基于视频小样本的瞬时目标识别方法与流程
本发明属于人工智能技术目标识别领域,具体涉及一种基于视频小样本的瞬时目标识别方法。
背景技术:
1、近年来,高速摄像机在科研,军事测试以及工业生产评估等领域的应用逐渐普及,相比起一般摄像机每秒拍摄二十四帧左右的效率,高速摄像机每秒则可以达到一千至一万帧,某些军方专用的高速摄像机甚至可以达到每秒一百万至一千万帧,帧数越高,在拍摄高速运动物体的运动轨迹时,更利于捕捉现实生活中人类肉眼无法看清的瞬间动态过程,因此高速摄像机就可以实现在极短时间内对高速目标的快速、多次采样。相比之下,高速摄像机的优势显而易见,特别是在军事领域,对于捕捉一些出现在摄像画面中的低空快、隐、小目标,都可以通过高速摄像机拍摄之后进一步利用目标识别算法来实现对捕捉目标的告警提示。随着人工智能深度学习的大规模发展与应用,依赖于大量标签数据训练的有监督学习在视频目标识别领域被广泛应用,例如fast-rcnn、yolo系列等深度学习模型,都取得了显著的成就。但在军事领域,由于行业特殊性,往往不能获取到足够数量的带标签数据来支撑深度学习神经网络模型的训练,同时在军事领域对于目标识别并告警的需求通常需要具备较强时效性,有时甚至是毫秒级别的瞬时目标识别任务,目前的目标识别方法大部分都是基于极大数据样本量,但在军事领域大多采用帧间差分法、背景差分法等方法对目标进行识别,此类方法的技术要点是提取目标轮廓特征,但其受背景环境影响较大,且往往无法适应动态背景的目标识别,在真实应用场景中的适应性及鲁棒性较差。本专利提出的基于少量标签视频样本的小样本学习及瞬时目标识别方法可以针对性地兼容解决样本量以及适应性、鲁棒性问题,因此,一种可以基于少量标签视频样本的小样本学习及瞬时目标识别方法是解决人工智能在某些军事任务上不能真正发挥作用的问题关键之一。
技术实现思路
1、本技术的发明目的是针对上述的现有技术问题,而提供一种基于视频小样本的瞬时目标识别方法。本技术针对小样本视频的瞬时目标识别与告警可获得良好的算法性能,实现了基于单视频小样本的目标数据集扩充,基于算法并行调用的瞬时目标识别,提高了算法泛化性以及目标告警提示的时效性。
2、为实现上述目的,本发明采用以下技术方案:
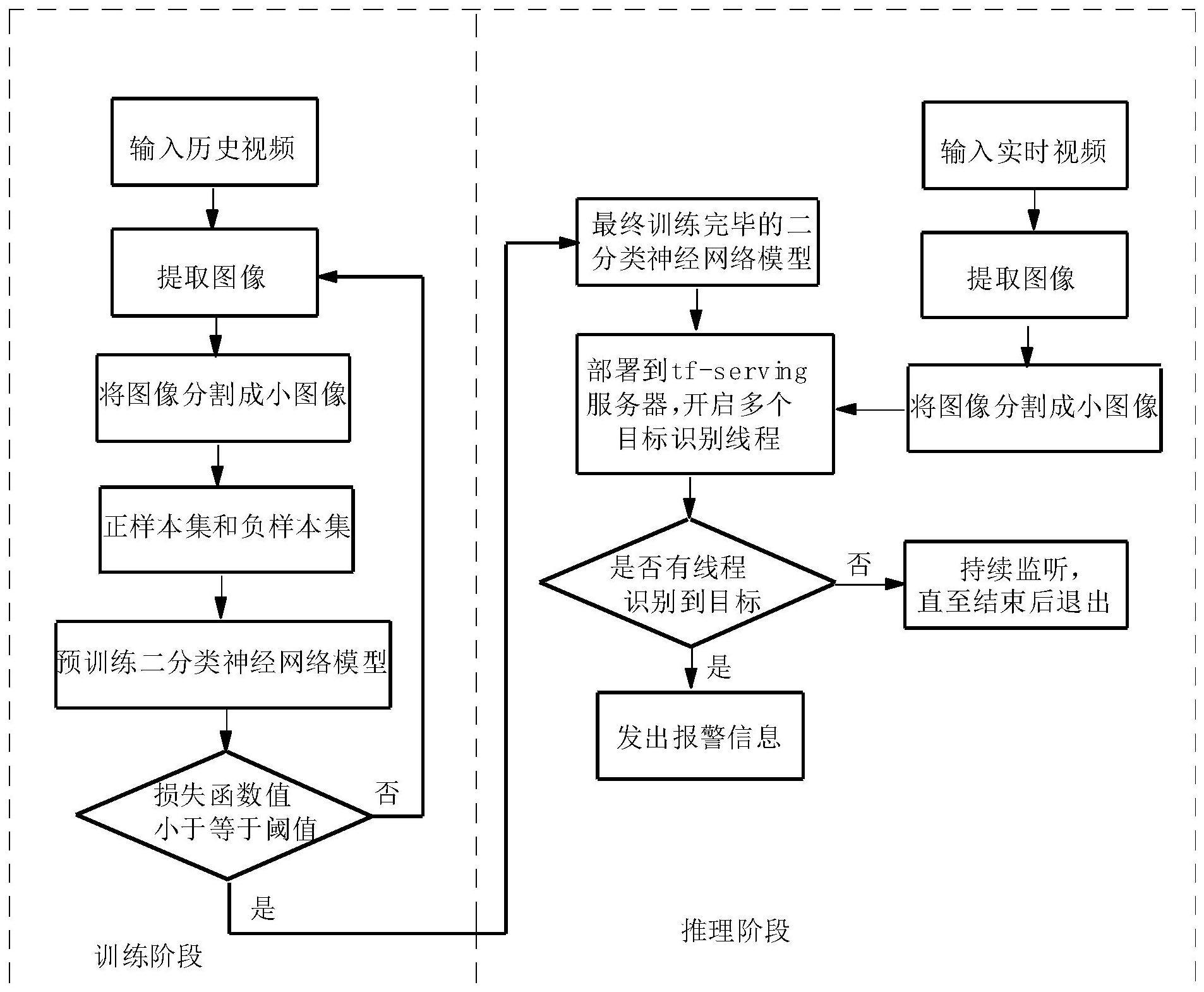
3、本发明的一种基于视频小样本的瞬时目标识别方法,其中:它包括以下步骤:
4、(一)、从包含目标的一个历史视频样本中提取出至少125帧样本的连续图像信息;
