积神经网络不能准确地提取地面物体的空谱特征。正如之前介绍的,高光谱图像包含丰富的空间纹理信息,但如果不区分有用信息和干扰信息,就会导致每个类别的深层特征不准确,这自然会影响后续域自适应中的特征对齐。然而,到目前为止,在跨域高光谱图像分类领域还没有提出解决这一问题的方案。
技术实现思路
1、本发明的目的是提供一种基于空间注意力引导可变卷积的跨域高光谱图像分类方法,能够更准确、更纯粹地提取源域和目标域的各个类别的空间光谱特征,进而可以实现目标域高光谱图像的精确分类。
2、为实现上述目的,本发明提供了一种基于空间注意力引导可变卷积的跨域高光谱图像分类方法,包括以下步骤:
3、步骤1,结合可变形卷积d-conv和空间注意力得到空间注意力引导可变卷积sad-conv,具体方法如下:
4、1)空间注意力
5、在空间注意力的分支中,假设输入特征图为x,通过三个1×1-conv参数更新后分别输出得到第一个特征图q、第二个特征图k和第三个特征图v,三个1×1-conv共享参数,所以q=k=v,并且q表示为:
6、q=σ(bn(w·x+b))
7、其中,bn(·)和σ(·)表示特征归一化和激活函数,w,b分别表示1×1-conv的权重和偏置;
8、为了表示x中每个像素与其中心像素的相似性,空间注意力矩阵m显示为:
9、
10、其中,q(i0,j0)是q的中心像素的特征,k是第二个特征图,||·||2表示2-norm算子,s是输入特征图的大小;
11、因此,空间注意力分支的输出ysa,可设为
12、ysa=vm
13、其中,v是第三个特征图;
14、2)可变形卷积d-conv
15、在可变形卷积d-conv的分支中,通过偏移量改变卷积核的采样位置的过程实现了d-conv,其主要思想可以表述如下:
16、
17、其中,p0是输出特征的像素,w1(pn)是卷积权值,pn列举了x中的位置,可以设置为pn∈r={(-1,-1),(-1,0),…,(0,1),(1,1)},poffset表示x中的偏移位置,此公式是为了将相似度低的采样位置与相似度高的采样位置相抵消,其中m为从空间注意力矩阵得到的偏移量,sort(m)表示将m从小到大排序,分别表示列表中第一个ε%和最后一个ε%的位置,ε是可手动设置的常数;
18、3)空间注意力引导可变卷积sad-conv的输出
19、最后,sad-conv的输出被表示为
20、
21、其中,θ是为了控制两个分支的权重而引入的自适应参数,它是一个可训练的参数;
22、步骤2,利用步骤1得到的sad-conv组成空间注意力引导可变卷积特征提取网络sad-convnet,sad-convnet网络可以表示为sad-convnet包括三个block-a、一个block-b和一个全连接层fully connected,block-a包括空间注意力引导可变卷积sad-conv、普通的卷积层conv、归一化层bn和激活函数层relu,block-b包括普通的卷积层conv、归一化层bn和激活函数层relu、普通的卷积层conv、归一化层bn和激活函数层relu、最大池化层maxpool、普通的卷积层conv、归一化层bn和激活函数层relu、平均池化层avgpool2d;
23、步骤3,对步骤二得到的sad-convnet进行迁移学习训练:利用深度学习框架设计网络,在源域和目标域的每个类别中随机选择180个样本参与训练,并将实验重复十次得到最终实验结果,整体分类精度(oa)、平均分类精度(aa)和kappa系数作为衡量实验结果的指标,三个值越高表明分类结果越好,具体训练方法为:
24、1)通过交叉熵损失和源域聚类损失进行监督训练sad-convnet网络,使得源域网络能够在源域数据集上获得较高的分类精度,具体为:
25、交叉熵损失表示为:
26、
27、其中c是类别数,表示源域中第i个训练样本,是的标签;
28、源域聚类损失表示为:
29、
30、其中ddis表示欧氏距离,λ(a,b)表示如果a等于b,输出为1,否则输出为0;
31、2)将1)中得到的源域网络的网络参数加载到目标域网络上,通过多层级的特征对齐损失训练sad-convnet网络,多层级的特征对齐损失由三部分组成,可以分别表示为:
32、
33、其中,φ()是希尔伯特空间中的内核,c是类别数,ns,nt是源域和目标域的样本个数,是已经训练好的源域网络,是目标域网络的特征输出;
34、
35、其中,dcos(a,b)表示a,b的余弦相似度,es(c)表示为
36、
37、ns,nt是源域和目标域的样本个数,c是类别数;
38、
39、其中,et(c)表示为
40、
41、c是类别数。
42、优选的,在第一个block-a的末端加入最大池化层maxpool。
43、优选的,在block-b的末端加入dropout以减小过拟合。
44、优选的,sad-convnet输入的数据块patch大小为21*21,循环次数epoch设置为20次,运行sad-convnet的主要硬件参数是:cpu:xeon silver 4210r,gpu:gtx-3090,和ram内存:49g。
45、优选的,sad-convnet使用pytorch深度学习框架设计网络,初始学习率设置为0.005,使用的优化器为随机梯度下降(sgd)。
46、因此,本发明采用上述结构的基于空间注意力引导可变卷积的跨域高光谱图像分类方法,能够更准确、更纯粹地提取源域和目标域的各个类别的空间光谱特征,进而可以实现目标域高光谱图像的精确分类。
47、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!