一种样本预测方法、装置、设备及计算机可读存储介质与流程
本技术涉及人工智能技术,尤其涉及一种样本预测方法、装置、设备及计算机可读存储介质。
背景技术:
1、随着人工智能技术的不断发展,基于深度学习模型进行样本预测,可以广泛应用到各类场景中,例如,智能对话系统、文本翻译、信息推荐等场景中。为了提升深度学习模型的样本预测的性能,需要利用大量的标注样本进行训练。而对于数据中存在着数据生成者的隐私的场景,需要通过利用能够不泄露隐私的联邦学习以实现知识共享,以提升样本预测的性能。然而,相关技术中,存在在对样本预测进行性能提升时所需要消耗的算力与传输资源较多的问题。
技术实现思路
1、本技术实施例提供一种样本预测方法、装置、设备及计算机可读存储介质、计算机程序产品,能够减少在对样本预测进行性能提升时所需要消耗的算力与传输资源。
2、本技术实施例的技术方案是这样实现的:
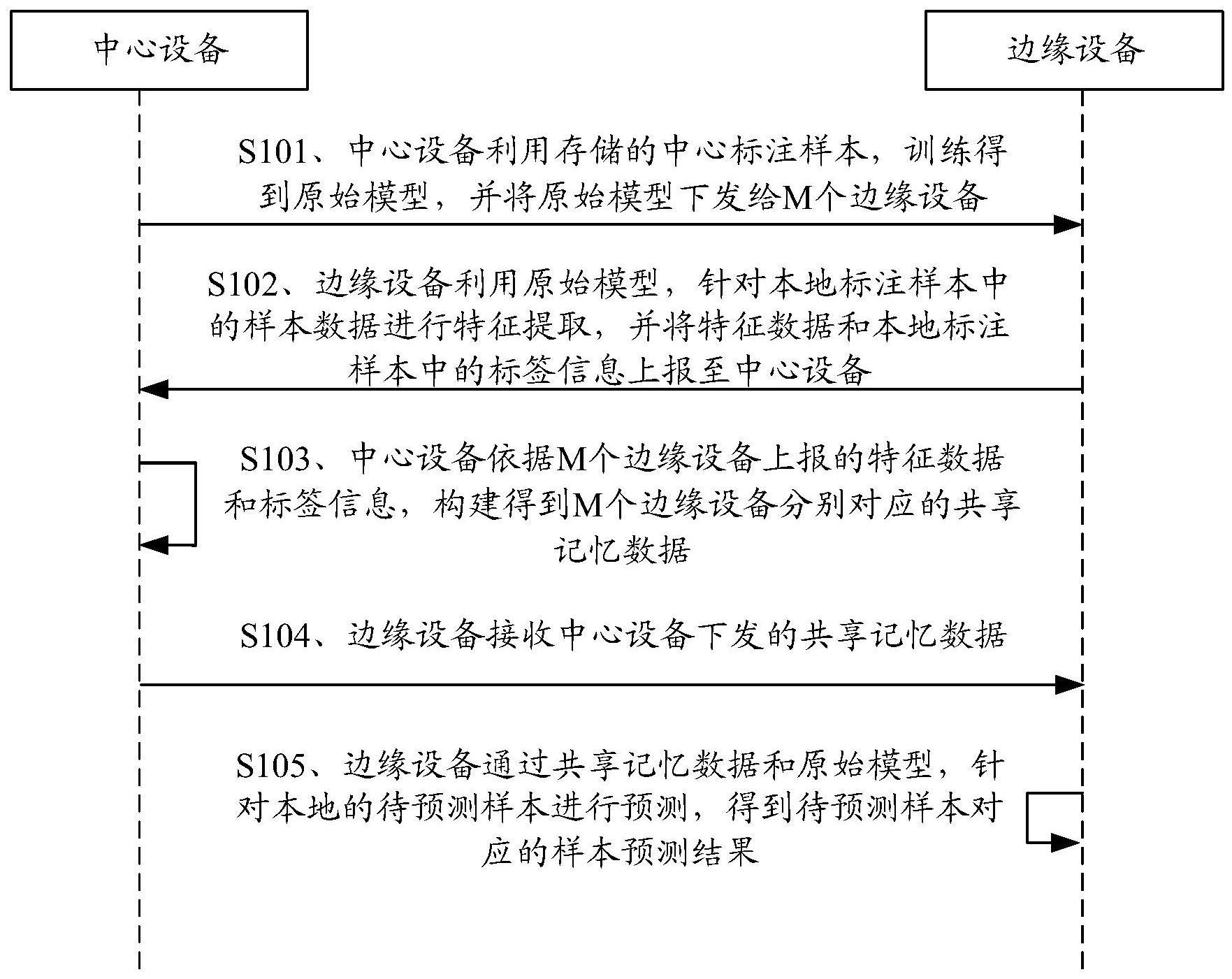
3、本技术实施例提供一种样本预测方法,包括:
4、接收中心设备下发的原始模型,其中,所述原始模型是所述中心设备利用所存储的中心标注样本训练得到的模型;
5、利用所述原始模型,针对本地标注样本中的样本数据进行特征提取,并将特征数据和所述本地标注样本中的标签信息上报至所述中心设备;
6、接收所述中心设备下发的共享记忆数据,其中,所述共享记忆数据由所述中心设备利用针对本地标注样本所上报的特征数据和标签信息构成;
7、通过所述共享记忆数据和所述原始模型,针对本地的待预测样本进行预测,得到所述待预测样本对应的样本预测结果。
8、本技术实施例提供一种样本预测方法,包括:
9、利用存储的中心标注样本,训练得到原始模型,并将所述原始模型下发给m个边缘设备;其中,m≥2,m为整数;
10、接收m个所述边缘设备针对本地标注样本上报的特征数据和标签信息;
11、依据m个所述边缘设备上报的特征数据和标签信息,构建得到m个所述边缘设备分别对应的共享记忆数据;
12、向m个所述边缘设备分别下发对应的所述共享记忆数据,以使每个所述边缘设备通过所述共享记忆数据和所述原始模型,针对本地的待预测样本进行预测,得到所述待预测样本对应的预测结果。
13、本技术实施例提供一种样本预测装置,包括:
14、第一接收模块,用于接收中心设备下发的原始模型,其中,所述原始模型是所述中心设备利用所存储的中心标注样本训练得到的模型;
15、特征提取模块,用于所述原始模型,针对本地标注样本中的样本数据进行特征提取;
16、第一发送模块,用于将特征数据和所述本地标注样本中的标签信息上报至所述中心设备;
17、所述第一接收模块,还用于接收所述中心设备下发的共享记忆数据,其中,所述共享记忆数据由所述中心设备利用针对本地标注样本所上报的特征数据和标签信息构成;
