一种基于改进BERT的自动文本纠错算法及系统
本技术涉及机器学习,具体而言,涉及一种基于改进bert的自动文本纠错算法及系统。
背景技术:
1、文本纠错是文本校对的重要组成部分,它为自动检错过程中检测到的错误字符串提供修改建议,并协助用户进行纠错。随着技术的发展,文字自动纠错技术的应用十分广泛。如新闻校对、出版物校对、键盘输入法、汉语教学、语音识别等等。且相比传统的人工审核,文本自动纠错可以节省大量时间、人力等资源并更好的保证文本正确性。
2、虽然目前市场上有不少商业化的文本校对软件产品,并取得了不错的成果,现有的算法仍未充分融合汉字的多模态特征,检错机制的功能也没有得到充分利用,也因此算法仍有一定改进空间。近些年来,对中文纠错算法的研究可以为三类:基于规则的方法、基于统计的方法和基于深度学习的方法。
3、基于规则的方法:根据句子的短语和句法规则对句子进行错误判断,在做些操作之前会先对该句子进中文分词、句法分析和短语识别等操作,根据科研人员制定的标准进行判断,如出现无法满足制定的标准则判断为错误。最早期的一些科研工作者最先提出了基于规则的方法,他们通过一些容易理解的规则去自动获取语言知识,另一些科研工作者则研究了一套新的语法规则来解决中文中遇到的拼写错误和语法错误问题。另外,还有一些科研工作者提出了基于扩展的hmm、基于排名的模型以及基于规则的模型。
4、基于统计的方法:构建由一些音近字和形近字组成的混淆集,通过对句子中的部分单词与混淆集进行替换,并由相应的语言模型进行评分操作,通过与原句中的单词和模型评分最高的单词进行对比来发现错字,然后作为修改的依据。
5、基于深度学习的方法:首先,基于规则的方法存在局限性,模型无法适应所有可能出现的情况,因此模型必须不断地增加规则。其次,基于统计的方法和基于规则的模型都无能更好地利用句子的上下文语义信息来对可能出错的单词进行判断。随着深度学习的不断发展,基于序列到序列的模型在文本纠错任务取得了很好的效果,它能更好地利用句子的上下文语义信息,根据句子的上下文语义信息给出更恰当的纠错建议。随着深度神经网络的提出,一些以bert为代表的语言预训练模型在文本纠错领域应用,并取得不错的效果。
6、现有技术存在如下的技术问题:
7、(1)大部分模型在概率预测阶段仅对字符进行预测,虽也在文本纠错任务上取得一定效果,但忽视了对文本纠错任务而言字音特征的重要性,因此其性能仍有提升空间。
8、(2)现有的文本纠错模型从是否检错来看大致分为两种。其一是有检错和纠错两个子模型,先进行检错再根据检错结果进行纠错;其二是直接进行纠错。第一种的检错模型对纠错结果影响较大,若检错有误则纠错网络就失去意义;而第二种直接进行纠错的方案又完全忽略了检错的作用,造成纠错不充分。
技术实现思路
1、本技术的目的在于提供一种基于改进bert的自动文本纠错算法,其能够在文本纠错任务重能更好的融合字音特征和检错信息,进而能够更好的实现对字符的纠错。
2、本技术的另一目的在于提供一种基于改进bert的自动文本纠错系统,其能够运行一种基于改进bert的自动文本纠错算法。
3、本技术的实施例是这样实现的:
4、第一方面,本技术实施例提供一种基于改进bert的自动文本纠错算法,其包括选取plome模型作为基线模型,沿用plome模型的混合嵌入层和混合掩码策略建立改进模型;改进模型通过字符预测和字音预测进行叠加得到预测的结果,其中,预测结果通过将字符预测概率和字音预测概率进行加权求和并计算最终分布,取最高值对应字符作为最终预测结果。
