基于网络爬虫方式的智能评估方法
本发明涉及智能评估,特别涉及一种基于网络爬虫方式的智能评估方法。
背景技术:
1、我国自然灾害频发,每年因自然灾害所造成的国民gdp损失达数十亿元,对我国社会发展、城市化进展、国民经济带来巨大损失,因此针对全国自然灾害gdp损失评估的研究对全国自然灾害的评估、预判、防范有着十分重要的意义,对我国易发生自然灾害的地区的防灾减灾工程提供了参考依据。
2、目前,国内外并没有一个有效的关于全国自然灾害gdp损失评估方法与体系。国内外关于灾害评估的研究方向往往以风险评估、风险预测、单个灾害损失量、整体防灾减灾能力评估为主,同时前人针对风险评估的过程中,常掺杂着大量的人为因素对最终风险评估的干扰,从而导致评估结果准确性较差。
3、因此,针对上述问题,本发明首次提出一种基于网络爬虫方式的智能评估方法。首先以网络微博、网络新闻、灾害报告、论文、网络报纸等为平台,确定各种自然灾害对国家gdp所造成损失的关键词汇,依据爬虫获取关键词汇建立自然灾害对我国gdp造成损失的评价体系。统计出全国各个自然灾害事件发生的概率并作为评价体系中各级指标的权重。统计各个层次的指标出现的概率,包括三级指标中各个指标的出现概率以及二级指标中各个指标的条件概率,依次为基础采用贝叶斯网络法对各个指标进行权重的分配,从而客观地评价出自然灾害对国家gdp所造成的损失。该方法优势在于,针对全国自然灾害gdp损失评估的过程中,所有关于自然灾害的数据均是客观数据,没有任何人为因素的影响,相对于传统方法相比,告别了主观因素对评估结果的干扰,提高了评估结果的客观性、科学性。
技术实现思路
1、本发明提供一种基于网络爬虫方式的智能评估方法,主要利用客观事实数据,对灾害事件的权重进行统计,通过对网络资源爬虫方式获取三级指标发生概率以及二级指标的条件概率,进一步获取各级指标的客观权重,完成全国自然灾害gdp损失的评估,提高评估的精准性。
2、本发明提供一种基于网络爬虫方式的智能评估方法,包括:
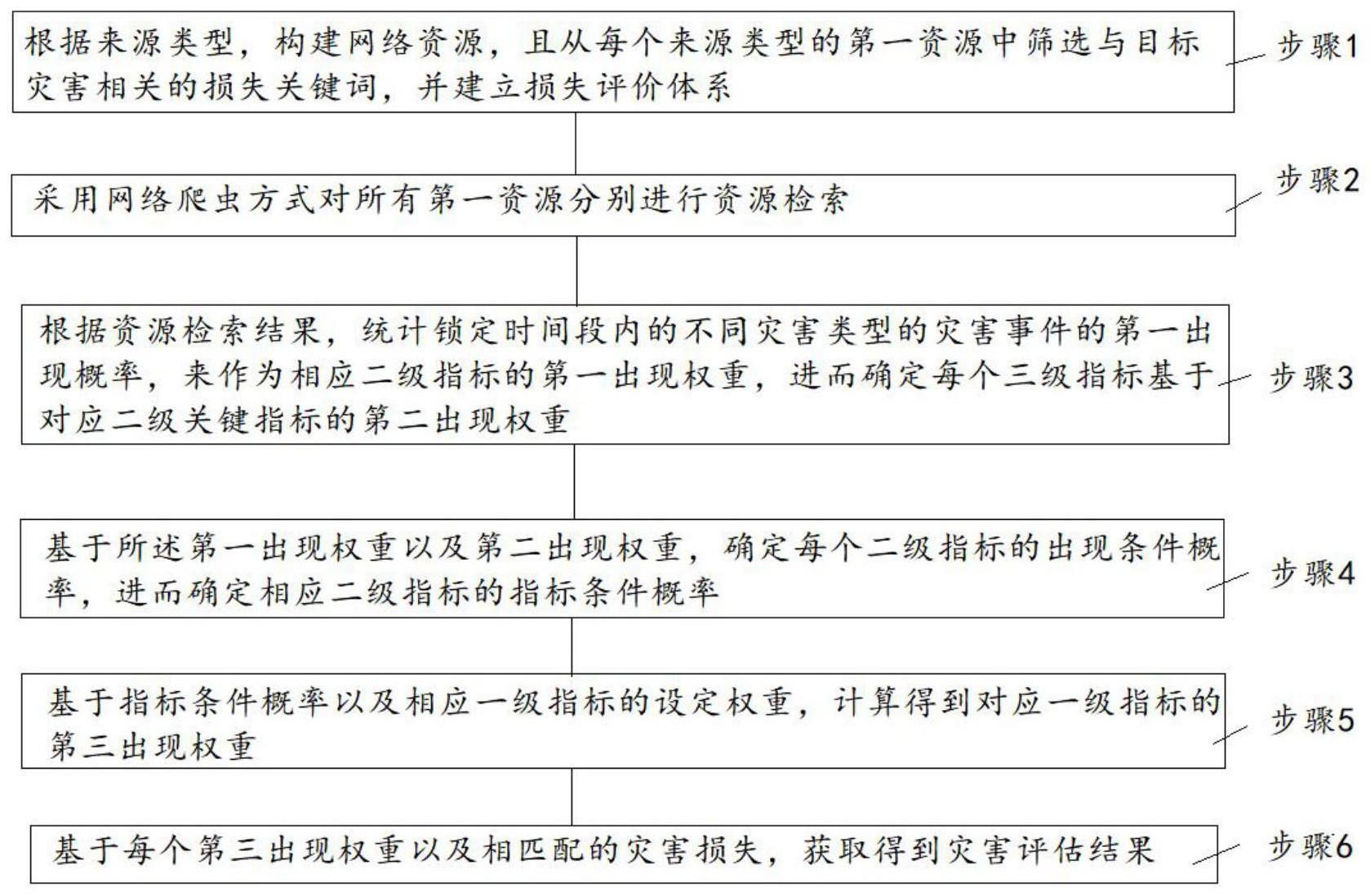
3、步骤1:根据来源类型,构建网络资源,且从每个来源类型的第一资源中筛选与目标灾害相关的损失关键词,并建立损失评价体系;
4、步骤2:采用网络爬虫方式对所有第一资源分别进行资源检索;
5、步骤3:根据资源检索结果,统计锁定时间段内的不同灾害类型的灾害事件的第一出现概率,来作为相应二级指标的第一出现权重,进而确定每个三级指标基于对应二级关键指标的第二出现权重;
6、步骤4:基于所述第一出现权重以及第二出现权重,确定每个二级指标的出现条件概率,进而确定相应二级指标的指标条件概率;
7、步骤5:基于指标条件概率以及相应一级指标的设定权重,计算得到对应一级指标的第三出现权重;
