一种基于长短期偏好的科技情报推荐方法
本发明涉及一种科技情报推荐方法方法,具体涉及一种基于长短期偏好的科技情报推荐方法,属于推荐系统领域。
背景技术:
1、随着互联网和信息技术的飞速发展,科技情报的产生和传播速度越来越快。为了帮助用户从海量信息中快速找到感兴趣的科技情报,推荐系统就成为了一种重要的解决方案。推荐系统通过分析用户的偏好和行为,为用户推荐可能感兴趣的信息。然而,在面对科技情报推荐任务时,现有的推荐系统仍存在一定的局限性。
2、首先,现有推荐系统主要关注用户的短期行为,忽略了用户的长期兴趣。用户的兴趣是多样化的,既有长期稳定的兴趣,也涵盖短暂的突发兴趣。过分关注短期行为可能导致推荐结果偏离用户的长期兴趣,进而降低推荐质量和用户满意度。
3、其次,现有的推荐系统在处理多源异构数据方面面临挑战。科技情报来源繁多,包括学术论文、新闻报道、政策文件、产业报告,等等。这些数据类型和结构各异,如何有效地将这些多源异构数据融合到推荐系统中就成为了一个亟待解决的问题。此外,如何为不同类型的科技情报数据赋予合适的权重以提高推荐质量也是一个值得关注的问题。
4、再者,传统的推荐方法在处理海量数据时,面临着计算复杂度过高的问题。随着科技情报数据量的持续增长以及用户数量的不断扩大,传统推荐方法可能无法满足实时推荐的需求。因此,一个高效的科技情报推荐系统应能够在保证推荐质量的前提下,降低计算复杂度,实现高效实时推荐。
5、此外,现有的推荐系统大多侧重于对已有情报的推荐,而在推荐新颖性和突发性的科技情报方面表现不佳。这些新颖性和突发性的情报对于用户来说具有很高的价值,如何在推荐过程中捕捉到这些新颖性和突发性的科技情报,并为用户提供及时推荐成为一个重要的研究方向。
6、综上所述,目前的科技情报推荐系统在捕捉用户长短期兴趣、处理多源异构数据、降低计算复杂度、推荐新颖性和突发性情报等方面仍存在不足,因此亟待发展一种有效的科技情报推荐方法,以提高推荐的准确性和时效性。
技术实现思路
1、本发明的目的是为了解决现有推荐系统在情报表示方面的不足,以及在捕捉用户长短期兴趣方面的不精确问题,创造性地提出一种基于长短期偏好的科技情报推荐方法。
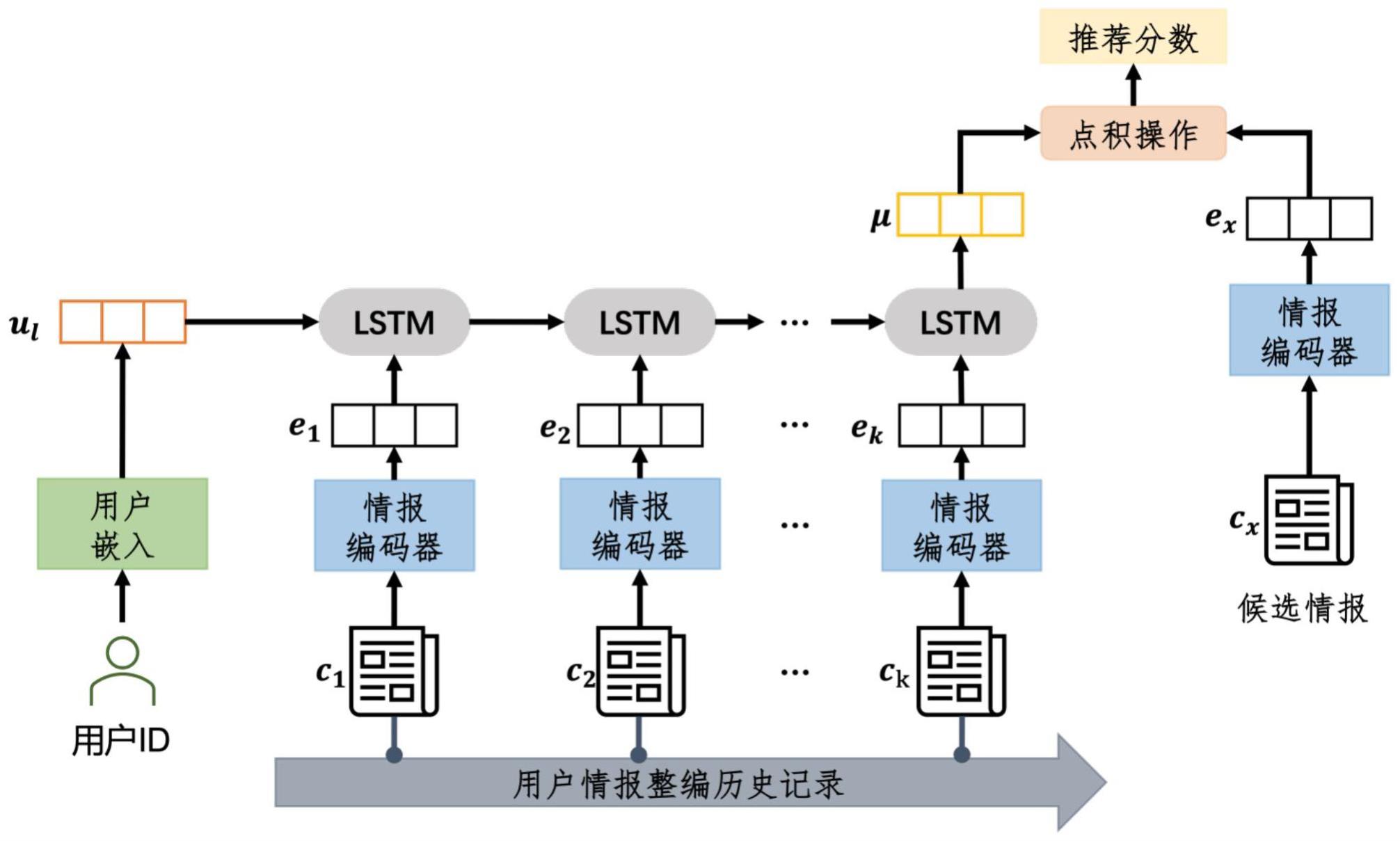
2、本发明的创新点在于:首先,提出了一种结合情报标题、情报来源和情报摘要的情报编码方法,有效解决现有研究在情报表示方面的不足,从而提升情报推荐的准确性。其次,基于上述情报编码方法,本发明提出了一种用户长短期偏好表示方法。通过利用长短期记忆(long short-termmemory,lstm)网络从用户近期的整编记录学习用户的短期偏好表示,同时采用基于id嵌入的方法学习用户的长期偏好表示,并将长期偏好表示作为lstm的初始状态,从而得到用户长短期偏好表示。
