文本摘要抽取方法和系统与流程
本公开涉及深度学习领域,尤其涉及一种文本摘要抽取方法和系统。
背景技术:
1、因特网每时每刻都在产生大量数据,使得信息过载问题日益严重,因此,对各类文本进行要点提取成为必要,而获取文本的摘要是其中一个重要的手段。文本摘要按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要需要从源文档中抽取关键句组成摘要,摘要信息全部来源于原文。
2、近年来,预训练语言模型(plm)的发展极大提高了文本摘要抽取的性能。然而,基于预训练语言模型的摘要抽取需要海量的训练数据和极长的运行时间才能获得令人满意的性能。这在大多数应用场景中,是成本和时间上不可行的。
3、为此,需要一种改进的文本摘要抽取方案。
技术实现思路
1、本公开要解决的一个技术问题是提供一种文本摘要抽取方法和系统。该方法将文本摘要抽取任务转化为候选摘要与源文本之间的文本释义问题从而缩小文本摘要抽取任务和预训练语言模型的训练差距,从而能够更好地挖掘plm中已经存在的知识用于提升模型性能。进一步地,可以从现有的文本释义任务丰富训练数据集中学习相关知识,通过知识迁移辅助模型识别更能释义文档核心语义信息的候选摘要,从而弥补小规模数据集导致的训练监督信号缺失问题。
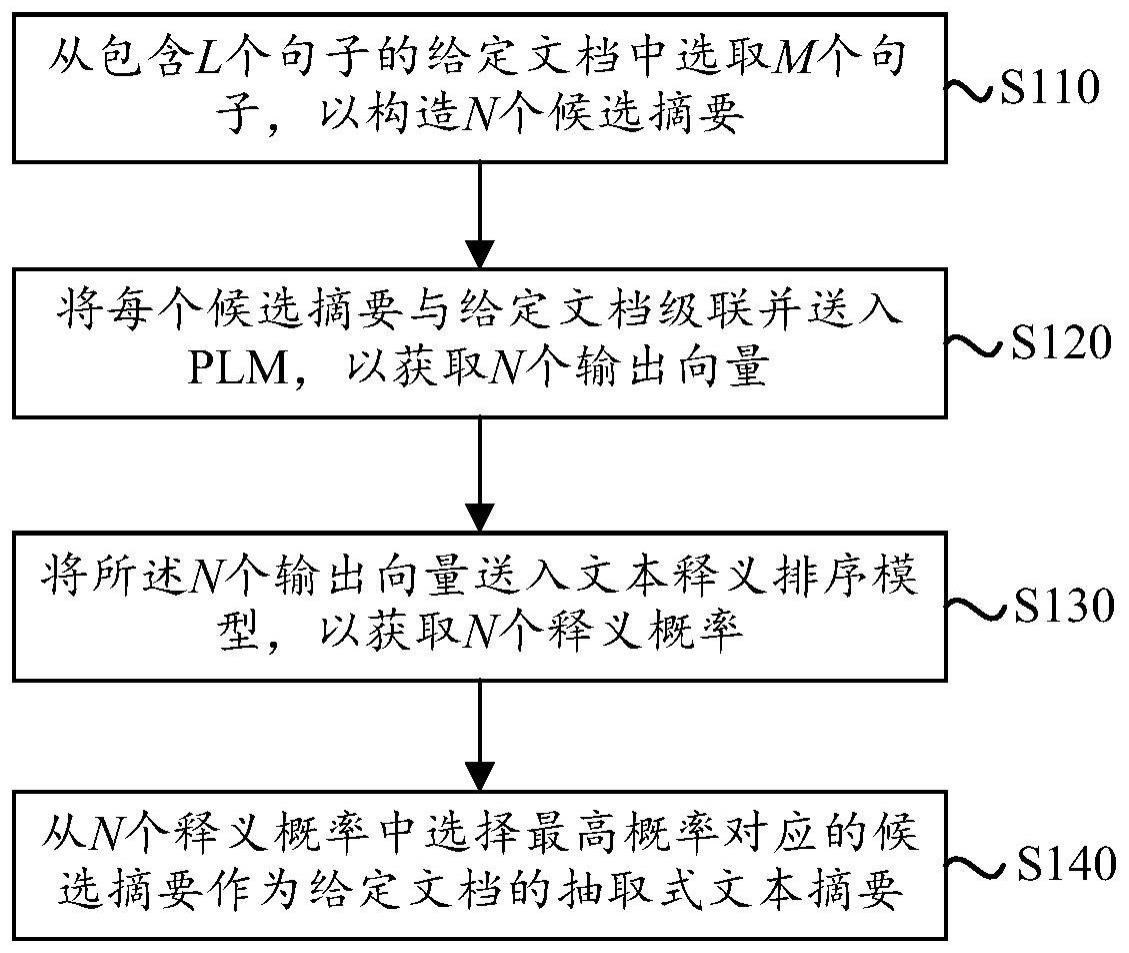
2、根据本公开的第一个方面,提供了一种文本摘要抽取方法,包括:从包含l个句子的给定文档中选取m个句子,以构造n个候选摘要,其中,m<l,l≤n;将每个候选摘要与给定文档级联并送入预训练语言模型(plm),以获取n个输出向量;将所述n个输出向量送入文本释义排序模型,以获取n个释义概率;从所述n个释义概率中选择最高概率对应的候选摘要作为所述给定文档的抽取式文本摘要。
3、可选地,在使用文本摘要抽取任务数据集进行文本摘要抽取任务的训练阶段,每个给定文档对应于一个参考摘要。
4、可选地,所述方法还包括:在训练阶段,计算n个候选摘要各自与所述参考摘要的相似度分数并将n个候选摘要中与所述参考摘要的相似度分数最高的一个候选摘要的标签设为1,其余候选摘要的标签设为0,并基于上述标签以及获取的所述释义概率定义作为交叉熵损失的第一损失函数;以及基于第一损失函数,微调所述plm并训练所述文本释义排序模型。
5、可选地,所述方法还包括:在训练阶段,计算n个候选摘要各自与所述参考摘要的相似度分数并基于相似度分数的高低进行降序排序;将基于相似度分数排序在前的候选摘要作为正样本,排序在后的候选摘要作为负样本,以定义作为对比损失的第二损失函数;以及基于第二损失函数,微调所述plm并训练所述文本释义排序模型。