8、步骤6:基于每个第三出现权重以及相匹配的灾害损失,获取得到灾害评估结果。
9、优选的,进而确定每个三级指标基于对应二级关键指标的第二出现权重,包括:
10、
11、其中,p(a11)表示三级指标a11基于对应二级指标a1的第二出现权重;p(a1a11)表示二级指标a1的第一出现权重;p(a1|a11)表示对应二级指标a1的出现条件概率。
12、优选的,基于所述第一出现权重以及第二出现权重,确定每个二级指标的出现条件概率,进而确定相应二级指标的指标条件概率,包括:
13、
14、其中,p'(ak)表示相应二级指标的指标条件概率;p(a1|a1k)表示相应二级指标a1基于对应第三指标a1k的出现条件概率;p(a1|a11)表示相应二级指标a1基于对应第三指标a11的出现条件概率;p(a1|a12)表示相应二级指标a1基于对应第三指标a12的出现条件概率;p(a1|a1j)表示相应二级指标a1基于对应第三指标a1j的出现条件概率。
15、优选的,基于指标条件概率以及相应一级指标的设定权重,计算得到对应一级指标的第三出现权重,包括:
16、
17、其中,wi'表示对应一级指标的第三出现权重;pi表示对应一级指标的指标条件概率;wi表示对应一级指标的设定权重;n表示对应一级指标的指标个数。
18、优选的,基于每个第三出现权重以及相匹配的灾害损失,获取得到灾害评估结果,包括:
19、
20、其中,gi表示对应一级指标的灾害损失因子;s表示灾害评估结果。
21、优选的,根据来源类型,构建网络资源,包括:
22、获取每个来源类型的类型编码,并从资源数据库中匹配与所述类型编码一致的初始资源;
23、基于所述资源数据库的检索工具,来获取相应的匹配日志,并对所述匹配日志进行聚类分析,得到每个聚类结果对应的聚类类型,确定历史匹配窗口;
24、获取每个历史匹配窗口的窗口编码以及窗口使用频次,向对应历史匹配窗口赋予第一权重;
25、统计同聚类类型中所有历史匹配窗口的总窗口使用频次以及对应同聚类类型中每次匹配资源基于该次总匹配资源的资源占比,向对应聚类类型赋予第二权重;
26、基于所述第一权重以及第二权重,得到对应初始资源的资源有效性;
27、对所述资源有效性进行排序,并对前n0个初始资源所对应的来源类型进行全部保留,对剩余初始资源所对应的来源类型进行临时保留;
28、判断全部保留的来源类型所对应的资源信息是否满足资源构建标准;
29、若满足,则将对应的资源信息作为网络资源;
30、若不满足,则获取每个剩余来源类型的资源关系网络以及资源使用网络;
31、根据所述资源关系网络以及资源使用网络,从匹配的剩余初始资源中筛选可用资源;
32、构建对应可用资源的第一可用函数,同时,构建满足资源构建标准的第二可用函数;
