一种基于深度嵌入式聚类神经网络的声速剖面聚类方法
本发明属于海洋声速剖面聚类,尤其涉及一种基于深度嵌入式聚类神经网络的声速剖面聚类方法。
背景技术:
1、海洋声速剖面结构对水声传播具有重要影响,通过聚类能够将结构特征类似的海洋声速剖面划分为同一类,参照不同类型的声速剖面,可以有效划分不同海区,从而能够快速准确地确定特定海域的水下声学特性。传统的聚类方法主要通过pca、eof等手段对声速剖面数据进行特征提取,自开始利用机器学习、som神经网络等手段进行聚类以来,海洋声速剖面的聚类方法更为有效,机器学习方法的应用使得聚类更加便捷、可操作更高。但其中特征提取步骤与聚类步骤通常是分离的,聚类的效果不一定理想。
技术实现思路
1、本发明创造的目的在于,提供一种基于深度嵌入式聚类神经网络的声速剖面聚类方法。该方法基于高分辨率海洋再分析产品中获得的高分辨率、长时间序列声速剖面数据,实现了ae自编码器(auto-encoder)中的编码器(encoder)特征提取网络与最小化kl散度(kullback-leibler divergence)的软聚类(soft clustering)层相嵌套的深度嵌入式聚类神经网络,训练ae自编码器中的编码器特征提取网络提取声速剖面数据的降维特征,然后输入软聚类层进行聚类,利用kl散度计算聚类结果的损失,并将损失反馈给编码器特征提取网络及软聚类层进行联合优化,为实现对不同海域声速剖面的聚类提供了更有效的方法。
2、为实现上述目的,本发明创造采用如下技术方案:
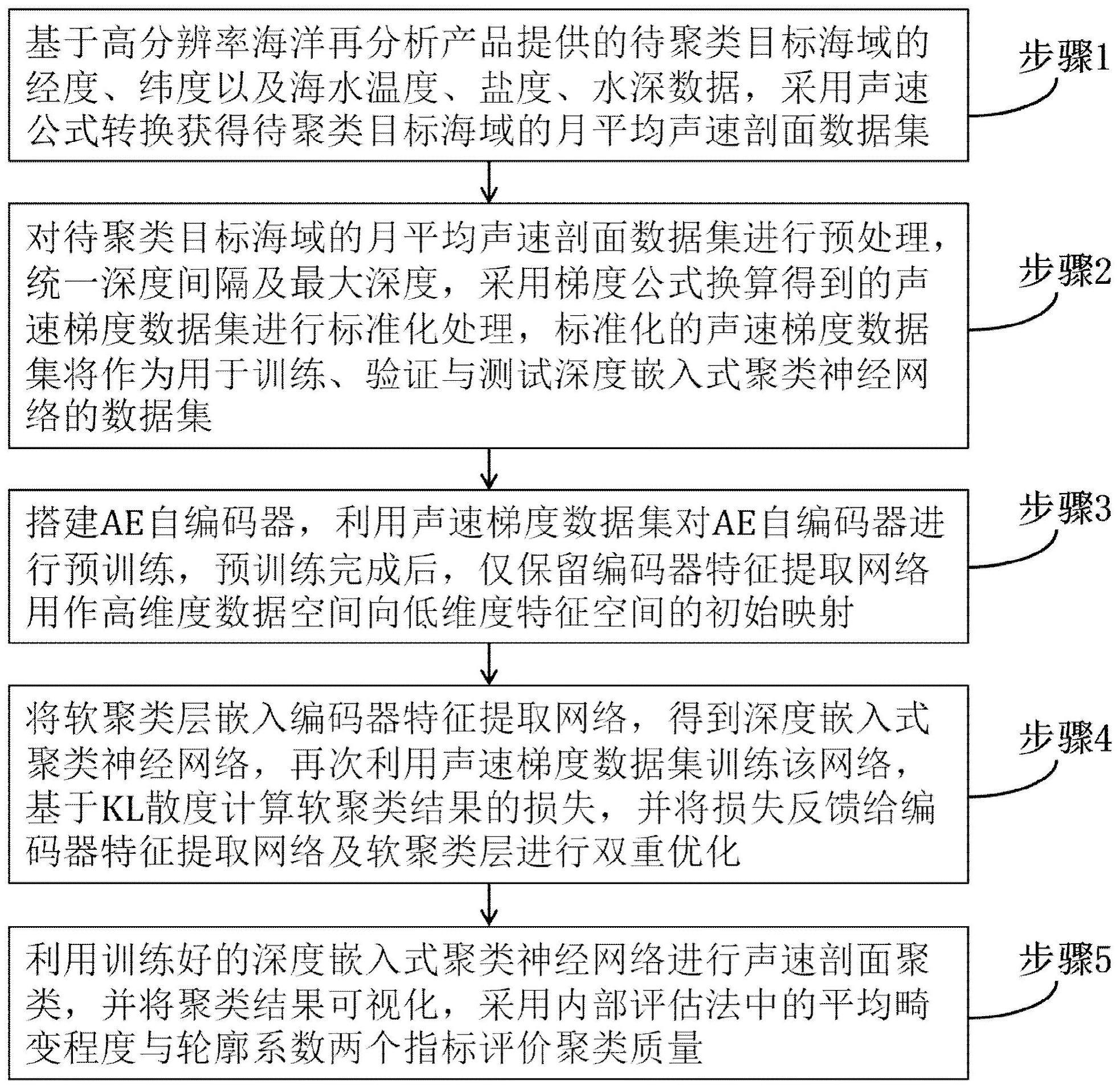
3、一种基于深度嵌入式聚类神经网络的声速剖面聚类方法,包括如下步骤:
4、步骤1,基于高分辨率海洋再分析产品提供的待聚类目标海域的经度、纬度以及海水的温度、盐度、水深数据,采用声速公式转换获得待聚类目标海域的月平均声速剖面数据集;
5、步骤2,对待聚类目标海域的月平均声速剖面数据集进行预处理,统一深度间隔及最大深度,采用梯度公式换算得到的声速梯度数据集进行标准化处理,标准化的声速梯度数据集将作为用于训练、验证与测试深度嵌入式聚类神经网络的数据集;
6、步骤3,搭建ae自编码器,利用声速梯度数据集对ae自编码器进行预训练,预训练完成后,仅保留编码器特征提取网络用作高维度数据空间向低维度特征空间的初始映射;
7、步骤4,将软聚类层嵌入编码器特征提取网络,得到深度嵌入式聚类神经网络,再次利用声速梯度数据集训练该网络,基于kl散度计算软聚类结果的损失,并将损失反馈给编码器特征提取网络及软聚类层进行双重优化;
8、步骤5,利用训练好的深度嵌入式聚类神经网络进行声速剖面聚类,并将聚类结果可视化,采用内部评估法中的平均畸变程度与轮廓系数两个指标评价聚类质量。
9、步骤1的具体步骤如下:
10、步骤1.1,参照高分辨率海洋再分析产品的网格单元结构,设计待聚类目标海域的海水温度、盐度、压力等物理量的数据结构;在水平范围内的经度、纬度采用等间距网格划分,在深度上采用非等间距划分;在时间维度上为等时间间隔输出;海水温度、盐度、压力等数据为海洋水体的物理量,在陆地和海底沉积层处的为缺省值状态;
11、步骤1.2,采用声速公式,将高分辨率海洋再分析产品的海水温度、盐度、压力数据换算为高分辨率声速剖面数据集,所述的声速公式表达式如下:
12、c(s,t,p)=cω(t,p)+a(t,p)s+b(t,p)s3/2+d(t,p)s2;