6、可选地,所述方法还包括:在训练阶段,将参考摘要与所述给定文档级联并送入所述plm,以获取参考摘要输出向量;将所述参考摘要输出向量送入所述文本释义排序模型;定义第三损失函数,用于在所述排序模型针对所述参考摘要输出向量的释义概率不高于所有候选摘要的输出向量的释义概率时产生损失;以及基于第三损失函数,微调所述plm并训练所述文本释义排序模型。
7、可选地,所述方法还包括:使用文本释义数据集进行训练,以微调所述plm并训练所述文本释义排序模型;以及使用基于所述文本释义数据集训练后的所述plm和所述文本释义排序模型,作为使用所述文本摘要抽取任务数据集进行所述文本摘要抽取任务训练的初始模型。
8、可选地,所述方法还包括:在使用文本释义数据集进行训练时,将真实标签的释义概率定义pg为正样本,将1-pg定义为负样本,以定义对比损失来微调所述plm并训练所述文本释义排序模型。
9、可选地,所述方法还包括:在使用文本摘要抽取任务数据集进行文本摘要抽取任务的训练阶段,使用与基于文本释义数据集进行训练时具有对应形式的损失函数进行所述plm的微调以及所述文本释义排序模型的训练。
10、可选地,从包含l个句子的给定文档中选取m个句子,以构造n个候选摘要包括:基于相关性,从l个句子中选出k个句子;以及从k个句子中选取m个句子,以构造n个候选摘要,其中,m<k<l。
11、可选地,从l个句子中选出排名显著的k个句子包括:将所述l个句子送入所述plm,并获取对应的l个句向量;以及将句向量送入相关性评分模型,并选择评分前k的句子作为排名显著的所述k个句子,其中,在使用文本摘要抽取任务数据集进行文本摘要抽取任务的训练阶段,训练所述相关性评分模型。
12、根据本公开的第二个方面,提供了一种文本摘要抽取系统,包括:存储服务器,用于存储预训练语言模型;以及文本摘要抽取服务器,用于执行如第一方面所述的方法。
13、根据本公开的第三个方面,提供了一种计算设备,包括:处理器;以及存储器,其上存储有可执行代码,当可执行代码被处理器执行时,使处理器执行如上述第一方面所述的方法。
14、根据本公开的第四个方面,提供了一种计算机程序产品,包括可执行代码,当所述可执行代码被电子设备的处理器执行时,使所述处理器执行如上述第一方面所述的方法。
15、根据本公开的第五个方面,提供了一种非暂时性机器可读存储介质,其上存储有可执行代码,当可执行代码被电子设备的处理器执行时,使处理器执行如上述第一方面所述的方法。