33、根据所述第一可用函数对所述第二可用函数进行资源扩展,得到网络资源。
34、优选的,根据所述第一可用函数对所述第二可用函数进行资源扩展,得到网络资源,包括:
35、确定所述第一可用函数所涉及到的资源来源的第一数量以及确定所述第二可用函数所涉及到的资源来源的第二数量;
36、根据临时保留的资源来源的第三数量、第一数量以及第二数量,计算所述第一可用函数对所述第二可用函数的适配系数;
37、
38、其中,p0表示适配系数;b1表示基于第一可用函数确定的所有可用资源;b2表示基于第二可用函数确定的所有网络资源;l n表示对数函数符号;m3表示第三数量;m1表示第一数量;m2表示第二数量;表示第一可用函数所涉及来源数量的第一权重;表示第二可用函数所涉及来源数量的第二权重;
39、当所述适配系数大于或等于预设系数时,将所述第一可用函数涉及到的可用资源补充到所述第二可用函数涉及到的网络资源中;
40、否则,确定每个剩余来源的来源资源存在的相关资源,并补充到所述第二可用函数涉及到的网络资源中。
41、优选的,根据来源类型,构建网络资源,且从所述网络资源中的每个第一子资源中筛选与目标灾害相关的损失关键词,并建立损失评价体系,包括:
42、筛选每个第一子资源中的损失初始词,并与词性数据库进行匹配,向每个损失初始词进行词性标注,其中,每个第一子资源中包括n1个损失初始词;
43、对每个第一子资源中的每个损失初始词按照进行随机组合,获取得到个组合阵列,其中,rand表示随机函数;n1表示对应第一子资源中所包含的损失初始词的总个数;[]表示取整函数;
44、按照组合阵列的词性组合,从词分析数据库中调取词分析方式,对相应词性组合进行匹配分析,将数量最大的前两个匹配分析结果进行保留,并构建匹配子矩阵,其中,所述匹配子矩阵为2行列;
45、基于所有匹配子矩阵,构建得到初始矩阵,其中,初始矩阵为2×m4列列,其中,m4表示第一子资源的资源个数;表示从所有第一子资源中所对应的列的最大数量,且对所述初始矩阵中的空闲位置进行0设置;
46、并对所述初始矩阵中的一致行向量进行留一删除,得到第一矩阵;
47、锁定所述第一矩阵中存在的最多有效元素的第一行,并将所述第一行分别与其余每一行进行交集匹配,同时,锁定同元素基于列的出现次数大于预设个数的第一元素;
48、根据交集匹配结果以及第一元素,确定损失关键词;
49、将所有损失关键词进行整合,建立损失评价体系。
50、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
51、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!