18、预测处理模块,用于通过所述共享记忆数据和所述原始模型,针对本地的待预测样本进行预测,得到所述待预测样本对应的样本预测结果。
19、在本技术的一些实施例中,所述预测处理模块,还用于针对本地的所述待预测样本,从所述共享记忆数据中查找得到至少一个近邻样本;依据所述待预测样本和每个所述近邻样本之间的特征距离,以及每个所述近邻样本的标签信息,针对所述待预测样本确定第一预测结果;利用所述原始模型对所述待预测样本进行预测,得到第二预测结果;将所述第一预测结果和所述第二预测结果进行加权融合,得到所述待预测样本对应的所述样本预测结果。
20、在本技术的一些实施例中,所述预测处理模块,还用于依据所述待预测样本和每个所述近邻样本之间的特征距离,为每个所述近邻样本分配标签权重;针对每个所述近邻样本的所述标签信息进行特征编码,得到标签编码;将所述标签编码和所述标签权重的乘积,确定为每个所述近邻样本对应的样本分量;将至少一个所述近邻样本的样本分量进行累加,得到所述待预测样本的第一预测结果。
21、在本技术的一些实施例中,所述共享记忆数据中包括:多个特征数据;所述预测处理模块,还用于计算所述待预测样本的特征分别与每个所述特征数据之间的特征距离;依据所述特征距离,从多个所述特征数据中查找得到至少一个所述近邻样本。
22、在本技术的一些实施例中,所述近邻样本的标签权重,与所述待预测样本和所述近邻样本之间的所述特征距离成反比。
23、本技术实施例提供一种样本预测装置,包括:
24、模型训练模块,用于利用存储的中心标注样本,训练得到原始模型;
25、第二发送模块,用于将所述原始模型下发给m个边缘设备;其中,m≥2,m为整数;
26、第二接收模块,用于接收m个所述边缘设备针对本地标注样本上报的特征数据和标签信息;
27、记忆构建模块,用于依据m个所述边缘设备上报的特征数据和标签信息,构建得到m个所述边缘设备分别对应的共享记忆数据;
28、所述第二发送模块,还用于向m个所述边缘设备分别下发对应的所述共享记忆数据,以使每个所述边缘设备通过所述共享记忆数据和所述原始模型,针对本地的待预测样本进行预测,得到所述待预测样本对应的预测结果。
29、在本技术的一些实施例中,所述记忆构建模块,还用于利用每个所述边缘设备的特征数据和标签信息,构建得到每个所述边缘设备的记忆表格;针对第i个所述边缘设备的记忆表格,从剩余的m-1个所述边缘设备的记忆表格中筛选得到k个待合并表格;其中,1≤k≤m-1,i为正整数;将第i个所述边缘设备的记忆表格与k个所述待合并表格的并集,确定为第i个所述边缘设备的共享记忆数据;当将i迭代至m时,得到m个所述边缘设备分别对应的共享记忆数据。