13、式中:c为海水声速值,s、t、p分别为海水盐度、水温、静压力,cω、a、b、d为与海水温度和静压力相关的经验函数,0≤s≤40、0°≤t≤40°、0pa≤p≤108pa;
14、步骤1.3,参照高分辨率海洋再分析产品的数据存储结构,将上述换算得到的声速剖面数据集按照相同的结构进行存储;声速剖面数据集的存储结构的水平空间分辨率、垂向空间分辨、时间分辨率、时间跨度与参照的高分辨率海洋再分析产品一致;
15、因为声速剖面的主要受到温度的影响,温度跃层与声速剖面有类似的形态结构,而温度跃层的时间演变主要体现在季节尺度上,通常采用月平均数据进行研究;基于此将声速剖面数据进行月平均,时间分辨率由原来的3小时输出一次,平均为一个月输出一次,得到月平均声速剖面数据集。
16、步骤2的具体步骤如下:
17、步骤2.1,为确保声速剖面的精细化表达,同时考虑到声速剖面的变化主要集中在水深1500米以上,水深1500米以下的声速数据变化不大用于进行聚类的参考意义不大;截取1500米以上的声速剖面数据,采用akima插值方法按照5米的深度间隔,从深度5米插值到1500米共300个深度值,得到等深度间隔的1500米以浅的月平均声速剖面数据集;
18、所述的akima插值方法规定为在两个点之间进行内插,除需要用到这两个点的值之外,还要用到这两个点相近邻的四个点上的值,因此共涉及到6个点(xi,yi)(i=1,2,3,4,5,6);其中,要进行插值的点(x,y)在第3与第4个点之间,x3<x<x4,y3<y<y4;x表示的是声速值,单位为(米/秒);y表示的是深度,单位为(米),插值公式为:
19、y=a0+a1(x-x3)+a2(x-x3)2+a3(x-x3)3;
20、式中:
21、a0=y3,a1=t3,
22、
23、其中t3和t4分贝为第3和第4个点的斜率,斜率计算公式为:
24、
25、式中mi=(yi+1-yi)/(xi+1-xi),由于上式在分母为0时不成立,所以在这种情况下,akima规定:ti=(mi+1-mi)/2或ti=mi;经过上述插值处理建立起等深度间隔的声速剖面数据集;
26、步骤2.2,将等深度间隔的月平均声速剖面数据集表示为声速矩阵c,该矩阵为n×d阶矩阵,n为样本数量,d为深度上的经过插值后的声速采样点数目,矩阵中声速值表示为ci,j(i=1,2,…n;j=1,2,…d)。声速剖面不仅可通过声速c描述,还可以通过声速梯度g来描述,所述的声速梯度更能直观地反映声速剖面在各层的结构变化,有利于提取低维度特征向量进行软聚类;采用声速梯度表示声速剖面,基于梯度计算公式将声速矩阵c换算得到声速梯度矩阵g,矩阵g仍为n×d阶;声速梯度计算公式为:
27、
28、式中,梯度为g,声速为c,深度为d,矩阵g中声速梯度值表示为gi,j(i=1,2,…n;j=1,2,…d);
29、步骤2.3,将声速梯度数据进行标准化处理,使得各个维度的特征向量是独立同分布且统一各特征之间的尺度,加快深度学习速度与准确度;采用z-score标准化(z-scorenormalization),标准化的声速梯度矩阵e仍为n×d阶,即针对每层深度值对应的声速值进行标准化,使得每类数据的平均值为0,标准差为1;标准化后数据表示为ei,j(i=1,2,…n;j=1,2,…d),为每个变量即每层深度的声速梯度的平均值,σj为每层声速梯度的标准差,标准化公式为:
30、
31、经过上述公式换算,得到标准化声速梯度数据集;而标准化声速梯度数据集将作为用于训练、验证与测试深度嵌入式聚类神经网络的数据集。