3、本发明是通过以下技术方案实现的。
4、首先,定义情报编码器,针对每一篇情报,利用情报的标题、来源和摘要学习情报表示。情报编码器将情报编码为e=[rs,rt,ra],其中,rs为情报来源表示,rt为情报标题表示,ra为情报摘要表示。接着,使用用户id嵌入的方法来表示用户的长期偏好,用户长期偏好表示为ul=wu[u]。然后,使用lstm网络从用户的情报整编历史记录中学习到用户长短期表示u,其中ul作为lstm网络的初始状态。最后,通过计算候选情报表示向量与用户表示向量的点积,作为推荐分数。
5、一种基于长短期偏好的科技情报推荐方法,包括如下步骤:
6、步骤1:定义情报编码器,包括以下步骤;
7、步骤1.1:对情报标题进行编码,包括3个子步骤;
8、步骤1.1.1:将情报标题从单词序列转换成低维语义向量序列。假设情报标题的单词序列为[w1,w2,...,wn],其中n是该标题的长度,通过一个词嵌入查找表该单词序列被转换为一个单词向量序列[e1,e2,...,en],其中v和d分别是词汇量和词嵌入维度;
9、步骤1.1.2:使用多头自注意力网络捕获词与词之间的相互作用来学习单词的上下文表征。第k个注意力头学习的第i个单词的表示计算为:
10、
11、
12、其中,和是第k个自我注意力头中的投影参数,表示第i个和第j个词之间互动的相对重要性。第i个词的多头表征是由h个独立的自我注意力头产生的表征的串联,即
13、步骤1.1.3:使用注意力机制来选择情报标题中的重要词汇。情报标题中第i个词的注意力权重的计算方法是:
14、
15、其中,vw和vw是投影参数,qw是查询向量。情报标题的最终表示为单词的上下文表征的加权和,即
16、步骤1.2:对情报摘要进行编码,包括3个子步骤
17、步骤1.2.1:将情报摘要的单词序列表示为[w1,w2,...,wm],其中m是摘要的长度。通过词嵌入层,将其转换为一个单词向量序列[e1,e2,...,em];
18、步骤1.2.2:使用多头自注意力网络,将单词向量序列作为网络的输入,通过捕获单词间的相互作用来学习上下文词表示
19、步骤1.2.3:使用注意力网络计算每次单词的注意力权重,最后通过对摘要单词的上下文表示进行加权和得到情报摘要表示,即
20、步骤1.3:对情报来源进行编码,包括2个子步骤;
21、步骤1.3.1:使用id嵌入方法将情报来源的离散表示vs转换为低维密集表示es;
22、步骤1.3.2:使用全连接层从来源嵌入中学习隐藏的来源表示,它的计算方式为rs=relu(vs×es+vs),其中vs和vs为全连接层的参数;