30、在本技术的一些实施例中,所述记忆构建模块,还用于对第i个所述边缘设备的记忆表格的原型向量,与剩余的m-1个所述边缘设备的记忆表格的原型向量分别进行相似度计算,得到表格相似度;从剩余的m-1个所述边缘设备的记忆表格中,对所述表格相似度最大的k个记忆表格进行筛选,得到k个所述待合并表格。
31、在本技术的一些实施例中,所述记忆表格的原型向量通过以下处理得到:针对所述记忆表格中的所有特征数据进行均值计算,并将所得到的特征均值作为所述记忆表格的原型向量。
32、在本技术的一些实施例中,所述记忆构建模块,还用于针对每个所述边缘设备的特征数据所对应的预测结果,以及所述标签信息进行误差计算,得到预测误差;利用所述预测误差大于误差阈值的特征数据,以及所述预测误差大于误差阈值的特征数据所对应的标签信息,构建得到每个所述边缘设备的所述记忆表格。
33、本技术实施例提供一种边缘设备,包括:
34、第一存储器,用于存储计算机可执行指令;
35、第一处理器,用于执行所述第一存储器中存储的计算机可执行指令时,实现本技术实施例提供边缘设备侧的样本预测方法。
36、本技术实施例提供一种中心设备,包括:
37、第二存储器,用于存储计算机可执行指令;
38、第二处理器,用于执行所述第二存储器中存储的计算机可执行指令时,实现本技术实施例提供中心设备侧的样本预测方法。
39、本技术实施例提供一种计算机可读存储介质,存储有计算机可执行指令,用于引起第一处理器执行时,实现本技术实施例提供的边缘设备侧的样本预测方法,引起第二处理器执行时,实现本技术实施例提供的中心设备侧的样本预测方法。
40、本技术实施例提供一种计算机程序产品,包括计算机程序或计算机可执行指令,所述计算机程序或计算机可执行指令被第一处理器执行时实现本技术实施例提供的边缘设备侧的样本预测方法,被第二处理器执行时实现本技术实施例提供的中心设备侧的样本预测方法。
41、本技术实施例具有以下有益效果:边缘设备会利用中心设备训练得到的原始模型,提取本地标注样本中的样本数据的特征数据,再将特征数据和标签信息上报至中心设备,以使得中心设备结合其所上报的特征数据的标签信息,以及其他的边缘设备所上报的特征数据的标签信息,构建共享记忆数据,最后在边缘设备本地,结合共享记忆数据对待预测样本进行预测,如此,只需要一次模型参数传输,以及一次共享以及数据传输,就能够替代多轮次的模型参数传输,以较少的传输资源就能够实现知识共享,并且能够使得边缘设备跳过针对大规模的原始模型的参数微调过程,减少了在实现知识共享时边缘设备所需要消耗的算力资源,也就能够减少在对样本预测进行性能提升时所需要消耗的算力与传输资源。
- 还没有人留言评论。精彩留言会获得点赞!