32、步骤3的具体步骤如下:
33、步骤3.1,搭建ae自编码器,自编码器(auto-encoder)作为一种无监督神经网络,可用于数据降维,由编码器(encoder)和解码器(decoder)两部分神经网络顺序连接而成;通过编码器进行编码,学习输入原始数据隐含的低维度特征,再通过解码器解码输出重构数据;对于d维的声速梯度数据样本x,经过编码器网络时,θ1为编码器特征提取网络的参数,即编码器部分的网络的参数,编码公式为:
34、z=f(x;θ1);
35、得到特征空间中低维度特征向量z,维度为fn,该特征向量z再经过解码器网络,θ2为解码器部分的网络的参数,解码公式为:
36、
37、最后得到重构的声速梯度数据样本自编码器对该样本的误差为:
38、
39、其中,xd(d=1,2,…,d)是输入样本x的第d维;在网络训练中,对于批量的m个输入数据样本,以最小化自编码器误差作为的损失函数:
40、
41、其中,xm(m=1,2,…,m)是批量输入样本的第m个,是对第m个样本的重构;通过反向传播损失来优化模型,使得损失函数最小化,即输入与输出数据无限接近;
42、ae自编码器特征提取网络结构如下:
43、第一层为编码器网络中的输入层,其中xd(d=1,2,…,d)是ae自编码器网络的输入变量,共d个,具体代指原始的声速梯度数据中每一层深度上的声速梯度值;
44、第二层为编码器网络中的隐藏层,由维度为500,500,2000,10的4个全连接层依次连接而成,每个全连接层后采用leakyrelu函数作为激活函数,目的是避免神经元“死亡”,leakyrelu函数表达式如下:
45、
46、其中,x表示输入函数的变量,β=0.1;
47、第三层为编码层,该层为全连接层,无激活函数,该层输入维度为10,输出维度为fn,输出即为数据降维后的特征,表示压缩得到的特征向量的个数;
48、第四层为解码器网络中的隐藏层,由维度为10,2000,500,500的4个全连接层依次连接而成,每个全连接层后采用leakyrelu函数作为激活函数;
49、第五层为解码器网络中的输出层,其中是ae自编码器网络的输出变量,共d个,具体代指重构的声速梯度数据中每一层深度上的声速梯度值;
50、最后,采用adam优化器计算损失函数并利用反向传播损失来优化网络;
51、步骤3.2,输入声速梯度数据集对ae自编码器进行预训练,得到训练后的编码器特征提取网络;通过不断调整迭代的批处理量(batch_size)、学习率(learning_rate)、迭代次数(epochs)共三个参数,得到较好的重构效果。
52、步骤4的具体步骤如下:
53、步骤4.1,初始化,通过对ae自编码器进行预训练,初始化编码器特征提取网络参数θ1,以及解码器部分网络参数θ2;将经过编码器特征提取网络后的低维度特征向量表示为在特征空间中的嵌入点zm(m=1,2,…,2048),执行k-means聚类得到初始的聚类中心μk(k=1,2,…,k),其中将批量训练样本数定义为m,将聚类数定义为k,m表示第m个样本,k表示第k类声速剖面;
54、步骤4.2,计算软分配,使用student的t分布计算降维后特征空间中某个样本对应的嵌入点zm与聚类中心μk之间的相似性,将样本m属于某个类别k簇的概率定义为软分配qm,k,即某个样本的相似性在所有样本相似性之和中的占比:
55、
56、其中,表示某个样本的相似性,zm=f(xm;θ),α为student的t分布的自由度α=1;