5、(二)、根据上述每帧图像信息中所包含的目标像素占整张图像像素的比例,设计滑窗的大小,保证目标在滑窗内是完整的,根据滑窗的大小,将上述每帧样本的连续图像分别分割成n个相同的小图像;
6、(三)、根据步骤(二)分割出的小图像,将上述包含目标的小图像列入正样本集,将上述不包含目标的小图像列入负样本集,正样本集和负样本集共同形成供神经网络训练的目标数据集;
7、(四)、将步骤(三)的正样本集进行扩充,使得正样本集的数量与负样本集的数量的比例至少为2:3,将负样本集和扩充后的正样本集共同形成供神经网络训练的目标数据集,将上述目标数据集输入到二分类神经网络模型中进行预训练,调整二分类神经网络模型的权重参数,当二分类神经网络模型的损失函数值大于阈值时,重复步骤(一),采取增大上述帧样本的方式继续训练二分类神经网络模型,同时迭代计算二分类神经网络模型的损失函数值;当二分类神经网络模型的损失函数值小于或等于阈值时,证明二分类神经网络模型达到了拟合状态,保存此时对应的二分类神经网络模型的权重参数,将当前的二分类神经网络模型作为最终的二分类神经网络模型;
8、(五)、将最终的二分类神经网络模型部署到tf-serving服务器中,并行开启多个目标识别线程,每个目标识别线程部署一个二分类神经网络模型;
9、(六)、从实时视频信号中提取出一帧图像信息,利用步骤(二)的滑窗尺寸,将上述一帧图像信息分割成n个小图像,将上述n个小图像分别分配给多个目标识别线程的二分类神经网络模型进行图像分类,一旦其中二个或二个以上的目标识别线程中的二分类神经网络模型发出正样本信号,或者其中一个目标识别线程中的二分类神经网络模型发出二个或二个以上的正样本信号,即刻进行目标报警;否则,持续监听直至结束后退出。
10、本发明的一种基于视频小样本的瞬时目标识别方法,其中:在步骤(二)和步骤(六)中,用以下步骤对每一帧图像进行分割:
11、(a)、将目标框定在一个矩形中,上述矩形像素大小为w×h,设定滑窗的长为w′≈w+ξ,宽为h′≈h+ξ,其中ξ设定为5个像素;
12、(b)、取出每一帧图像,根据上述滑窗尺寸和设定的相邻小图像之间的重叠率(iou),重叠率为相邻小图像之间的重叠比例,将每一帧图像从上到下和从左到右分割并保存成总数为n个相同尺寸大小的小图像样本pi,形成样本集p={p1,p2......pn};
13、用公式(1)表示
14、n=(w*h)/(w’*h’*iou2)-----公式(1)
15、其中:w’为滑窗的宽度;h’为滑窗的长度;iou为重叠率;w为每帧图像的宽度;h为每帧图像的长度;n为每帧图像分割成的小图像的总数。