16、由此,本发明把文本摘要抽取重新表述为文本释义,能够利用plm的知识来促进摘要抽取任务。进一步地,本发明还可以借助迁移学习,放宽实现良好性能的数据需求,从而实现极低资源下文本摘要抽取任务的良好性能。
技术特征:
1.一种文本摘要抽取方法,包括:
2.如权利要求1所述的方法,在使用文本摘要抽取任务数据集进行文本摘要抽取任务的训练阶段,每个给定文档对应于一个参考摘要,并且所述方法还包括:
3.如权利要求1所述的方法,在使用文本摘要抽取任务数据集进行文本摘要抽取任务的训练阶段,每个给定文档对应于一个参考摘要,并且所述方法还包括:
4.如权利要求1所述的方法,在使用文本摘要抽取任务数据集进行文本摘要抽取任务的训练阶段,每个给定文档对应于一个参考摘要,并且所述方法还包括:
5.如权利要求1所述的方法,还包括:
6.如权利要求5所述的方法,还包括:
7.如权利要求6所述的方法,还包括:
8.如权利要求1所述的方法,其中,从包含l个句子的给定文档中选取m个句子,以构造n个候选摘要包括:
9.如权利要求8所述的方法,其中,从l个句子中选出排名显著的k个句子包括:
10.一种文本摘要抽取系统,包括:
11.一种计算设备,包括:
12.一种计算机程序产品,包括可执行代码,当所述可执行代码被电子设备的处理器执行时,使所述处理器执行如权利要求1至9中任何一项所述的方法。
13.一种非暂时性机器可读存储介质,其上存储有可执行代码,当所述可执行代码被电子设备的处理器执行时,使所述处理器执行如权利要求1至9中任何一项所述的方法。
技术总结
本公开涉及一种文本摘要抽取方法和系统。该方法包括:从包含L个句子的给定文档中选取M个句子,以构造N个候选摘要;将每个候选摘要与给定文档级联并送入PLM,获取N个输出向量;将N个输出向量送入文本释义排序模型,获取N个释义概率;从N个释义概率中选择最高概率对应的候选摘要作为给定文档的抽取文本摘要。本发明通过将摘要抽取任务转化为候选摘要与源文本之间的文本释义问题,缩小摘要抽取任务和PLM的训练差距,能够更好地挖掘PLM的知识用以提升模型性能。进一步地,利用知识迁移从现有文本释义丰富训练数据集中学习相关知识,辅助模型识别更能释义文档核心语义的候选摘要,弥补小规模数据集导致的训练监督信号缺失问题。
技术研发人员:汪诚愚,唐莫鸣
受保护的技术使用者:阿里巴巴(中国)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!