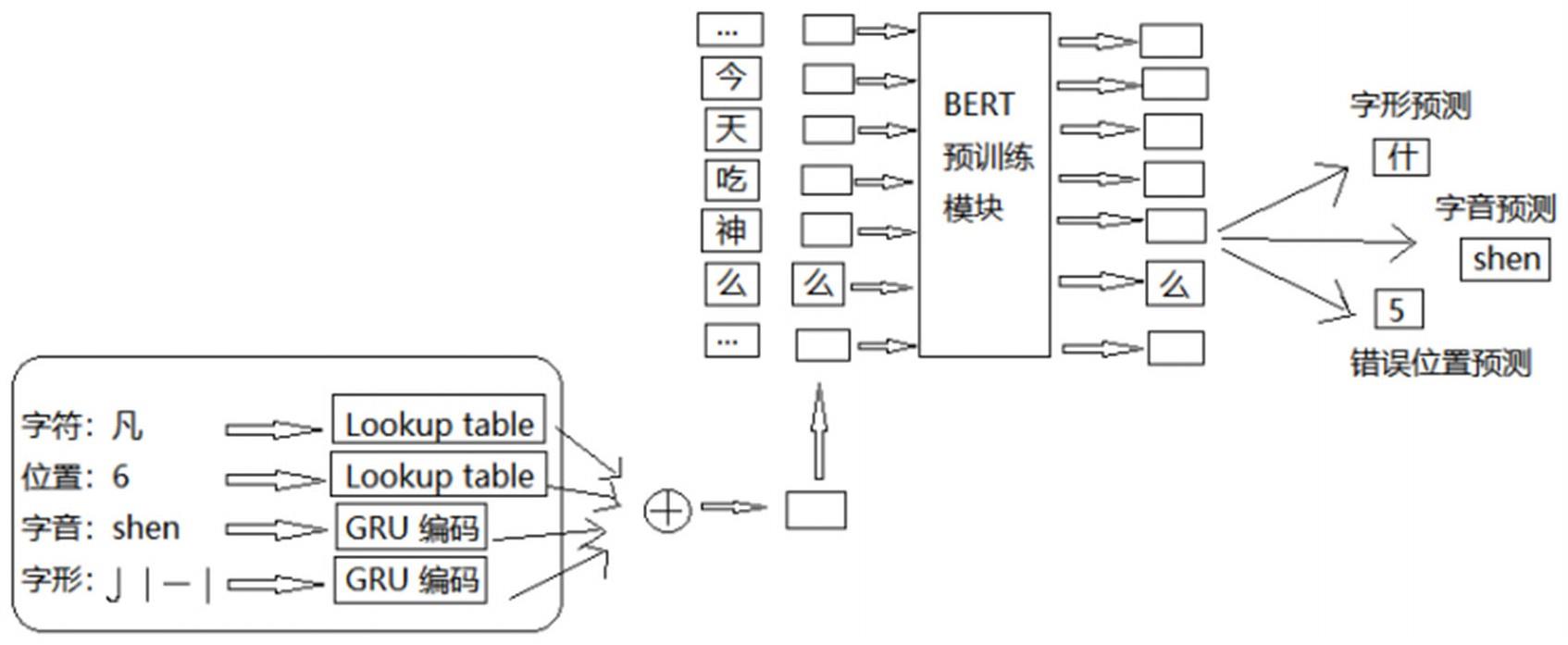
5、在本技术的一些实施例中,上述还包括:在plome模型里融入检错预测模块,其中,检错预测模块根据数据集构建错误位置标签,在嵌入层对训练集中的句子对逐字符进行查表,并转为向量时,增加判断该字符是否错误的逻辑,若逐字符和标签不一致,则认为该字符是错误字符,将其位置标签设为1,否则设为0。
6、在本技术的一些实施例中,上述还包括:对位置预测设置全连接层的超参数和,维度为2×768,维度为2,则位置预测的全连接层输出为:
7、
8、其中,是bert模型的输出,即最后一个transformer隐藏层的输出向量,位置概率和字音概率分别为:
9、
10、为当输入句子为x={x1,x2,...xn}时,第j个字符被预测为n的概率。
11、在本技术的一些实施例中,上述还包括:计算二分类交叉熵作为错误位置预测值的损失函数:
12、
13、其中是错误位置的标签。最终的损失函数为:
14、
15、其中,是字符预测结果,是字音预测结果;
16、
17、其中,和分别是的正确字符和正确字音。
18、在本技术的一些实施例中,上述混合嵌入层包括:混合嵌入采用字符嵌入、位置嵌入、字音嵌入和字形嵌入之和,字音嵌入和字形嵌入分别是当前字符的拼音和笔画分别输入一个1层的gru网络中生成的特征向量。
19、在本技术的一些实施例中,上述混合掩码策略包括:混合掩码将输入的句子掩盖预设百分比的字符,让模型来预测被掩盖字符以掌握该语言的语境语义知识。
20、在本技术的一些实施例中,上述改进模型通过字符预测和字音预测进行叠加得到预测的结果包括:字符预测和字音预测的公式表示如下:
21、
22、其中,(yj=k|x)和(gj=m|x)分别为字符预测概率和字音预测概率。(yj=k|x)为当输入句子为x={x1,x2,...xn}时,融合字符预测和字音预测结果后,第j个字符被预测为字典中第k个字符的概率,m是第k个字符对应的字音。
23、第二方面,本技术实施例提供一种基于改进bert的自动文本纠错系统,其包括建立改进模型模块,用于选取plome模型作为基线模型,沿用plome模型的混合嵌入层和混合掩码策略建立改进模型;
24、融合预测模块,用于改进模型通过字符预测和字音预测进行叠加得到预测的结果,其中,预测结果通过将字符预测概率和字音预测概率进行加权求和并计算最终分布,取最高值对应字符作为最终预测结果;
25、检错预测模块,用于在plome模型里融入检错预测模块,其中,检错预测模块根据数据集构建错误位置标签,在嵌入层对训练集中的句子对逐字符进行查表,并转为向量时,增加判断该字符是否错误的逻辑,若逐字符和标签不一致,则认为该字符是错误字符,将其位置标签设为1,否则设为0。
26、第三方面,本技术实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如一种基于改进bert的自动文本纠错算法中任一项的算法。
27、相对于现有技术,本技术的实施例至少具有如下优点或有益效果:
28、基于改进的bert 的文本纠错算法选取plome模型作为基线模型,沿用plome模型的混合嵌入层和混合掩码策略使得在文本纠错任务重能更好的融合字音特征和检错信息,进而能够更好的实现对字符的纠错。
- 还没有人留言评论。精彩留言会获得点赞!