23、步骤1.4:将情报标题表示、情报摘要表示和情报来源表示进行拼接,得到情报表示,即e=[rs,rt,ra];
24、步骤2:学习用户长短期偏好表示,包括以下步骤:
25、步骤2.1:使用基于用户id嵌入的方法计算用户的长期偏好表示,用u表示用户的id,用wu表示用户长期偏好表示的查询表,则用户的长期偏好表示为ul=wu[u];
26、步骤2.2:使用lstm网络从用户最近整编的情报历史记录中计算用户短期偏好表示;
27、步骤2.2.1:将用户按时间戳升序排序的情报整编序列表示为,其中k为序列长度,使用情报编码器获取这些情报的表示{e1,e2,...,ek};
28、步骤2.2.2:计算用户的短期偏好表示,计算方法如下:
29、it=σ(wi[ht-1,et]+bi), (1)
30、ft=σ(wf[ht-1,et]+bf), (2)
31、ot=σ(wo[ht-1,et]+bo), (3)
32、ct=ft⊙ct-1+it⊙tanh(wc[ht-1,et]+bc), (4)
33、ht=ot⊙tanh(ct) (5)
34、其中,σ是sigmod激活函数,⊙是逐项相乘,wi、wf和wc是lstm网络的权重矩阵参数,bi、bf和bc是对应的偏置项参数,it、ft和ot分别表示输入门、遗忘门和输出门在当前时刻的激活值,ct表示当前时刻的细胞状态,ht表示当前时刻的隐藏状态,用户短期偏好表示是lstm网络的最后一个隐藏状态,即us=hk;
35、步骤2.3:将用户的长期偏好表示ul作为lstm网络的初始状态,最后得到的lstm网络最后一个隐藏状态作为用户的长短期偏好表示u;
36、步骤3:针对给定的候选情报,计算推荐分数,将用户的长短期偏好表示为u,将候选情报表示为ex,则用户点击该情报的预测分数为s(u,cx)=utex,其中,t是转置操作。
37、有益效果
38、与现有技术相比,本发明方法具有以下优点:1、更准确的情报表示:本发明结合情报标题、情报来源和情报摘要等多种信息,并根据它们各自的特点分别采用多头自注意力网络和id嵌入方法得到相应的表示,能够更为准确地表示情报内容,从而提高推荐结果的准确性;2、更准确的用户表示:本发明采用了一种用户长短期偏好表示方法,充分考虑了用户兴趣的多样性和变化性,有助于生成更符合用户需求的推荐结果,提高用户满意度;以及3、更强的适应性:利用lstm网络与基于id嵌入的方法,本发明提出的推荐方法能够在不同场景和用户行为变化下保持较高的推荐性能,从而增强推荐系统的适应性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!