16、本发明的一种基于视频小样本的瞬时目标识别方法,其中:在对二分类神经网络模型进行训练时,输入步骤(四)的负样本集和扩充后的正样本集,输出为1或0,1表示正样本,0表示负样本;在步骤(六)时,向最终的二分类神经网络模型输入用实时视频信号分割的n个小图像,当最终的二分类神经网络模型输出为1时,目标识别线程中的二分类神经网络模型发出正样本信号。
17、本发明的一种基于视频小样本的瞬时目标识别方法,其中:在步骤(一)和步骤(六)中,用opencv工具库提取并保存连续图像信息。
18、本发明的一种基于视频小样本的瞬时目标识别方法,其中:所述多个目标识别线程为至少2个以上的目标识别线程。
19、本发明的一种基于视频小样本的瞬时目标识别方法,其中:在步骤(三)中,所述阈值为10-3。
20、本发明的一种基于视频小样本的瞬时目标识别方法,其中:所述重叠率为0.5-0.8。
21、本发明的一种基于视频小样本的瞬时目标识别方法,其中:在步骤(四)中,所述正样本集扩充包括:旋转、缩放、平移变换、高斯模糊或运动模糊处理。
22、本发明的一种基于视频小样本的瞬时目标识别方法,其中:所述二分类神经网络为resnet50,二分类神经网络包含:输入层、池化层、卷积层、全连接层、分类层和输出层。
23、本发明的一种基于视频小样本的瞬时目标识别方法,其中:所述正样本集为包含目标的小图像,该小图像至少包括5%的完整小图像。
24、有益效果
25、本发明的基于视频小样本的瞬时目标识别方法与传统的目标识别方法相比,具有以下优点:
26、1、传统视频目标检测识别模型需要依赖大量数据集进行深度学习模型的训练,而本专利提出的基于视频小样本的目标分类模型只需要获取很少甚至是单一视频样本,进一步只针对目标图像采用数据增强等样本扩充方法,可以大大降低背景噪声对于模型准确率的影响,同时有效解决军事领域可供训练的数据样本有限的瓶颈问题;
27、2、基于深度学习的目标检测模型往往网络结构复杂,利用深度学习目标分类模型替换目标检测模型可以有效降低计算难度,将解决问题的途径从原本的较为复杂的回归问题降低到简单的分类问题,有效解决目标检测算法时间复杂度、空间复杂度高,算法效率欠佳的问题;
28、3、需要通过视频检测并告警的目标往往体积小或速度快,可能在画面中也转瞬即逝,本专利提出的利用tf-serving部署多线程算法识别程序相比以往的单线程算法识别,有效增强目标检测的时效性,单线程只用处理原本十分之一的数据量,大大降低模型推理时间,最后设置多个线程返回值为1再触发告警有效降低了漏检、误检率,对于提高算法鲁棒性有显著效果。
- 还没有人留言评论。精彩留言会获得点赞!