57、步骤4.3,最小化kl散度,定义辅助分布pm,k如下:
58、
59、定义辅助分布pm,k的有益效果为:(1)提高簇纯度;(2)更关注具有高置信度的嵌入点;(3)将各簇聚类中心损失贡献,防止聚类数目过多导致隐藏的特征空间扭曲;损失函数定义为软分配分布qm,k和辅助分布pm,k之间的kl散度,损失函数用于衡量上述两个分布的差异程度,模型训练的目标是最小化分配分布qm,k和辅助分布pm,k之间的kl散度,损失函数l计算公式如下:
60、
61、步骤4.4,将上述计算得到的损失同时反馈给聚类层与特征提取网络,使用具有动量的随机梯度下降的sgd(stochastic gradient descent)优化器,分别优化嵌入点zm与聚类中心位置μk,损失函数关于嵌入点zm和聚类中心μk的梯度计算公式如下:
62、
63、
64、将传递给编码器特征提取网络,然后用标准的反向传播去计算编码器特征提取网络参数θ1的梯度优化编码器特征提取网络参数θ1;当两次迭代之间更改的聚类分配点小于设定的目标值时,停止训练,设定的目标值通过人为指定,一般优选为0.001,但不限于0.001。
65、步骤5的具体步骤如下:
66、步骤5.1,将深度嵌入式聚类神经网络对声速梯度数据集进行聚类,以在特征空间中的散点图的形式呈现;
67、步骤5.2,绘制每种类型中聚类中心的声速剖面作为该类型的声速剖面代表;
68、步骤5.3,通过计算平均畸变程度与轮廓系数评价聚类结果质量,并检验最佳聚类数k,将聚类结果的平均畸变程度s1与轮廓系数s2绘制成折线图;
69、平均畸变程度s1实质上是簇内离差平方和的平均,所有样本点到质心的距离之和越小,则认为各个簇中的样本越相似,聚类效果就越好,一般认为平均畸变程度s1折线的拐点为较好的聚类数;平均畸变程度s1计算公式如下:
70、
71、将声速梯度数据集中n个样本划分到k个类中,用clusterk(k=1,2,…,k)表示第k个类的簇中所有嵌入点zn(n=1,2,…,n)的集合;
72、轮廓系数s2是对所有的嵌入点的轮廓系数的平均值,对单个嵌入点而言,a是同类别中其他嵌入点的平均距离,a反映了簇内密集性,b是与其距离最近的不同类别的嵌入点的平均距离,b反映了簇间分散性,s2取值范围为[0,1],数值最大的一般认为是较好的聚类数;轮廓系数s2的计算公式如下:
73、
74、本发明提供了一种基于深度嵌入式聚类神经网络的声速剖面聚类方法,其有益效果在于:
75、1、本发明中引入ae自编码器进行声速剖面数据的特征提取,能够显著压缩数据量,在通常情况下,数据压缩比达到250倍,有效避免了数据量大导致计算资源消耗过多的问题;
76、2、本发明采用声速剖面梯度作为聚类依据,声速梯度可以较好反映声速剖面的轮廓形状与变化趋势,较直接使用声速数据进行聚类更为合理有效;
77、3、本发明改进dec算法将其应用于声速剖面聚类,将声速剖面特征提取步骤与聚类步骤链接起来,采用深度学习技术对这2个步骤进行同时优化,得到更合理的聚类效果;且该优化过程基于深度学习神经网络自动运行完成,优化过程中不需要人为的干预;
78、4、本发明对于使用者而言,在提供声速剖面数据之外,只需要自定义一个初始化参数,即聚类数目k,即可运行模型,不需要提供复杂的初始化参数,操作简便;
79、5、本发明提出的深度嵌入式聚类神经网络模型可以推广应用于全球不同海域的声速剖面聚类,适用性广泛。
- 还没有人留言评论。精彩留言会获得点赞!